Far more important is instant feedback and that’s getting worse all the time: with lisp, smalltalk, Delphi, forth things were instant. With typescript or rust etc, if the project is larger than hello world, the feedback is well, far from instant. Bret victor talked about feedback, not necessarily visual programming and for some reason we are making things worse instead of better. When I show a Common Lisp dev session to young people, they think I am somehow cheating. I am, because I am not using the garbage people produce now and we are always faster (sbcl is incredible; sure you can do less latency and more performance with rust or c but then you don’t have the debugger and feedback while it takes a lot more code aka bugs and work), less bugs and not depressed while at work. We also don’t have to hire ‘devops’ to waste our profits; I like profits and I like not needing VCs.
The fundamental problem in visual programming is that it limits you to geometry (practically to 2D euclidian space). Most non-trivial programming problems are spaghetti by nature in such spaces.
That is not a problem, and for sure not a fundamental one. The textual representation is very limited, it's actually 1D with a line breaks helping us read it. 2D gives a lot more possibilities of organising code similar to how we draw diagrams on a whiteboard.
Power of text or other symbols is that they aren't spatially bounded. That's why it works even in "1D".
There are probably some possible usability gains from adding dimensions. E.g. node-type "programming" in Blender is quite nice. But for general purpose progamming it's hard to see how we'd get rid of symbolic representation.
Specifically, textual programs use symbols to build a graph of references between computations, where the average visual language tries to use explicit lines between blocks. But the reference graphs of non-trivial programs are often decidedly non-planar, which only becomes a problem when you try to lay them out on a plane.
Why does laying out code on a line not cause a problem with spatial reasoning but a plane would? Are we somehow incapable of applying spatial abstractions when we move up into a higher dimension than 1?
Text doesn't use spatial abstractions.
The problem with spatializing complex relationsips becomes very apparent when one tries to lay out graphs (as in nodes-and-edges) graphically. Unless the relationships are somehow greatly restricted (e.g. a family tree), the layouts become a total mess, as the connectedness of the nodes can't be mapped to distances and the edges by necessity have to make a lot of crossings on top of each other.
I think you are limiting visual programming to some sort of a single graph that has everything together, but similar to how we split code into modules and files, visual systems can do the same, here's an example I keep showing in this thread of a visual programming system that works pretty well: https://youtu.be/CTZeKQ1ypPI?si=DX3bQSiDLew5wvqF&t=953
The spatial reasoning on reading code does not happen on the dimensions of the literal text, at least not only on these. It happens in how we interpret the code and build relations in our minds while doing so. So I think that the problem is not about the spatial reasoning of what we literally see per se, but if the specific representation helps in something. I like visual representations for the explanatory value they can offer, but if one tries to work rigorously on a kind of spatial algebra of these, then this explanatory power can be lost after some point of complexity. I guess there may be contexts where a visual language may be working well. But in the contexts I have encountered I have not found them helpful. If anything, the more complex a problem is, the more cluttered the visual language form ends up being, and feels overloading my visual memory. I do not think it is a geometric feature or advantage per se, but about how brains of some people work. I like visual representations and I am in general a quite visual thinker, but I do not want to see all these miniscule details in there, I want to them to represent what I want to understand. Text, on the other hand, serves better as a form of (human-related) compression of information, imo, which makes it better for working on these details there.
If anything, the more complex a problem is, the more cluttered the visual language form ends up being, and feels overloading my visual memory
I feel like you are more concerned about implementation than the idea itself. For me it's the opposite - I find it's easier to understand small pieces of text, but making sense of hundreds of 1k lines files is super hard.
Visual programming in my understanding should allow us to "zoom" in and out on any level and have a digestible overview of the system.
Here is an example of visual-first platform that I know is used for large industrial systems, and it allows viewing different flows separately and zooming into details of any specific piece of logic, I think it's a good example of how visual programming can be: https://youtu.be/CTZeKQ1ypPI?si=DX3bQSiDLew5wvqF&t=953
Writing is based on speech, which is one-dimensional. Most programming is actually already highly two-dimensional thanks to its heavy line orientation.
But most visual programming isn't trying to be a kind of "2D orthography" for language, it is trying to be a "picture" of a physical mechanism.
As jampekka put it, text isn't trying to use spatial abstractions, it's using the (arguably more powerful) abstraction of named values/computations. Hard to think about? Yes, there's a learning curve to say the least. But it seems to be worth it for a lot of cases.
So why not do 2D visual programming with access to symbols that are not spatially bound? Is there any reason why a 2D plane forces the programmer to think in terms of a plane that doesn't also apply to a 1D line of text?
It seems to me that reducing the frequency with which programmers have to drop into non-spatial symbols would be beneficial even if there are still use cases where they have to.
The problem with visual programming is it abandons the fundamental principle of language, whereby to connect two objects it is necessary only to speak their names, in favor of the principle of physicality, whereby to connect two objects it is necessary that they be in physical contact, ie. to be joined by a wire.
only to speak their names
in physical contact, ie. to be joined by a wire.
I don't really see how that is different, in any given language the name alone is not enough to refer to the object, in general case you have to import it. For me the process of name resolution and connecting by a wire is the same thing with different representations.
Is that an inherent problem of the medium or the result of people trying too hard to completely change the paradigm?
to connect two objects it is necessary that they be in physical contact
I can imagine a way to connect an object to another by selecting the latter's name from a drop-down menu of defined objects. A visual equivalent of a function call.
With text/symbolic representation I can describe any amount of dimensions in a super dense way and physicist/mathematicians are doing that, software devs as well because most software is multidimensional.
You do have graphs in mathematics but all the maths I see is about describing reality in really dense couple of symbols, compressing as much of the universe as possible to something like E=mc^2.
Graphical programming representations go the other way - it actually tries to use more bits to describe something that can be described in less bits - many more bits.
But program code is 2D as well. And quite limited 2D, with 80 characters width max (or similar, but never unlimited).
Code is 1d with named links.
Visual languages trade named links for global wiring, which is very cluttered for serious problem solving.
Code is not 1d, a single if() already creates another line that makes it 2d
How is `if` related with creating a new line? And how does new line make something 2D? If code was 2D you could write code anywhere in your document without juggling around spaces and newlines
Visual languages trade named links for global wiring
Existing visual programming langs can definitely do "named links". A lot support named function-like blocks which are another form of avoiding wires.
which is very cluttered for serious problem solving
This clutter is also problematic in textual programming, and is the reason abstractions and programming structures are used. Perhaps the hint here is that we need better ways of representing abstraction in visual programming.
The fact you can give things names means that there is rarely a need to follow the edges so the visualization is much less cluttered
Nah, code is 1D with line breaks for visual comfort
You could argue it's 1d, actually, since sequence is fundamental, not positioning on the x axis.
At any rate it's (mostly+) categorically different from what visual programming attempts. Code must be read, comprehended, and a mental model built. Visual programming is designed to give a gestalt spatial intuition for code structure -- a different kind of comprehension.
+Indent and spacing between functions/methods does count as a tiny bit of visual programming IMO
I would vouch a different take, visual programming makes it quite clear the mess of programs some people create when they don't follow modular programming.
Complex flows can be packaged into functions and modules representations, instead of dummping everything into a single screen.
Much like designing Integrated Circuit chips, vs. only doing basic breadboard-ing.
The spatial (usually largely 2D in IC) constraints are a huge limitation for circuit design. I'm quite sure chips (or breadboards) wouldn't be designed like this if the physical world wouldn't force the geometry.
I meant more that the very concept of an IC is a good idea, and like a good abstraction in programming.
I think pjmlp was getting at is that when using visual programming, a lot of people seem to turn off (or not cultivate) the part of the thought process concerned with creating good abstractions, despite it at least being possible to do so.
Exactly, packaging transitors into IC Modules, so to speak.
Yes, very much so.
I got the Apple Vision Pro with the hope to tinker with such things. Is one more dimension enough to "unlock" visual programming? I don't know, and unfortunately not many seem interested in exploring it.
I don't think extra dimensions help. Even simple functions have easily tens of interconnected references and representing these spatially is gonna be a mess even in higher dimensions.
I personally wont ever be interested in VR until it has "generic computing" as a major feature.
like automatically creating a 3d world showing pipes as your internet connections, some kind of switches and buttons and things as every single thing you can do with your computer including complicated ass command line and GUI windows.
And all the tools necessary to reduce or increase the complexity of it as I see fit as a user
Mapping to a plane doesn't help you understand how state changes occur over time, or what is the over-all state of the state-machine is.
The only time I've seen visual programming work is when the state is immutable. How-ever it requires a major paradigm shift how one design, develop and test their programs.
it's pretty basic topology - embedding versus immersion. you cannot embed anything but the simplest software in a 2d plane. you end up having to endlessly try to structure things to minimize line crossings, make multiple diagrams of the same code to capture different aspects of it, or otherwise perform perversions just so it fits on a page.
And I live through this. most of my early career was DoD related in the early '90s, when things like functional analysis was all the rage. endless pages of circles and lines which were more confusing than helpful, and certainly didn't actually capture what the software had to do. Bever again.
I agree with you how-ever the elephant in the room is a image or topology doesn't predicate anything (A predicate is seen as a property that a subject has or is characterized by). That is the main delineation between them, and why SPO (subject predicate object) is used universality by all modern languages - abet some have different svo ordering but I digress.
The next major draw-back with visual programming is they don't explicitly convey time. You have to infer it via lines or sequence of diagram blocks. Were in a programming language you have sequential order of execution eg. left to right, top to down of of the program flow and stage change. If you attempt to achieve the same with a stateless event driven bus or message queue, you end up having to embed the sequential control flow into the event payload itself.
And yet IDA and Ghidra use that same 2d representation structure for basic blocks (e.g. https://byte.how/images/ghidra-overview/graph-edges.png ) showing code flow between the blocks
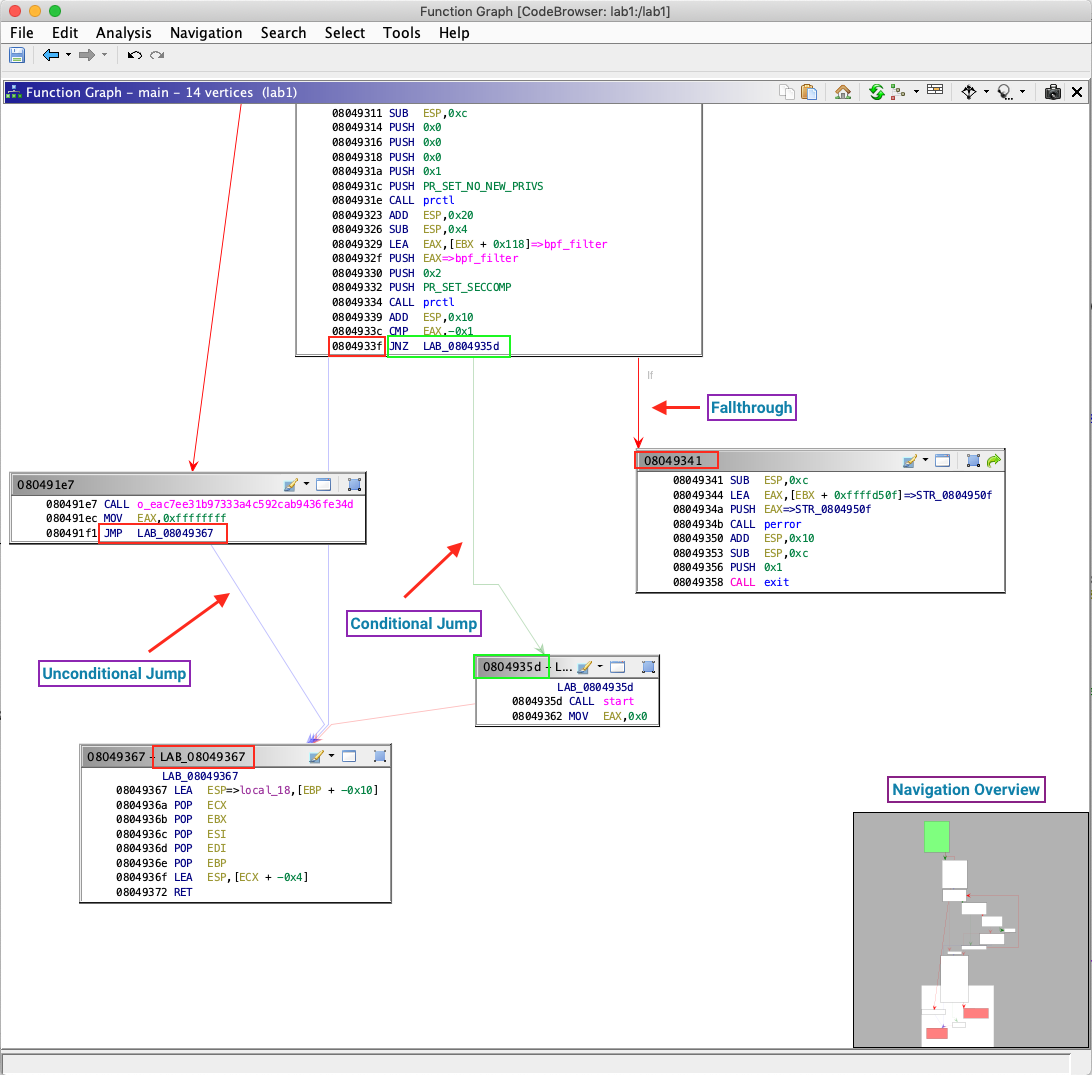{kind=link}
I have had better-than-average success representing the high level sequence of computer-y actions using sequence diagrams, and suspect strongly my audience would not have the same comprehension if I used pseudocode or python or C++
Where I think the anti-visual programming audience and I can agree is the idea of a standard library, since a bunch of diagrams showing a "length" message being sent to a String object is for sure the wrong level of abstraction. In that way, I'd guess the DSL crowd would pipe up and say that is the same problem a DSL is trying to solve: express the code flow in terms of business nouns and verbs, and let the underlying framework deal with String.length nonsense
I've seen a hybrid approach to this in a few testing frameworks, such as Robot Framework <https://robotframework.org/robotframework/latest/RobotFramew...>
The reason it works out so well (contrary to many people's intuition) is that most programming is done in structured languages or in a structured-style these days. This significantly reduces the number of entry points (typically down to 1) for any block of code, though it can still have many exit points. Unless someone abuses something like Duff's device or uses goto's to jump into a block (and the language permits it), the flow diagrams like in the linked image end up being pretty tidy in practice.
By this logic its strictly better than a linear textual document, no? In a graph you can explicitly draw lines between connections.
Anyone who mentions visual scripting without mentioning the game industry just hasn't done enough research at all. Its actually a really elegant way to handle transforming data.
Look up Unreal blueprints, shader graphs, procedural model generation in blender or Houdini. Visual programming is already here and quite popular.
[post author] I am familiar with those and have used a couple. There are similar examples in music, where visual programming dominates.
The implied audience of this post (not clear) is people writing business applications, web dev, etc. The examples are picked to reflect what could be useful to those developers. In other words, all the examples you mentioned are great but they are not how a "software engineer in a software company" does their job.
game developers are definitely software engineers in software companies.
My experience is that the software engineers at game companies generally hate the visual programming tools. They want to work with code. It's the game designers who (sometimes) like using visual tools.
Some are bad but Blueprints is great. Main issue is they don't always play nice with text based coding tools.
And AI - which kind of changed the game in the recent years. A "blueprints copilot" akin to Github Copilot will be very difficult to create because there's no "blueprints text" to train an AI on. Nowadays in my hobby pet projects I find it easier to write C++ with copilot than Blueprints.
There's a JSON format of the blueprints that you can see when you copy/paste. Its just a bit ambiguous than the usual binary format. Its not an impossible problem at all.
Not an impossible problem only in theory. It's currently practically impossible and will take at least a year to solve if anybody starts to work on this at all.
Since my current project does involve wrangling AI to do stuff - forcing it to output a consistent, complete, large JSON with an exact specific format is very difficult and takes a lot of time (you won't be able to draw Blueprints line by line to show to the user that AI is processing). Definitely no autocomplete-like experiences maybe ever.
For example, look at the text representation of these 6 (!) nodes:
https://blueprintue.com/blueprint/yl8hd3-8/
It's enormous.
And the second even bigger problem: On forums and basically everywhere all users share screenshots with descriptions. There's not enough training data for anything meaningful.
I tried to force copilot/gpt to output even a small sample of copy-pastable blueprint and it just can't.
I spent about a year working with blueprints a while back and I found some things just really annoying. like making the execution line go backwards into the a previous block. if you do it straight there, it wont let you, if you use a single reroute note you get an ugly point, so you have to use two reroute nodes to get it to work properly and nicely. Also they don't have all the nodes you need so you end up having to write some new ones anyway
Of course, but you know what they're saying.
In other words, all the examples you mentioned are great but they are not how a "software engineer in a software company" does their job.
creating blueprints or max/msp programs is definitely software engineering, it requires you to think about correct abstractions, computations, data flow and storage, etc.
also, there's currently 398 Rust jobs worldwide advertised on linkedin, vs. 1473 for "unreal blueprints"
TBH I think Blueprints gets used because it is forced upon the UE developers.
Blueprints gets used because the only alternative in UE, writing decade-old paradigm C++ code with 2 decades old macro DSL on top of it, is a lot worse.
Unity has had multiple visual programming packages and people don't really care. Writing 2017 era C# paradigm code with an API resembling 2004 Macromedia Flash is not nearly as bad.
Unity has had multiple visual programming packages and people don't really care.
People cared enough for Unity to buy one and make it official but Unity doesn't care so it mostly just rots.
Its important to note that some successful Unity games were still made with visual scripting tools e.g. Hollow Knight used Playmaker.
I used blueprint's predecessor 'kismet' quite extensively. I absolutely hated it. Give me unrealscript any day. Blueprint is popular because that's all you have. They removed unrealscript. To do anything even slightly complex you have to use C++ now.
I wonder the sweet point between BP and C++. One of my friends is making a commercial indie game in UE and he is doing everything in BP because he is an artist, so C++ is particularly daunting for him. He did complain about the spaghettis hell he eventually came upon, without anyway to solve it, but from the number of wishlistings (targeting 10K), I'd say it is probably going to be a successful game, judging by first indie game standard.
As someone who works for games, I think the biggest problem of node-based systems is... they're all different (in terms of UI/UX).
Unreal blueprints, Substance Designer, Houdini, Blender's geometry node, Unity shader nodes... they all look different and act differently. Different shortcuts and gestures. Different window/panel management.
Different programming languages have different syntax rules and libraries, of course. But at least they're all manipulated with one single interface, which is your editor. If you use vim binding, you don't need to worry about "what pressing K does". It moves the cursor down for all the languages.
People who spent X hours customizing their vim/emacs will benefit from them no matter what language they use next. I spent a lot of time customizing my Houdini keybindings and scripts, and this effort will be thrown out the window if I later switch to Blender.
You know, this is actually really insightful. A standard graph format that all these tools could import/export to could lead to a lot more reusable tooling.
The incentives aren't quite there at the moment but maybe someone like Microsoft or Jetbrains takes a stab at it.
I've been using ComfyUI recently to manage complex image diffusion workflows, and I had no idea it was inherited from much older shader editors and vfx. It's a shame we can end up using a tool for years without knowing anything about its predecessors.
One could even go further and expand this to the players themselves, as there are certain games that might be viewed as visual programming tools. Factorio is a great example, as, conceptually speaking, there isn't much of a difference between a player optimising their resource flow in the game vs a developer managing the data flow in a State Machine.
I am surprised I have not seen LabView mentioned in this thread. It is arguably one of the most popular visual programming languages after Excel and I absolutely hate it.
It has all the downsides of visual programming that the author mentions. The visual aspect of it makes it so hard to understand the flow of control. There is no clear left to right or top to bottom way of chronologically reading a program.
I still have to find somebody who worked with LabView that does not hate it.
It is a total abomination.
I don't hate it, I feel it's pretty good for talking to hardware, (understanding) multi-threading, agent oriented programming, message cues, etc.
It's also fairly good for making money: the oil and gass industry seems to like using it (note: n = 1, I only did one oil n gas project with it).
How does version control work with Labview?
Also, since you;ve done only one project with it, how hard was it to pick it up and learn?
How does version control work with Labview?
Labview does have diff and merge tools. It feels kind of clunky in practice, kind of like diffing/merging MS Office files. In my experience people think of versions of LabView code as immutable snapshots along a linear timeline and don't really expect to have merge commits. Code versions may as well be stored as separate folders with revision numbers. The mindset is more hardware-centric; e.g., when rewiring a physical data acquisition system, reverting a change just means doing the work over again differently. So LabView's deficiencies in version control don't stand out as much as they would in pure software development.
https://www.ni.com/docs/en-US/bundle/labview/page/comparing-...
As someone who used to use (and hate) LabVIEW, a lot of my hatred towards it was directed at the truly abysmal IDE. The actual language itself has a lot of neat features, especially for data visualization and highly parallel tasks.
I agree.
LabView’s shining examples would be trivial Python scripts (aside from the GUI tweaking). However, it’s runtime interactive 2D graph/plot widgets are unequaled.
As soon as a “function” becomes slightly non trivial, the graphical nature makes it hard to follow.
Structured data with the “weak typedef” is a minefield.
A simple program to solve a quadratic equation becomes an absolute mess when laid out graphically. Textually, it would be a simple 5-6 line function that is easy to read.
Source control is also a mess. How does one “diff” a LabView program?
Python's equivalent of LabView would be Airflow. Both solve the same CS problem (even though the applications are very different).
Airflow it almost universally famous for being a confusing, hard to grasp framework. But nobody can actually point to anything better. But yeah, it's incomparably better than LabView, it's not even on the same race.
When I had some customers working with it a few years ago, they were trying to roll out a visual diff tool that would make source control possible.
I don't know if they ever really delivered anything or not. That system is such an abomination it drove me nuts dealing with it, and dealing with scientists who honestly believed it was the future of software engineering and all the rest of us were idiots for using C++.
The VIs are really nice, when you're connecting them up to a piece of measurement hardware to collect data the system makes sense for that. Anything further and it's utter garbage.
How does one “diff” a LabView program?
Take a look at FME, another visual 'programming language'. They've done a lot of work with their git integration, including diffing and handling merge conflicts.
https://docs.safe.com/fme/html/FME-Form-Documentation/FME-Fo...
Source control is also a mess. How does one “diff” a LabView program?
With LabVIEW, I'm not sure you can. But in general, there are two ways: either by doing a comparison of the underlying graphs of each function, or working on the stored textual representations of the topologically sorted graphs and comparing those. On a wider view, in general, as different versions of any code are nodes in a graph, a visual versioning system makes sense.
Most industrial automation programming happens in an environment similar to LabView, if not LabView itself. DeltaV, Siemens, Allen-Bradley, etc. Most industrial facilities are absolutely full of them with text-based code being likely a small minority for anything higher level than the firmware of individual PLCs and such.
A lot of these environments inherit a visual presentation style (ladder logic) that comes from the pre-computer era, and that works extremely well for electrical schematics when conveying asynchronous conditional behaviors to anyone, even people without much of a math background. There's a lot of more advanced functions these days that you write in plain C code in a hierarchical block, mostly for things like motor control.
I like function block on Schneider platform for Process control with more analog values than Boolean. It visualizes the inputs, control loop, and output nicely.
Numeric values in ladder feels a bit kludgey
These are standardized IEC 61131-3 languages https://en.wikipedia.org/wiki/IEC_61131-3
Ladder, SFC and FBD are all graphical languages used to program PLC's. Ladder is directly based on electrical ladder schematics and common in the USA. The idea was electricians and plant technicians who understood ladder schematics could now program and troubleshoot industrial computers. SFC and FBD were more common in Europe but nowadays you mostly see Structured Text, a Pascal dialect (usually with bolted on vendor OOP lunacy.)
I will admit that for some programs, Ladder is fantastic. Of course ladder can be turned into horrid spaghetti if the programmer doesn't split up the logic properly
And Simulink. I lost years in grad school to Simulink, but it is very nice for complex state machine programming. It’s self documenting in that way. Just hope you don’t have to debug it because that’s a special hell.
I quite like Simulink because it's designed for simulating physical systems which are naturally quite visual and bidirectional. Like circuit diagrams, pneumatics, engines, etc. You aren't writing for loops.
Also it is actually visually decent unlike LabVIEW which looks like it was drawn by someone who discovered MS Paint EGA edition.
Simulink is based on the block diagram notation used in control theory for decades earlier - before personal computers and workstations. The notation is rigorous enough you can pretty much pick up a book like the old Electro-Craft motor handbook (DC Motors Speed Controls Servo Systems), enter the diagrams into Simulink, and run them. With analogous allowances to how you would enter an old schematic into a SPICE simulator.
LabView was significantly more sui generis and originated on Macintosh about a decade earlier. I don't hate it but it really predates a lot of more recent user experience conventions.
I think the whole flow concept is really only good for media pipelines and such.
In mathematics, everything exists at once just like real life.
In most programming languages, things happen in explicit discrete steps which makes things a lot easier, and most node based systems don't have that property.
I greatly prefer block based programming where you're dragging rules and command blocks that work like traditional programming, but with higher level functions, ease of use on mobile, and no need to memorize all the API call names just for a one off tasks.
What would be useful is a data flow representation of the call stack of a piece of code. Generated from source, and then brought back from the GUI into source.
This is exactly why a visual representation of code can be useful for analyzing certain things, but will rarely be the best (or even preferred) way to write code.
I think a happy medium would be an environment where you could easily switch between "code" and "visual" view, and maybe even make changes within each, but I suspect developers will stick with "code" view most of the time.
Also, from the article: > Developers say they want "visual programming"
I certainly don't. What I do want is an IDE which has a better view into my entire project, including all the files, images, DB, etc., so it can make much better informed suggestions. Kind of like JetBrains on steroids, but with better built-in error checking and autocomplete suggestions. I want the ability to move a chunk of code somewhere else, and have the IDE warn me (or even fix the problem) when the code I move now references out-of-scope variables. In short, I want the IDE to handle most of the grunt work, so I can concentrate on the bigger picture.
Most of this isn't visual "programming" just good explanatory diagrams. I think it gets to a core issue which is a dichotomy between:
- trying to understand existing programs - for which visuals are wanted by most but they usually need concious input to be their best
- programming (creating new code) itself - where the efficiency of the keyboard (with its 1d input that goes straight to spaghetti code) has never been replaced by visual (mouse based?) methods other than for very simple (click and connect) type models
You are right. The diagrams are used as explanations not as the source of the program. But wouldn't it be neat if when you sketch out the state transition in a diagram (how I think about the state transitions), _that diagram_ was the source of truth for the program?
That is the implied point: let's go to places where we already draw diagrams and check if we can elevate them into the program
This can be really tricky to do. I reached the limit of my brain's working capacity designing a priority inheritance system, and sketched the state machine out in a dot file, visualized with graphviz - this worked really well for reasoning through the correctness of the algorithm and explaining it to others. I tried to structure the implementation code to match it and I was able to get pretty close; but the actual states were a bunch of bit-packing and duplicated control flow to get optimal assembly output for the hottest paths. Each one of those changes was easy to reason about as an isolated correct transformation of the original structure in code, but would have been a mess visually.
That sounds super interesting!
Did I understand correctly that the additional complexity came because you needed to emit optimal assembly? Or was implementing the logic from the state machine complicated enough?
Designing the state machine was hard. The implementation of that state machine was not that bad, because I'd spent so much time thinking through the algorithm that I was able to implement it pretty quickly. The implementation difficulty was optimizing the uncontended case - I had to do things like duplicate code outside the main CAS loop to allow that to be inlined separately from the main body, structure functions so that the unlock path used the same or fewer stack bytes than the lock path, etc. Each of those code changes were straightforward but if I had faithfully copied all those the little tweaks into the state machine diagram, it would be so obfuscated that it'd hide any bugs in the actual core logic.
So I decided that the diagram was most useful for someone looking to understand the algorithm in the abstract, and only once they had been convinced of its correctness should they proceed to review the implementation code. The code was a terrible way to understand the algorithm, and the visualization was a terrible way to understand the implementation.
From what I've seen when code is generated from formal specs it ends up being inflexible. However, do you think it would be valuable to be able to verify an implementation based on a formal spec?
That last point is super interesting: these diagrams never tell you much about the implementation or how it would perform.
You might be interested in:
https://schematix.com/video/depmap
I'm the founder. It's a tool for interacting with deployment diagrams like you mentioned in your article.
We have customers who also model state machines and generate code from the diagrams.
> Schematix provides diagrams as a dynamic resource using its API. They aren't images you export, they don't end up in My Documents. This isn't Corel Draw. In Schematix, you specify part of your model using a graph expression, and the system automatically generates a diagram of the objects and relations that match. As your Schematix model changes, the results of the graph expression may change, and thus the visual diagram will also change. But the system doesn't need you to point and click for it. Once you've told it what you want, you're done.
What an interesting tool! It's rare to see robust data models, flexible UX abstractions for dev + ops, lightweight process notations, programmatic inventory, live API dashboards and a multi-browser web client in one product.
Do you have commercial competitors? If not, it might be worth doing a blog post and/or Show HN on OSS tooling (e.g Netbox inventory, netflow analysis of service dependencies) which offer a subset of Schematix, to help potential customers understand what you've accomplished.
Operational risk management consultants in the finance sector could benefit from Schematix, https://www.mckinsey.com/capabilities/risk-and-resilience/ou.... Lots of complexity and data for neutral visualization tooling.
Schematix is somewhat unique. Direct competitors? -- not exactly, but IT asset managers, DCIM, BC/DR tools, and CMDBs are all competitors to some degree.
Some of our best users are professional consultants who use us for a project which often introduces us to a new customer.
A Show HN would certainly be in order. Thanks for the thoughts!
I forget its name, but there was an IBM graphical tool , with which you create UML diagrams and it in turn created code (Java IIRRC).
The intermediate representation was in sexp !
Yes, in order to be visual coding (or better yet specification) it needs to be executable in it's native form, or maybe a very direct translation.
The concept of an executable specification first came to my attention in IEC 61499 the standard for Distributed Automation. First published in 2005 it was way, way ahead of it's time, so far ahead it is still gaining traction today.
Shout out to anyone reading who was involved in the creation of IEC 61499 in 2005, it was a stroke of genius, and for it's time, orders of magnitude more so. It is also worth a look just to prompt thinking for any one involved in distributed systems of any kind.
Initially I thought there was no way you could have such a thing as an executable specification, but then, over many years I evolved to a place where I could generically create an arbitrary executable specification for state based behavior (see my other post this topic).
I believe I have found the best achievable practice to allow defining behaviors for mission/safety critical functionality, while avoiding implicit state.
One reason is because we think that other, more inexperienced, programmers might have an easier time with visual programming. If only code wasn't as scary! If only it was visual! Excel Formula is the most popular programming language by a few orders of magnitude and it can look like this:
=INDEX(A1:A4,SMALL(IF(Active[A1:A4]=E$1,ROW(A1:A4)-1),ROW(1:1)),2)
Ahem. Excel is one of the most visual programming environment out there. Everything is laid out on giant 2d grids you can zoom in and out. You can paint arrows that give you the whole dependency tree. You can select, copy, paste, delete code with the mouse only. You can color things to help you categorize which cell does what. You can create user inputs, charts and pivot grids with clicks.
Excel could do this so much better though (and I think excel is the best candidate for visual scripting overhaul). The cell could have two parts; top parts is the function signature (other cells could reference by signature, or by cell number), bottom part is the code. Each cell is a function.
People put huge unreadable basic functions in that tiny box. It's such an obvious pain point, surprised it's never been addressed. Replace vba with c#, have a visual line linking cells to other cell references, bam million dollar product.
A basic problem I have, looking at an Excel spreadsheet, is I don't know which cells are calculated by a formula, which are constants.
Maybe it would be easier if the spreadsheet was divided into an upper part with only constant-cells and a lower part with only calculated values, would that help me?
A basic problem I have, looking at an Excel spreadsheet, is I don't know which cells are calculated by a formula, which are constants.
Use Ctrl-` (show formulas).
As a programmer who had used Excel for years, seeing my accountant start typing a formula, change sheets, select some cells, go back, repeat, was a learning process. I didn't even know you could do that, and also, I hated it. But it worked very well for him.
I've more recently been exposed to a few spreadsheets that are used to calculate quotes in major insurance businesses when I was asked to create an online process instead, replicating the questions and formula.
They're things of horrifying eldritch beauty. I seem to always find at least one error, and no one I'm allowed to talk to ever really knows how they work since they're built up over years. Those dependency arrows are a life saver.
I seem to always find at least one error
Every time I see so spreadsheet where the dependency is hard to track, I've found enough errors that the results were completely bogus.
Also every time, nobody cared.
You can paint arrows that give you the whole dependency tree.
Sorry, is that a manual process, or is there a option in Excel to show multi-ancestor dependencies?
I'm aware that you can double click to see a single cells inputs, but I want to go deeper.
You are right. You can see the data first, charts, even dependencies. And yet nobody is drawing `IF(ACTIVE[A1:A4]=E$1)`
Stil impossible to know what a Excel sheet does only by looking at it. The 2d grid obfucates the relationships between data.
Power BI does (almost) everything Excel does but better.
I have had to debug insane Excel sheets, which were used to generate C code, based on the geometric properties of an object.
Excel works very well for describing many, simple relationships. It totally falls apart the moment you have complex relationships, as they become mentally untraceable. Functions allow you to abstract away functionality, referencing cells does not.
I am pretty certain that Excel is one of the most misused tools and suffers the most from "I use it because I know it".
As someone with a hardware background, I'll throw in my $0.02. The schematic capture elements to connect up large blocks of HDL with a ton of I/O going everywhere are one of the few applications of visual programming that I like. Once you get past defining the block behaviors in HDL, instantiation can become tedious and error-prone in text, since the tools all kinda suck with very little hinting or argument checking, and the modules can and regularly do have dozens of I/O arguments. Instead, it's often very easy to map the module inputs to schematic-level wires, particularly in situations where large buses can be combined into single fat lines, I/O types can be visually distinguished, etc. IDE keyboard shortcuts also make these signals easy to follow and trace as they pass through hierarchical organization of blocks, all the way down to transistor-level implementations in many cases.
I've also always had an admiration for the Falstad circuit simulation tool[0], as the only SPICE-like simulator that visually depicts magnitude of voltages and currents during simulation (and not just on graphs). I reach for it once in a while when I need to do something a bit bigger than I can trivially fit in my head, but not so complex that I feel compelled to fight a more powerful but significantly shittier to work with IDE to extract an answer.
Schematics work really well for capturing information that's independent of time, like physical connections or common simple functions (summers, comparators, etc). Diagrams with time included sacrifice a dimension to show sequential progress, which is fine for things that have very little changing state attached or where query/response is highly predictable. Sometimes, animation helps restore the lost dimension for systems with time-evolution. But beyond trivial things that fit on an A4 sheet, I'd rather represent time-evolution of system state with timing diagrams. I don't think there's many analogous situations in typical programming applications that call for timing diagrams, but they are absolutely foundational for digital logic applications and low-level hardware drivers.
"Schematics work really well for capturing information that's independent of time, .." This spells out what always irked me about graphical software.
There's no reason they can't instead be used to show how data transforms. The sort of 'flow wall' someone sees in a large industrial setting (think water/waste water treatment plants, power plants, chemical plants, etc) or process mockup diagrams for spreadsheet heavy modpacks (I'm looking at you GregTech New Horizons).
Data can instead be modeled as inputs which transform as they flow through a system, and possibly modify the system.
As much as I prefer to do everything in a text editor and use open-source EDA tools/linters/language servers, Xilinx's Vivado deserves major credit from me for its block editor, schematic view, and implementation view.
For complex tasks like connecting AXI, SoC, memory, and custom IP components together, things like bussed wires and ports, as well as GUI configurators, make the process of getting something up and running on a real FPGA board much easier and quicker than if I had to do it all manually (of course, after I can dump the Tcl trace and move all that automation into reproducible source scripts).
I believe the biggest advantage of the Vivado block editor is the "Run Block Automation" flow that can quickly handle a lot of the wire connections and instantiation of required IPs when integrating an SoC block with modules. I think it would be interesting to explore if this idea could be successfully translated to other styles of visual programming. For example, I could place and connect a few core components and let the tooling handle the rest for me.
Also, a free idea (or I don't know if it's out there yet): an open-source HDL/FPGA editor or editor extension with something like the Vivado block editor that works with all the open source EDA tools with all the same bells and whistles, including an IP library, programmable IP GUI configurators, bussed ports and connections, and block automation. You could even integrate different HDL front-ends as there are many more now than in the past. I know Icestudio is a thing, but that seems designed for educational use, which is also cool to see! I think a VSCode webview-based extension could be one easier way to prototype this.
Amazing, thank you for taking the time
The schematic capture elements to connect up large blocks of HDL with a ton of I/O going everywhere are one of the few applications of visual programming that I like.
Right. Trying to map lines of code to blocks 1 to 1 is a bad use of time. Humans seem to deal with text really well. The problem becomes when we have many systems talking to one another, skimming through text becomes far less effective. Being able to connect 'modules' or 'nodes' together visually(whatever those modules are) and rewire them seems to be a better idea.
For a different take that's not circuit-based, see how shader nodes are implemented in Blender. That's not (as far as I know a) a Turing complete language, but it gives one idea how you can connect 'nodes' together to perform complex calculations: https://renderguide.com/blender-shader-nodes-tutorial/
A more 'general purpose' example is the blueprint system from Unreal Engine. Again we have 'nodes' that you connect together, but you don't create those visually, you connect them to achieve the behavior you want: https://dev.epicgames.com/documentation/en-us/unreal-engine/...
I don't think there's many analogous situations in typical programming applications that call for timing diagrams
Not 'timing' per se (although those exist), but situations where you want to see changes over time across several systems are incredibly common, but existing tooling is pretty poor for that.
i remember using the falstad sim constantly at university a decade ago. super helpful and so much more intuitive than any spice thing. cool to see that it's still around and used
Developers say they want "visual programming", which makes you think "oh, let's replace if and for". But nobody ever made a flow chart to read for (i in 0..10) if even?(i) print(i).
I'm not convinced by this particular example. Wouldn't a visual programming language just represent the logic here as a pipeline connecting two more atomic operations: you'd have a visual representation where you pipe the (0..10) range through a function that filters for even values, and then pipe the result to a print function.
That's a good point. Functional programming is a much more appropriate foundation for visual coding. Not only because of functional operators in your example, but immutability and purity also makes things simpler when represented visually.
Circuit modeling (like in Max/MSP, Reaktor, Pd) is something that also works way better visually than imperative programming.
Dataflow paradigm
It is certainly possible and that is how most of these visual languages do it. But is that how _you_ want to program that logic?
That’s how Smalltalk does it. I believe Scheme family languages do it that way, use a generator and then filter and select. Self as well.
Or just a good visualization for list comprehension.
I do not think what they say is that it is hard to visualise it, but that it does not offer much utility to do so. A "for" loop like that is not that complicated to understand and visualising it externally does not offer much. The examples the article gives is about more abstract and general overviews of higher level aspects of a codebase or system. Or to explain some concept that may be less intuitive or complicated. In general less about trying to be formal and rigorous, and more about being explanatory and auxiliary to the code itself.
Most times in my career that I've seen people talking about visual programming, it's not about the developers - it's about lowering the bar so that (cheaper) non-developers can participate.
A Business Analyst may or may not have a coding background, but their specifications can be quite technical and logical and hopefully they understand the details. The assumption is that if we create our own Sufficiently Advanced Online Rule Engine they can just set it all up without involving the more expensive programmers.
This is discussed a bit in the first paragraph, but I just wanted to reiterate that most systems I had to deal with like this were talked about in terms of supplying business logic, rules, and control flow configuration to a pre-existing system or harness that executes that configuration. The "real" programmers work on that system, adding features, and code blocks for anything outside the specification, while the other staff setup the business logic.
It works to some degree. I think things like Zapier can be quite good for this crowd, and a lot of mailing list providers have visual workflow tools that let non-programmers do a lot. A DSL like Excel formulas would be in this group too, since it operates inside an existing application, except that it's non-visual. Some document publishing tools like Exstream (I worked with it pre-HP, so years ago) did a lot in this space too.
I did read and appreciate the whole article, I just noticed this part for a reason - I'm working on a visual question builder again right now for a client who wants to edit their own customer application form on their custom coded website, instead of involving costly programmers. It always ended poorly in the past at my previous company, but maybe it'll be different this time.
it's about lowering the bar so that (cheaper) non-developers can participate.
I think that is a terrible approach to anything. Programming isn't that hard and without a doubt anyone who can do business analysis is mentally capable of writing Python or whatever other scripting language.
Instead of teaching people something universal, which they can use everywhere and which they can expand their knowledge of as needed, you are teaching them a deeply flawed process, which is highly specific, highly limited and something which the developer would never use themselves.
Having a business analyst who is able to implement tasks in a standard programming language is immensely more valuable than someone who knows some graphic DSL you developed for your business. Both the interest of the learner and the corporation are in teaching real programming skills.
Even the approach of creating something so "non-programmers" can do programming to is completely condescending and if I were in that position I would refuse to really engage on that basis alone.
you are teaching them a deeply flawed process, which is highly specific, highly limited and something which the developer would never use themselves.
That kind of lock-in can be a feature from the employer's perspective. I did actual coding for years in an environment where what I learned was not very widely applicable at all, for similar reasons. I'm now happily in recovery :) But it makes it harder to leave when you feel like you lag behind where you should be in your career.
I don't think tools like Zapier are condescending. I can and have written code to connect APIs, but Zapier made some stuff way easier, and it lets people like my wife get the same stuff done with far less effort. She has no interest in learning programming. There will be stuff the tool can't do, so then the programmers can step in.
And in my prior job, many people became BAs from a coding background specifically to get out of writing code. They can do it - they don't want to. They're happier in MS Office or similar tools.
That kind of lock-in can be a feature from the employer's perspective
And it can be a huge problem, as he has to maintain a complex visual DSL and teach it to every new employee. Locking employees in seems like a very easy way to make people miserable and unproductive.
An employer wants employers who are long term productive, giving them good tools and the ability to learn new things allows them to not hate their jobs. And an employee who knows basic programming is always an asset.
And in my prior job, many people became BAs from a coding background specifically to get out of writing code. They can do it - they don't want to. They're happier in MS Office or similar tools.
I completely understand that. But there are definitely problems that need to be solved with programming and having people with the ability to do so can only be an asset, even if they aren't a full time developers.
In general I think it is pretty hard sell to teach someone a skill with no other applications. This is different if that person only wants to achieve a certain thing, then transferability is irrelevant. But if you want someone to learn something new, it requires for them to understand why they should learn. Programming isn't particularly hard, teaching someone a standard programming language and giving them the ability to use that in their jobs, instead of a specialized DSL is an enormous benefit.
If you came to me and told me you are going to teach me something which is totally different from what you yourself would do and a special way by which you have made something easy so that I can understand it, I would refuse. I guess that I might be projecting here, but I genuinely feel that many people would look at it the same way.
This actually works if it's not a generic visual programming solution, but if it's a DSL. Don't give the business people pretty graphical loops, give them more abstract building blocks.
Unfortunately that means paying the professional programmers to build the DSL, so it doesn't reduce costs in the beginning.
it's about lowering the bar
I think that might be right.
I remember the first time playing with "visual" programming (kind of). It was visual basic, probably the first version.
It lowered the bar for me.
I quickly learned how to create a UI element, and connect things. A button could be connected to an action.
So then I was confronted with event-driven programming, and that exposure was basically what was taught to me.
And then the beauty of creating a UI slowed as I exhausted the abstraction of visual basic and ended up with a lot of tedious logic.
I had a similar experience with xcode on macos. I could quickly create an app, but then the user interface I created was dragged down again. It seemed to me like the elegance of a mac user interface, required what seemed like a lot of tax forms to fill out to actually get from a visual app to a working app. I really wanted to ask the UI, what dummy stuff like the app name hasn't been filled out yet? What buttons aren't connected? how do I do the non-visual stuff visually, like dragging and dropping some connection on a routine? ugh.
In the end there's a beauty to plain source code, because it seems like text is the main and only abstraction. It's not mixed in with a lot of config stuff that only xcode can edit, and probably will break when xcode is upgraded.
Merging source code line by line is a solved problem. Merging visual code/graphs/graphics is often simply impossible. Also versioning and simply showing diffs become difficult problems with visual programming. That is why visual programming will never scale beyond small toy projects maintained by a single developer.
That said, I agree that visualising your code base might give additional insights. However that is not visual programming, that is code visualisation.
Well visual programming is standard in Unreal projects and they definitely scale beyond toy projects with a single developer. Although Excel is the most popular visual 'programming language', the second most popular is surely Blueprint.
"if you connect to source control within the editor you can at least diff blueprints to compare changes. though it's currently not possible to actually merge them."
https://www.reddit.com/r/unrealengine/comments/1azcww8/how_d...
So it seems like basic functionality like merge is still missing from visual coding in Unreal.
But yes, there were also huge projects before the invention of distributed version control systems. But that wasn't a good world and why go back?
P.S.: Have you ever tried to merge two different excel files?
Maybe it's not impossible but just quite difficult? I use Houdini 'Vops' sometimes and I could imagine a tricked-up diff could be made for it (especially since it translates to vex) but you're certainly right that it's a hard problem in general!
<<<HEAD
A crucial distinction between visual programming and code visualization
Where is the example of the “ very nice visual programming language” he gave from?
It looks like this: https://unit.software/
Was on HN recently: https://news.ycombinator.com/item?id=40900029
It's no longer there - site is unreachable. There's nothing saved on archive.org either.
It's back.
The social problem with visual programming is indeed the same as with "Mythical Non-Roboticist". But there is quite some issues on it on the technical side too:
- Any sufficiently advanced program has non-planar dataflow graph. Yes "pipelines" are fine, but anything beyond that - you are going to need labels. And with labels it becomes just like plain old non-visual program, just less structured.
- Code formatting becomes much more important and much harder to do. With textual program representation it is more or less trivial to do auto-formatting (and the code is somewhat readable ever with no formatting at all). Yet we still don't have a reliable way to layout a non-trivial graph so that it doesn't look like a spagetti bowl. I find UML state machines very useful and also painful because after every small edit I have to spend ten minutes fixing layout.
- Good data/program entry interfaces are hard to design and novel tools rarely do a good job of it the first time. Most "visual" tools have a total disaster for a UI. Vs. text editors that were incrementally refined for some 70 years.
Any sufficiently advanced program has non-planar dataflow graph.
For some reason this reminded me of the elevated rails coming in the next Factorio update. Maybe visual editors need something similar? Even Logisim can distinguish between a node (three or more wires join) and two wires that just cross without interacting.
I mean it's easy to make the compiler see the crosses, but it's much harder for the user to trace these (and parallel busses too).
painful because after every small edit I have to spend ten minutes fixing layout.
PlantUML solves this.
+1
I'd add versioning and diff tools as another critical advantage for text. If your visual tool can't provide a superior diff experience, then it's dead on arrival for most serious projects.
Programming “via” Visualization — doesn’t scale. Great for demos. Good in limited places.
Visualizations “of” a Program — quite useful. Note there lots of different ways to visualize the same program to emphasise / omit different details. The map is not the territory, all models are wrong etc.
It works and even scales up in some cases.
For example having models of capacitor and resistor you can put them together in schematic. Which in turn can be a part of the bigger design. Then test it in simulator. That's how Simplorer works. Alternatively you can write the code in VHDL or Modelica. But visual is quicker, easier, and more reliable.
Obviously it works well for UI, was used for decades now.
As for the rest,... there are visual programmers for robots, mostly for kids.
Schematics don't scale well at all - net labels and multiple sheets demonstrate this.
HDLs rule for gate and transistor level circuit design. I don't know what major PCB houses do but I'd be horrified to discover that 16-layer boards still have a visually built schematic producing their netlist: just finding the right pad on 256BGA components would be awful, let alone finding what else is connected to that net.
Schematics don't scale well at all
Schematics aren't supposed to scale. They're a lossy representation of a subcircuit without caring about the intricate details like footprints or electrical/electro-mechanic constraints.
PCB designers largely don't use HDLs because they don't really solve their problems. Splitting a BGA component into subcircuits that have easily legible schematics is not hard, but it's also not what they care about. That shit is easy, making sure the blocks are all connected correctly.
Verifying the electrical constraints of the 256 pad component is much harder and not represented in the schematic at all. They need to see the traces and footprint exactly.
As an example, the schematic doesn't tell you if a naive designer put the silkscreen label and orientation marker underneath the component which will cause manufacturing defects like tombstoning in jellybean parts.
Why do you think it doesn't scale?
In banking, Camunda is increadibly popular.
You model state changes visually. The model - the diagram with boxes and arrows - IS the code. And then the boxes can have additional code logic in them.
It's a giant pain to work in and debug. But the execs love it because they want to see the diagrams.
Know of any open source equivalents to this?
Google tells me there is something called ProcessMaker, I have never used it personally
I'd rather generate data from diagram and match that against the data in actual code. This way we got all the benefit.
I simply have to recommend Glamorous Toolkit to anyone interested in visual programming: https://gtoolkit.com
It focuses on the kind of visual programming the article argues for: Class layout, code architecture, semantics. It's one of the best implementations I have seen. The authors are proponents of "moldable development", which actively encourages building tools and visualizations like the ones in the article.
The "issue" with it is that it is tied to a Smalltalk, so it's hard to imagine it being more or less practical.
It's not tied to Smalltalk, at least not completely: the standard distribution comes with a JS and Java parser and you can use those to create Smalltalk model of their ASTs, making it look like they're just Smalltalk objects too.
No one ever bothered to open up this site on mobile.
My personal pet peeve with websites of desktop-focused applications.
Great article. Any sufficiently complex problem requires looking at it from different angles in order to root out the unexpected and ambiguous. Visualizations do exactly that.
This is especially important in the age of AI coding tools and how coding is moving from lower level to higher level expression (with greater levels of ambiguity). One ideal use of AI coding tools would be to be on the lookout for ambiguities and outliers and draw the developer's attention to them with relevant visualizations.
do you know exactly how your data is laid out in memory? Bad memory layouts are one of the biggest contributors to poor performance.
In this example from the article, if the developer indicates they need to improve performance or the AI evaluates the code and thinks its suboptimal, it could bring up a memory layout diagram to help the developer work through the problem.
Another very cool example is in the documentation for Signal's Double Rachet algorithm. These diagrams track what Alice and Bob need at each step of the protocol to encrypt and decrypt the next message. The protocol is complicated enough for me to think that the diagrams are the source of truth of the protocol
This is the next step in visualizations: moving logic from raw code to expressions within the various visualizations. But we can only get there bottom-up, solving one particular problem, one method of visualization at a time. Past visual code efforts have all been top-down universal programming systems, which cannot look at things in all the different ways necessary to handle complexity.
Any sufficiently complex problem requires looking at it from different angles in order to root out the unexpected and ambiguous. Visualizations do exactly that.
To me, this is an underappreciated tenet of good visualization design.
Bad/lazy visualizations show you what you already know, in prettier form.
Good visualizations give you a better understanding of things-you-don't-know at the time of designing the visualization.
I.e. If I create a visualization using these rules, will I learn some new facts about the "other stuff"?
agreed, though bad/lazy visualizations can still be useful for a cache. you know it today, but you might forget tomorrow
Bad memory layouts are one of the biggest contributors to poor performance.
This will depend on the application, but I've encountered far more of the "wrong data structure / algorithm" kind of problem, like iterating over a list to check if something's in there when you could just make a map ("we need ordering": sure, we have ordered maps!).
I think the difficulty here is addressing: who is your target audience? Depending on that answer, you have different existing relatively succesful visual programming languages. For example, game designers have managed to make good use of Unreals' blueprints to great effect. Hobbists use Comfy UIs node language to wire up generative AI components to great effect. As far as generic computing goes, Scratch has managed to teach a lot of programming principles to people looking to learn. The problem comes in when you try and target a generic systems programmer: the target is too abstract to be able to create an effective visual language. In this article, they try and solve this issue by choosing specific subproblems which a visual representation is helpful: codebase visualization, computer network topology, memory layouts, etc...but none of them are programming languages
[post author] I agree. On many domains you can find a great mapping between some visual representation and how the developer (beginner or not) wants to think about the problem.
I personally don't see any one pictorial representation that maps to a general programming language. But if someone does find one, in the large and in the small, that'd be great!
Not even all textual languages map well to every problem space.
Blueprints are a good callout(and Kismet before them). Many PLCs[1] are heavily visual language based with Ladder, FBD or other variants. I wouldn't be surprised if they were the most widely used application of visual programming languages.
[1] https://en.wikipedia.org/wiki/Programmable_logic_controller
I personally don't see any one pictorial representation that maps to a general programming language.
I agree. What I've had in mind for a while now is very different from this.
What I envision is "text" in the sense that it's not a diagram, but more advanced textual representation. Over hundreds of years mathematicians have evolved a concise, unambiguous, symbolic notation for formulae, yet programmers are still using tools that are backward compatible with dot matrix terminals from the 60's: simple characters used to write lines in files.
Blocks, conditions, iteration, exits (return, exception, etc.,) pipelines, assignment, type and other common concepts could be represented symbolically. The interface would still be text-like, but the textual representation would be similar to mathematical notation, where the basic constructs of code are depicted as common, well understood, dynamically drawn symbols that programmers deeply inculcate.
Key properties include extreme concision and clarity of the "instruction pointer." Concision is crucial to reduce the cognitive cost of large amounts of logic. The latter is a thing that is entirely obscured in most visual programming schemes and also absent from conventional mathematical notation: the location of the current instruction is absolutely crucial to understanding logic.
I wish I had more time to elaborate what I have in mind, much less actually work on it.
The article mentions a couple of what I think are relevant examples: state machine diagrams and swimlane diagrams. The author makes a great point in the beginning, how programmers don't need to visualize iterator or branch logic code.
Language structures are what they are, we all learn them and know them; they're the tools we're familiar with and don't need a diagram for. What changes all the time (and what made the swimlane and machine diagrams relevant) is the business logic. This is the part that continues to evolve, that is badly communicated or incompletely specified most of the time, and that is the part most in need of increased visibility.
In my experience, this relates closely to what's really important in software development -- important to those who pay the software developers, not to the developers themselves.
I've seen lots of architecture diagrams that focus on the pieces of technology -- a service here, a data bucket there, etc etc. I think that reflects the technical person's affinity for and focus on tools and building blocks, but it puts the primary motivations second. To me, the key drivers are the "business" needs - why do we need the software to do the things, who will use it, and how.
In my work, I try to diagram the workflows -- the initial inputs, the final product, and the sequence of tasks (each with some intermediate ins and outs) in between, noting which roles / user personas execute them. A kind of high-level UML diagram with both structural and behavioural elements. I find that it raises key questions very early on, and makes it easier to then continue laying down layers of increasing technical detail.
If I were to design a visual language, this is where I would start - formalizing and giving structure to the key concerns that motivate and inform software design, architecture and development.
"Language structures are what they are, we all learn them and know them; they're the tools we're familiar with and don't need a diagram for"
If I have a nested construct of various control flow together with some ternary operators, I do wish for something more visual. Or trapped in paranthese hell. Yes I can read that. But it takes energy to decode it.
if while (x<y×2)?(((x...
So I don’t see problem with just doing quick rewrite of the code to make it cleaner.
With GIT you can commit it locally and never publish not to offend team mates :). With IDE I can reformat text and refactor it in matter of seconds. But you can rewrite it enough to understand it.
For graphical representation there are no tools that can help you and also graphical representation will most likely be only worse.
Problem is that “those who pay developers” don’t care to do it on their own. Heck bunch of business analysts don’t care about going down into gritty details - so even if you standardize stuff it won’t shorten the loop.
Only thing it will do it will rob developers of flexibility and level of control they can fix up any “management business grand plan”. Just like all those low code platforms do.
For me low code and visual programming platforms are the same - good ideas for someone who doesn’t understand technical details.
Sequence diagrames (that seems not much different swimlane diagrams) are great, so much so that I created a tool that generates them from appropriately built TLA+ specs representing message exchange scenarios: https://github.com/eras/tlsd
However, while they are good for representing scenarios, they are not that good for specifying functionality. You can easily represent the one golden path in the system, but if you need to start representing errors or diverging paths, you probably end up needing multiple diagrams, and if you need multiple diagrams, then how do you know if you have enough diagrams to fully specify the functionality?
The protocol is complicated enough for me to think that the diagrams are the source of truth of the protocol. In other words, I'd venture to say that if an implementation of the Double Rachet algorithm ever does something that doesn't match the diagrams, it is more likely it is the code that is wrong than vice-versa.
I would believe the latter statement, but I wouldn't say the first statement is that said in other words, so I don't believe this is the correct conclusion.
My conclusion would be that diagrams are great way to visualize the truth of the protocol, but they are not a good way to be the source of truth: they should be generated from a more versatile (and formal) source truth.
Statechart diagrams are even better than sequence diagrams, because they can encode quite a lot of behaviour visually.
State diagram and sequence diagram complement each other, rather than competing.
State diagrams are basically visual code, aren't they?
And indeed they good for specifying, being the source of truth, but like code, they (afaik) don't really work for representing interactions with multiple actors (other than by sending/receiving messages), and they don't have a time component. But you could generate sequence diagrams from them, or at least verify them.
Xstate does have some functionality for interacting with the specified state machine, but I haven't played with it a lot. The idea of generating—or at least verifying—Xstate state machines with TLA+ has come across my mind, though.
It seems odd to me not to mention things like MaxMSP or PD in an article like this. Arguably Max is one of the most successful standalone visual programming languages (standalone in so far as it’s not attached to a game engine or similar - it exists only for its own existence).
Those two are both primarily for real time signals and music right? That is a great domain for wires, transforms, and pipelines.
Have you ever seen them used in a different context?
GNU Radio Companion is its RF/software-defined radio counterpart: https://wiki.gnuradio.org/index.php?title=Your_First_Flowgra...
Sometimes the flowgraph is too complex to be constructed using the visual editor though, for example gnss-sdr uses C++ to generate the GNU Radio flowgraph: https://gnss-sdr.org/docs/control-plane/
No, they are very tailored to that use case. They arent general languages - but they are still probably the best examples of successful visual programming languages.
I'm going to throw a vote in here for Grasshopper, the visual programming language in Rhino3d as doing it the right way. It is WIDELY used in architectural education and practice alike.
Unfortunately, most visuals you'll get of the populated canvas online are crap. And for those of us who make extremely clean readable programs it's kind of a superpower and we tend to be careful with how widely we spread them. But once you see a good one you get the value immediately.
Here's a good simple program I made, as a sample. [0]
Also, I want to give a shout-out to the Future of Coding community in this. The Whole Code Catalog [1] and Ivan Reese's Visual Programming Codex [2] are great resources in the area.
I also have to mention, despite the awful name, Flowgorithm is an EXCELLENT tool for teaching the fundamentals of procedural thinking. [3] One neat thing is you can switch between the flow chart view and the script code view in something like 35 different languages natively (or make your own plugin to convert it to your language of choice!)
p.s. If you are used to regular coding, Grasshopper will drive you absolutely freaking bonkers at first, but once you square that it is looping but you have to let the whole program complete before seeing the result, you'll get used to it.
[0] https://global.discourse-cdn.com/mcneel/uploads/default/orig...
{kind=link}
[1] https://futureofcoding.org/catalog/
Vaguely related: Rhino 3D has the best interface of any 3D modeling tool I've ever used and I'm sad it is not the norm. Is integration between command line and UI is absolutely amazing.
I remember when I first tried to SketchUp I was horrified at how atrocious the UI is compared to rhino 3D.
Yeah, not quite "visual programming,' but there is a similar argument to be made about a program's user interface and how its design suggests it should be used. At this point, that's probably a far better explored area than the same aspect of visual programming.
That said - Rhino is one of the exemplars in this area. I always tell my students - if you don't know what to do, just start typing. As you say the relationship of the graphical command processes and the CLI is stellar.
But - one big shout back to Grasshopper that NOTHING ELSE compares to - if you hold "ctl-alt" and click-hold on a component on the canvas, it opens up the library tab where that component can be found and puts a big arrow pointing to a big circle around it. It's one of the most shockingly useful commands in any program, ever. I've had rooms of students audibly gasp when shown that.
Agreed, Rhino/Grasshopper is an amazing tool, especially once you start adding in C# components. I’ve been using it off and on for several years on custom consumer product projects. It’s an under utilized workflow in many fields requiring 3D modeling imo. I just finished a custom VR gasket generator for the Quest 3 that uses face scans from iPhone as the input and the project wouldn’t have been possible without Grasshopper: https://youtu.be/kLMEWerJu0U
The "swimlane diagram" (I've not heard that term, before) looks a lot like the classic bus timing diagrams that I've used since the 1980s.
I tend to use the same kind of diagram, whenever I'm illustrating a linear flow (or, more often, a set of linear flows).
One of my most useful tools is OmniGraffle.
Swimlane diagrams are from the 1940s[0]. IGrafx trademarked it in 1996. They're often used to model process' that span people, roles or security boundaries [1][2][3].
Sequence-diagram participants[4], and gantt-sections[5] are sometimes used to represent the same.
[0]: https://en.wikipedia.org/wiki/Swimlane
[2]: https://www.lucidchart.com/pages/tutorial/swimlane-diagram
[3]: https://www.drawio.com/blog/swimlane-diagrams
[4]: https://mermaid.js.org/syntax/sequenceDiagram.html#participa...
another good one is https://sequencediagram.org/
Thanks to both of you!
These are useful resources.
I have always illustrated my systems and interactions, but have seldom used formal methods. I would use them, if they are required, but usually find that my subsets are more useful.
I did use “Booch Blobs,” back in the day, followed by UML, but always ended up using a tiny subset of the spec.
Notice that the original code hasn't changed. The only information transmitted in the answer is the corrected diagram. That is because to the person asking the question, the diagram is a better representation of their mental model. As such, getting an corrected diagram has an effect on their mental model but looking at the code doesn't.
This argument (that he tries to make several times in the article) does not hold.
Almost every time, the diagram is a _lower level_ representation of the program than the code is. And then he says "look! you can't figure this out from the code" (so therefore diagrams are better), but if the code was similarly represented in a lower level, you totally could.
And similarly, if the diagram happens to _not_ contain this extra lower level information, you can't figure it out from the diagram either.
I'm not saying diagrams aren't good, they can be great, it's just the reasons in this article aren't particularly compelling. But maybe I'm missing the point.
[post author] You are right. Any "language" visual or other wise used for communication has to include the level of detail trying to be communicated. In the Rust memory layout example, Rust syntax doesn't spell out its memory layout in Rc<T> definitions.
The point though is that the two users of the language _decide_ to communicate in a visual representation! Why is that?
They could spell it out in text, adding that lower level to the text, and yet they don't. That is a sign the users are thinking about it visually and the visual representation maps better to what they hold in their head.
Most of his examples are derived from the code?
They're generally showing consequences of the code, like the layout in memory or the swimlane diagrams. This isn't quite the same thing as code.
I just want an IDE that abstracts my code just enough so that I can work with tokens, not individual characters. I spend way too much time fixing syntax and formatting when moving things around.
Maybe give Cursorless a try. Although they mostly show off the voice recognition, it has a keyboard interface too.
It lets you edit with high-level commands like "swap argument a with b", or "move function x before function y".
You're using the wrong ide then - any serious ide will do exactly that (have an ast representation that it uses for refactoring). Eg jetbrains ides do.
Visual programming with connections often just becomes literal spaghetti code, we really lean a lot on linguistic abstractions to manage complexity. I played around with lots of ideas, the latest one being direct manipulation of visually represented abstractions. Fun and somewhat promising (works really well for expressing bubble and quick sort, less well for rebalancing a red black tree after a delete), but I don’t see anything panning out before AI writes all the code for us.
I just don't think quicksort is a good fit for visual programming, (not that I've ever actually implemented quicksort....).
Visual is excellent for things like "At 7PM if the enable switch is on, turn on the sprinkler".
Stuff that's very simple, but you want no chance of it going wrong, and you might want to edit it from a phone.
When you want the least powerful programming model possible, that isn't even turing complete, that's arguably not even programming and just configuration, it's great.
It really depends on your visual rep. For me, I took symbols related to CFG and RegEx representations, and then focused on direct manipulation of those representations. You can find a YouTube video of it probably, and I know I have a paper somewhere, but it’s been so long.
A conversational interface is already going to work well for simple things, but that isn’t very visual. Without abstraction, encapsulation, and generalization, are you even programming?
You say several times that developers say they want visual programming, but I've never heard any developer ever say this. Is there some particular context where you've heard people say this in particular?
I develop, and I'd like at least a visual of my codebase as it interfaces with other systems as part of automatic documentation. So n=1, I reckon.
Yeah, in fact, most interfaces - video editing, Airbnb, 3D modeling - are some sort of visual interface. I understand code isn’t resembling a physical object.
But books and paintings were our best approximation of reality, then technology allowed us to make movies and photos. I feel like code being lines of text isn’t the best abstraction. But finding a better one won’t be easy.
Scratch seems to be reasonably successful in teaching kids to code [1].
But a large visual blocks program is as incomprehensible, if not more, than a pure textual representation.
Whether text or visual, the challenge for IDE's is the ability to hide detail of large codebases in a way that still preserves the essential logic and allows modifying it. Folding/unfolding code blocks is the primary available tool but its only a primitive way to reduce visual clutter, not a new visual abstraction that can stand on its own.
I think scratch with a little more structure and lots of keyboard shortcuts would work for a "real" language.
It's really just replacing indentation with blocks of color.
An old old effort https://file.io/GRK1MYoYqESv
My 2 €cents from a limited and outdated experience with visual programming tools:
1. Screens have limited size and resolution, and the limits get hit rather fast. The problem can be pushed away by zooming, by maybe an order of magnitude, but for a long living project growing in size and complexity, it will not be enough.
2. In text, near everything is just a grep (fzf,...) away. With the power of regex, if needed. Do the no-code folks nowadays implement a equally powerful search functionality? I had very bad experience with this.
3. Debugging: although the limited possibilities of plugging graphical items together is like an enhanced strict type safety, I'm sure that errors somehow happen. How is the debugging implemented in the visual tools?
4. To store/restore the visual model, the tool developer needs to develop a binary/textual/SQL/... representation and unique source of truth for it. I think the step from that to a good textual DSL is smaller than to a GUI. And the user can more or less effortless use all the powerful tools already developed for shells, IDEs, editors, ....
So in my opinion most of the visual programming things are wasted time and wasted effort.
There’s areas it’s good for: Beaten paths, modeling time-independent structures and things that are naturally 2D. Not so great for the final solution, but handy when you need to do quick iterations. Ex. the interface builder in xcode, the node system in blender, sound synthesis…
Extending #2, we've developed incredibly flexible and powerful tools for editing plain text. I've found refactoring to be a breeze with Vim macros, and people swear by Sublime's multi-cursor editing. Even with a good set of hotkeys, I can't imagine a visual environment being as smooth to edit.
I am not sure that "We need visual programming". Just a couple of arguments against: visual programming struggles with scalability, introduces performance overhead, and lacks the flexibility of text-based programming. For me is a no-no. Maybe it helps beginners but for me it's just an additional layer of (unnecessary) complexity. The purpose of software engineering is to control complexity, not to create it.
I think the headline is talking about you...:)
No, not like that.
I always thought excel could do this, and everyone already knows excel. Toss out the vba, replace with python, every cell is a function, have a regular view, a relationship view that shows which cells connect to the current selected cell, have a run, stop pause, step/break button. Everyone would use this.
This is possible today with google sheets and javascript. The appscript integration is kind of amazing and allows for these flows effectively.
I had no idea. This sounds amazing. Do you know of any companies using this?
The issue with every one I’ve used is that it hides all the parameters away in context aware dialog boxes. Someone can’t come along and search for something, they need to click every element to via the dialog for that element to hunt for what they are looking for. I found every time the lead dev on a project changed, it was easier to re-write the whole thing than to try and figure out what the previous dev did. There was no such thing as a quick change for anyone other than the person who wrote it, and wrote it recently. Don’t touch the code for a year and it might as well get another re-write.
This is definitely true for visual systems. That said, I've also found it to be true for text-based codebases.
Yes, definitely this. I have worked for a couple years on webMethods, where programs can ONLY be created by "drawing/composing" sort of flowcharts (see https://stackoverflow.com/q/24126185/54504 ) and the main problem was always trying to search for stuff inside the "Codebase". And... another benefit of purely text-based code is that you can always run a diff-like utility and quickly zoom in on what has been changed.
What about all the flavors of UML?
https://en.wikipedia.org/wiki/Unified_Modeling_Language#Diag...
Note "executable UML" is not just about diagramming classes and filling in the behaviors but also activity diagrams, state diagrams, etc.
My frustration with it is that the standards don't quite give you enough to make the revolution happen. For instance you should be able to construct a model for all of UML 2 based on EMOF which would let you build a rather simple and compact foundation but there is a strange misalignment between MOF and UML 2 (roughly MOF is based on UML 1) It's the kind of problem I think I could solve if I had two months to chew on it. However I know (a) I struggle to make this kind of thing turn a profit in any sense of the word despite (b) there probably being somebody out there wanting to make this happen and struggling.
Sometime in the early 2000s they generated all the flight code for the James Webb Space Telescope from UML diagrams with Rational Rose. Over a decade later they were still trying to unfuck all of it.
Any link for that? I think it's a good real-life example
I really liked SourceTrail when it was a thing, as mentioned in the article. It's surprising that we don't have something like that for every language as a mainstream tool, to explore how bits of code relate to one another in a visual way. There are dependency graphs, e.g. in JetBrains IDEs, but none are as easy to use as SourceTrail.
You know where visual programming really excels, though? In game development and when working on other types of visualizations.
In shader graphs in particular, like in Unity, where you can very quickly iterate on how things work and look. Writing shaders manually is quite the mess, honestly, so I am really glad that alternatives like that exist, with near-immediate preview to boot: https://unity.com/features/shader-graph and https://learn.unity.com/tutorial/introduction-to-shader-grap...
In addition, visualizing state machines is also really nice: https://docs.unity3d.com/Manual/StateMachineBasics.html and https://learn.unity.com/tutorial/finite-state-machines-1
Also, tools like Blender have node based logic, which is lovely too: https://www.youtube.com/watch?v=cQ0qtcSymDI
Some might also mention Blueprints in Unreal, but personally I think that most of the time traditional programming languages would be a better fit there, but something more approachable than C++, for example, how some engines use C# instead, or maybe GDScript in Godot - many just use Blueprints so they don't have to write C++: https://dev.epicgames.com/documentation/en-us/unreal-engine/...
I love the idea of SourceTrail, and there seem to be active forks of it. Do you happen to know which one is good/trustworthy?
This appears to be the only fork that's at least somewhat active: https://github.com/OpenSourceSourceTrail/Sourcetrail
But overall, there is little activity in any of the forks, without anyone necessarily spearheading the effort: https://github.com/CoatiSoftware/Sourcetrail/forks?include=a...
Twenty years ago I was a researcher (Fraunhofer) on executable UML, especially on aspect oriented programming (AOP which was a thing back then, but never caught on). You could draw a boundary around some UML process flow, and attach an aspect to it. For example a security boundry, and then the code generated would automatically add a security check aspect for all flows going inside.
What we did find out, text is just better to read and understand. It's easier to refactor and much denser. We experimented with different levels to zoom in and zoom out for bigger programs but Visual programming does not scale (or didn't at least back then).
That was the premise of UML and the dream Rational was trying to sell with Rational Rose – that in the future, there would be no conventional programming languages, no software engineers, only architects, philosophers and visionaries wearing suits and ties, daydreaming and smoking pipes, who would be imbued with senses of self-importance and self-aggrandisement using Rational Rose and its visual language (UML) for system design and actually for every.single.thing., and Rational Rose would automatically generate the implementation (in an invisible intermediate conventional programming language as a byproduct). The idea was to obliterate the whole notion of programming as we know it today.
So the implementation in the intermediate programming language (C++) was not event meant to be readable to humans – by design. Rational Rose (the app), however, was too fat, too slow and (most importantly) buggy AF – to the point of the implementation it spat out nevery being able to work. And, UML did not meet the level of enthusiastic support Booch and Co wholeheartedly hoped for.
Whatever the reason was for Grady Booch's personal crusade against the programming and an attempt to replace programming with visual programming, it has failed and done so miserably. Today, the only living remnant and legacy is UML sequence diagrams, and even class diagrams are no longer seen in the wild.
You seem to have come to if from the wrong direction. The entire idea behind the Rational Process was that in the future, your architects would have to every 2 months or so come down from their conference rooms and talk to the *grasp* developers.
IBM had quite a hard time selling this idea. So they decided to push their marketing people outside of their target customers. That may be how they got to you.
This article seems focused on "how do we help programmers via visual programming", and it presents that case very well, in the form of various important and useful ways to use visual presentation to help understand code.
There's a different problem, of helping non-programmers glue things together without writing code. I've seen many of those systems fail, too, for different reasons.
Some of them fail because they try to do too much: they make every possible operation representable visually, and the result makes even non-programmers think that writing code would be easier. The system shown in the first diagram in the article is a great example of that.
Conversely, some of them fail because they try to do too little: they're not capable enough to do most of the things people want them to do, and they're not extensible, so once you hit a wall you can go no further. For instance, the original Lego Mindstorms graphical environment had very limited capabilities and no way to extend it; it was designed for kids who wanted to build and do extremely rudimentary programming, and if you wanted to do anything even mildly complex in programming, you ended up doing more work to work around its limitations.
I would propose that there are a few key properties desirable for visual programming mechanisms, as well as other kinds of very-high-level programming mechanisms, such as DSLs:
1) Present a simplified view of the world that focuses on common needs rather than every possible need. Not every program has to be writable using purely the visual/high-level mechanism; see (3).
2) Be translatable to some underlying programming model, but not necessarily universally translatable back (because of (1)).
3) Provide extension mechanisms where you can create a "block" or equivalent from some lines of code in the underlying model and still glue it into the visual model. The combination of (2) and (3) creates a smooth on-ramp for users to go from using the simplified model to creating and extending the model, or working in the underlying system directly.
One example of a high-level model that fits this: the shell command-line and shell scripts. It's generally higher-level than writing the underlying code that implements the individual commands, it's not intended to be universal, and you can always create new blocks for use in it. That's a model that has been wildly successful.
Shameless plug, but this is what we’re trying to do at Magic Loops[0].
We joke it’s the all-code no-code platform.
Users build simple automations (think scrapers, notifications, API endpoints) using natural language.
We break their requests into smaller tasks that are then mapped to either existing code (“Blocks”) or new code (written by AI).
Each Block then acts as a UNIX-like program, where it only concerns itself with the input/output of its operation.
We’ve found that even non-programmers can build useful automations (often ChatGPT-based like baby name recommenders), and programmers love the speed of getting something up quickly.
Mindstorms is an example of what did not work. I want to provide an example of what does. BBC microbits. It has a visual programming interface that is translatable to python or JavaScript .
But why do people keep coming back to visual programming?
Because real programming languages are free.
That's it. That's the main reason. Sure, there are hobby projects, yes, but almost every visual "programming language" in use in the industry, is a proprietary product, being licensed or sold. It's a way to make money, and a pretty smart one to be honest: Once people invest time, resources, training, and build actual stuff in my proprietary system, they either invest a lot more money to get rid of it, or keep using it. And inertia in businesses being what it is, they usually chose the latter. What better vendor lock-in than a programming language?
-----
IMHO, no, we don't need "visual programming". I have worked with several such systems in professional settings. There is one thing they all have in common: They suck. No exceptions. It doesn't matter what level they abstract at. They are all sold on the simplest of use cases, and to be fair: They can manage them very well. And some even look pretty and are a pleasure to work with.
At the start, that is.
Then the honeymoon is over, and you hit the first snag. The first thing the devs of it didn't anticipate, or anticipated but implemented badly. And you build around that. And then the next thing happens. And then next. And the next.
And very soon, you keep running for the escape-hatch constantly, like calling into library code, or making HTTP requests to some server to do things that would have been a breeze in a real programming language. Congratulations, we are right back to "non-visual-programming", only now our real code is tangled up in this mess, having to waste precious clock cycles pandering to the ideosyncracies of a less capable system, for no better reason that to not get rid of said system. And god help you if you have more than one of these things having to talk to each other. Now you can write glue-code between to pseudo-programming systems! FUN!
And, of course, these things are usually not accessible to any established tooling: There either is no version control at all or some vendors pet project idea of what a cool (read: bad) git alternative should look like. There usually is no way to unit- or integration-test anything. The only "IDE" that can deal with them, is the one the vendor provides. Also, `grep`, what's that? Never heard of it.
"But why do people keep coming back to visual programming?"
Allow me to ask an alternative question: Why do people stick with textual programming, despite decades spent on trying to make visual programming happen?
The first thing the devs of it didn't anticipate, or anticipated but implemented badly. And you build around that. And then the next thing happens. And then next. And the next.
Its interesting to get a perspective from someone who actually has experience with these things. Do you think there is a middle ground where the flexibility can be kept, like allowing manual code edits or use visual part for larger structural things like functions/classes?
Why do people stick with textual programming, despite decades spent on trying to make visual programming happen?
One of the reasons is it just happened to come first with technology progress and the tools you mentioned like search, testing, version control all were developed around to support text. To achieve parity just in that will take a lot, but text has its own problems too, its hard to understand large code bases, follow all relations, design patterns etc. There is a reason we draw diagrams during development process and they are pretty hard to map into actual code.
Most of these solutions are based on a cognitive trap, which I don’t know a name for, so I’ll call it the “maker vs. taker” fallacy.
Person A (the maker) has a problem, and works to solve it by creating a tool. The tool is effective and person A applies it to many similar problems to good effect.
Person B (“taker”) has just such a problem and applies the tool. Unfortunately it doesn’t help nearly as much as person A thought it would. A long series of similar people with similar problems come along and fail.
What the “maker” doesn’t realize is that the tool is ineffective unless you also went through the learning process required to build such a tool, which forces you to understand the problem domain far more deeply than a “taker” ever will.
The tool actually hampers the learning process that the maker benefited from, by asking the taker to learn tool semantics instead of spending time on the actual problem.
That is an interesting framing. I think the "maker vs taker" label is great. Creative Inc[0] uses "suitcase handles" to describe something similar but more generic.
[0] https://www.amazon.com/Creativity-Inc-Expanded-Overcoming-In...
TBQH, I think developing bespoke visualization-to-code compilers for lots of different visualizations will probably lose to multimodal coding LLMs within the next year. Claude 3.5 Sonnet is already very good with text prompting — I'd expect another year of model releases to basically solve turning visualizations, diagrams, etc into workable code.
The bitter lesson of ML is that doing lots of bespoke things per-domain eventually loses to just using a better model. And each of those visualizations is very bespoke, and 3.5 Sonnet really feels like it's on the cusp of this stuff.
That being said, I think the core idea is right: use the visuals developers already use! This will help communicate more effectively to the models, too: there's already a large corpus of those kinds of visualizations.
I use both scripting and models to generate diagrams and I think there's space for some simple balance. Basically there will be things we repeat often enough, where we want a fast, detailed, repeatable solution. And there will be one-offs you will ask for and if it's wrong, you'll fix be hand.
There's space for both and we'll probably migrate the best ideas both ways. (can't wait for a local fine-tune which can do ad-hoc diagrams with a pleasant layout in excalidraw format) I don't think either way is going away soon.
The first link in the "Codebase visualization" section is broken.
The linked talk is intended to be C++Now 2018: Eberhard Gräther - The Untapped Potential of Software Visualization, available at https://www.youtube.com/watch?v=fnIFVYFspfc
Thank you! Should be fixed in a minute
I think we need functional visual programming.
It seems to me like referential transparency and pure functional composition would be a much cleaner way to visually compose functions into larger functions (and eventually programs).
People did some work on this : https://www.google.co.uk/books/edition/Drawing_Programs_The_...
I have another take on visual programming
We need programming environments that can understand both textual & visual code.
We need a new primitive which I call the visual-ast
encode the AST in html via data attributes, and have a system to ignore irrelevant html nodes, giving space for rich UIs to be developed in place of typical AST nodes.
eg.
// textual
1 + 2
// ast
{
kind: "plus",
lhs: { kind: "int", value: 1 },
rhs: { kind: "int", value: 2 }
}
// visual-ast
<div data-kind="call">
<div data-attr="lhs">
<div data-kind="int">
<!-- typical encoding of a value -->
<div data-attr="value" data-value="2">2</div>
</div>
</div>
<div data-attr="rhs">
<div data-kind="int">
<!-- here we can use an input tag but you can do something more fancy -->
<input type="number" data-attr="value" data-value="1" value="1">
</div>
</div>
</div>
If we are going that route, why not go with a lisp-like language?
I think we need to differentiate: Visualize a program vs. Visually program.
This post seems to still focus the former while an earlier HN post on Scoped Propagators https://news.ycombinator.com/item?id=40916193 showed what's possible with the latter. It specifically showed what's possible when programming with graphs.
Bret Victor might argue visualizing a program is still "drawing dead fish".
The power of visual programming is diminished if the programmer aims to produce source-code as the final medium and only use visualization on top of language. It would be much more interesting to investigate "visual first" programming where the programmer aims to author, and more importantly think, primarily in the visual medium.
I think there's a very important real-world nuance here.
What you want with a programming language is to handle granular logic in a very explicit way (business requirements, precise calculations, etc.). What this article posits, and what I agree with, is that existing languages offer a more concise way of doing that.
If I wanted to program in a visual way, I'd probably still want / need the ability to do specific operations using a written artifact (language, SQL, etc). Combining them in different ways visually as a first-class operation would only interest me if it operated at the level of abstraction that visualizations currently operate at, many great examples of which are offered in the article (multiple code files, system architecture, network call).
I really miss ObjecTime ROOM. We used it a lot for embedded software development and it basically allowed to model the "big picture" of your application in (extended) UML and add C / C++ for the details. The generated code for the rest was usually very efficient, the runtime was pretty portable and slim as well.
It became IBM Rational Rose Realtime (! the last word makes a big difference) and then it kind of disappeared from what I know. I believe they tried to integrate it with Eclipse and maybe they did but the IBM website is such a jungle to navigate, I never found something comparable.
Have you used the QP framework (https://www.state-machine.com/)? It supports UML hierarchal state machines with code generation. One embedded dev I know shipped a couple products with it and still likes it.
What do you mean by "modern", and in what way does the existing implementation of Eagle Mode not meet that criterion?
Merge sort (the first example countering visual programming's value) is a great demonstration of something that doesn't make sense to convey visually. I strongly believe algorithms in general are best conveyed using good ol' textual programming.
However, most dev's work isn't writing merge sort, but gluing up databases, third-party vendors, and internal microservices to perform some business logic. The amount of "low-level" coding done is low, and getting even lower with the emergence of LLMs.
With that in mind, visual programming as a way to orchestrate different components together can shine!
That's why I built Flyde - https://www.flyde.dev. An open-source visual programming language that integrates seamlessly with existing code, and doesn't replace it.
I can see why you might want to explain something visually but not build it visually - that merge sort example IMHO being a great example of the latter.
Maybe we need 'programmable visuals' instead of 'visual programming'? Why can't I write a simple one hundred line text file and produce a nice architectural diagram?
Have you seen PlantUML?
Having diagrams and code is bad, they are redundant, they will get out of sync, you will have to figure out whether the code or the diagram is correct. That leaves us with code generation from the diagrams, or more accurately from the languages describing the diagrams, or creating diagrams from code. For understanding a code base it is the later that you want, you do not want visual programming but code base visualization. There are tools for this - for example NDepend [1] for .NET - but they are not really what you want, they are not capable of abstracting enough, summarizing a million lines of code in a handful good diagrams is a very difficult task, for humans as well as for machines.
The other way around - code from diagrams - also does not really work. Those diagrams are domain specific languages in disguise, build to concisely express a very specific programming task. This was tried in the 90s under the label of model-driven programming, you just draw all kinds of diagrams which probably meant that under the hood you were producing XML documents, those could then be fed into code generators and you are done without the need for any real coding. But as we all know, once you step beyond the complexity of hello world, essentially nothing fits any model perfectly, there is always this weird edge case or completely nonsensical requirement. And now you start messing with your code generators or wrapping the generated code in another layer to get the edge cases adjusted. Or you are writing your own visual designers and code generators.
Most of the time it is hard to convince "normal" people that text is the end game.
Text is all powerful, because you can encode any level of abstraction with text only. If you need access to nitty gritty details having text is god send, having to work on high level also fine you can just do that wrapping lower level stuff in descriptive abstractions.
We also already have tooling for dealing with text that go as far back as computing and if we leave a bit of space for interpretation even longer.
With GIT/VIM/AWK/GREP/SED you can be in charge of vast universes created in you mind and share/collaborate on those with others. While image is worth 1000s of words - options to manipulate/share/collaborate on text are so much better in every conceivable way.
As so often, it starts with the wrong term. The kind of "visual programming" the author says they want is not programming at all, it's visualizing what has already been programmed. So this whole thing is a straw man based on obvious misinterpretation of what "visual programming" may mean. Unsatisfactory and disappointing.
The distinction you are making is right. All those examples are examples of visualization, not of direct programming.
But why can't we use what today are visual representations of the programs as the actual programs? Can't we have the state transition diagram that today is a visualization of the code _be_ the definition of the state transitions? That is the question the post is asking
In other words, elevate the visualizations that we already use into programming, instead of programming with visualizations we don't use.
Isn't "visual programming" exactly what a whole lot of 3D artists do every single day?
Whenever I watch people using Blender it sure looks like a whole lot of visual programming to me.
Blender's geometry node system is definitely visual programming.
I built a little game around the idea of a visual representation of s-expressions. It is meant to make it easier for newcomers to learn to program. The visualization not only allows you to edit programs more easily, but also to observe it as it runs.
Heavily inspired by MIT's Lisp-based SICP course.
The game uses Rust+SDL, and is playable in the browser thanks to WASM. https://www.bittwiddlegames.com/lambda-spellcrafting-academy...
Love the idea.
Not sure if the Demo represents the final state but please add an option to adjust the text speed, importantly, including an option to show the text immediately. Yes, you can double click but that is unergonomic and adds an delay. As a fast reader, I skipped over most of the explanations because I just couldn't tolerate it. Also add the option to progress the dialogue via key press instead of mouse. And the text needs a margin left and right.
This stuff might sound minor but can make a huge difference in player retention. Definitely looking forward to trying your game out once it has been polished a bit more.
I genuinely have no idea how to read the first diagram presented. Maybe I'm not the target audience - I'm significantly NOT a visual learner, but that first diagram is far more confusing to me than code/pseudocode.
That system, Unit, was on the front page here about a week ago: https://news.ycombinator.com/item?id=40900029
It's got a certain aesthetic appeal but I don't find it self-explanatory either.
We need to see the code paths that were executed for a certain request/feature/transaction.
I created Call Stacking for this visualization.
Nice!
My take:
- Visualizing logic: I don't find it useful most of the time.
- Visualizing "metadata": Yes please.
By metadata I mean, visualizing inferred types, file/class members outline, dependencies, lints etc. Some of this visualizations are added directly to the text editor.
In some sense, all programming is visual. Our methods of programming are not designed to be listened to, or felt. They are designed to be looked at.
This has the interesting effect that we care more about how code "looks" more than necessary. We place an emphasis on code formatting, even though how the code is laid out doesn't affect how it gets executed. We often talk about "lines" of code or "blocks" of code, even in languages where lines or blocks don't carry any semantic meaning.
This is just my opinion man, but I suspect this is why Python is popular, while Lisp never caught on. Despite being grammatically simple, normal Lisp code looks like a bracketed mess. A lot of people can't get over that first impression.
The screenshot appears to be from https://unit.tools Came across it recently on twitter and loved how it looked. After going through the features list, I was compelled to try it seeing how much thought and effort went into it. The site’s been offline mostly unfortunately though ;/
Excel Formula is the most popular programming language by a few orders of magnitude and it can look like this:=INDEX(A1:A4,SMALL(IF...
I'd argue Excel is actually a visual programming language, the formulas might look like just messy text programming when written out of context but in Excel each part is highlighted to a spatial and visual environment and can be constructed by clicking and selecting in that environment.
I seem to have a fascination with code visualization and exploration. Looking at a complex codebase through a variety of perspectives can have a lot of utility. I like the heatmap a lot but that's only of statistical benefit and less exploratory.
I created a rudimentary graphical ruby programming environment https://x.com/RussTheMagic/status/1809091784946921670 however I realized similar conclusions of this article; while i could do lazy evals, and method parameters and all sorts of song and dance... that's not actually what I needed - which was a way to better work with and tinker with code. I've used irb/pry extensively for this, but it's always had it's limitations there.
I wanted to be able to see what the result of the ruby code was as it was executed line by line and be able to explore the return values, so I made another version which is a realtime, visual irb called revirb https://x.com/RussTheMagic/status/1811427507784315309
Check out Spring Modulith at https://docs.spring.io/spring-modulith/docs/current-SNAPSHOT.... Their pitch is that the application framework organizes your code in such a way that it makes the architecture of your application easier to visualize and to reason about. I haven't tried it but have seen some talks on Youtube that makes we want to give it a shot in the future.
I started calling this DataViz driven Development but I am more interested in DataViz of the application state, than code statistics. I am a big debugger fan, however, it falls down when debugging things that are not well represented as assignments. For example, spatial problems are better visualised with maps (rendered as images), not lists of features with numeric coordinates. Here DataViz can bridge the legibility gap between the internal representation and something a programmer can quickly grasp to find bugs.
So in my opinion the best place for going beyond text in programming is by adding custom DataViz to express program state at runtime.
I've done my own "try to animate things with mermaid like lang" https://github.com/dot-and-box/dot-and-box
and got one conclusion similar to article's author as I understand it: general purpose visual programming lang is hard or impossible
I feel like flow-based programming platforms like that you'll find in unity and unreal engine are the future of "visual" programming languages and systems. These have adoption, and simplify greatly some of these very complex systems - particularly where you have massive paralellism.
Great article! I was afraid it was going to be trying to formalize a lot of visual ideas similar to what UML tried to do back in the day. Instead, this is a very nice catalog of many good visualizations that can be used as aids to the task of programming.
This is a great article, thanks for sharing.
The problem with most visual programming is that most platforms avoid making any tradeoffs.
A good visual programming tool should abstract away complexity but it can only achieve that by reducing flexibility.
If you're going to give people a visual tool that is as complex as code itself, people might as well learn to code.
It helps to focus on a set of use cases and abstract away from common, complicated, error-prone, critical functionality such as authentication, access control, filtering, schema definition and validation. All this stuff can be greatly simplified with a restrictive UI which simultaneously does the job and prevents people from shooting themselves in the foot.
You need to weed out unnecessary complexity; give people exactly the right amount of rope to achieve a certain set of possible goals, but not enough rope for them to hang themselves.
I've been working towards this with https://saasufy.com/
I've chosen to focus on CRUD apps. The goal is to push CRUD to its absolute maximum with auth, access control and real time data sync.
So far it's at a point that you can build complex apps using only HTML tags. Next phase would be to support generating and editing the HTML tags via a friendly drag and drop UI.
Still, it's for building front ends. It cannot and will never aim to be used to build stuff like data processing pipelines or for analytics. You'll need to run it alongside other services to get that functionality.
This article really hits home for me. I've been working on a tool called Code Charter, which aims to do exactly what you're advocating for: provide visual representations of code that make it easier to understand.
I'm taking a slightly different approach than some of the tools mentioned here. Code Charter uses successive LLM calls to distill the key patterns (i.e. business logic) in code, creating a semantic map for call graphs in a codebase. This is useful for understanding the architecture of a project and, during development, for moving between the high level and the implementation code.
It is still in development and will be released soon as an extension for VSCode.
Check it out if you're interested: https://github.com/CRJFisher/code-charter
Imagine trying to handle a git merge in two dimensions.
I hope one day AI can transform ULM to a codebase. It would be a big change for devs cause we spent a lot of time writing tech solution, discussing about pros and cons, designing... AI should help us finish the rest.
obviously not the point of the article but I really appreciate Unreal's visual programming flow.
I think an underrated idea from visual programming is that futzing around with linear files to try and connect a bunch of stuff together is not that fun in an event-based system. Stuff like Scratch unlock the right idea, that code structure is important at a micro level, but at a macro level it's... kind of busy-work, and it's hard to offer good structure in a way that's discoverable.
My main complaint with Unreal blueprints, though, is that sometimes you really do just want to write a bunch of code in a linear sequence. Give me a little textbox to just pop into within my diagram!
I think part of the problem is that coding projects can get really big - like millions of lines of code big. Not making a huge mess of things at that scale is always going to be difficult, but the approach of text-based files with version control, where everyone can bring their favorite editors and tools, seems to work better than everything else we've tried so far.
Also, code being text means you can run other code on your own code to check, lint, refactor etc.
Visual programming - that almost always locks you into a particular visual editor - is unlikely to work at that scale, even with a really well thought out editor. Visual tools are great for visual tasks (such as image editing) or for things like making ER diagrams of your database schema, but I think that the visual approach is inherently limited when it comes to coding functionality. Even for making GUIs, there are tradeoffs involved.
I can see applications for helping non-programmers to put together comparatively simple systems, like the excel example mentioned. I don't think it will replace my day job any time soon.
Are there any tools that can generate any of these sorts of visual aids using the existing code itself (perhaps also utilizing comments or annotations)?
The sort of visual programming the author talks about seems like it could benefit from the concepts of presentations and semantic graphical output as seen in projects like CLIM (the Common Lisp Interface Manager).
I've designed a data analytics/flow processing thingy with, what I call it, a visually assisted editor.
The idea was to let the user write the code (sometimes in the Intellij's smart template style, sometimes as a code) and to show them the code represented as a graph, with some hints regarding type inference, possible scheduling, optimizations, etc. Then the user can run in-browser simulations on small sample datasets either provided by the backend or typed ad-hoc and the graph will be coloured accordingly. And then the user can do real runs.
The language is t-incomplete, so the representations are really sleek. In fact, some of the graph nodes can carry t-complete snippets inside, but their contexts are isolated and purity is enforced.
Unfortunately, I don't think it'll ever become foss or even public.
I'm working on visual programming for Python. I created an Python editor, that is notebook based (similar to Jupyter) but each cell code in the notebook has graphical user interface. In this GUI you can select your code recipe, a simple code step, for example here is a recipe to list files in the directory https://mljar.com/docs/python-list-files-in-directory/ - you fill the UI and the code is generated. You can execute code cells in the top to bottom manner. In this approach you can click Python code. If you can't find UI with recipe, then you can ask AI assistant (running Llama3 with Ollama) or write custom python code. The app is called MLJAR Studio and it is a desktop based application, so all computations are running on your machine. You can read more on my website https://mljar.com
After usong Houdini for some hobby graphics, I’ve come to the conclusion that its mixture of graphical+textual programming is quite reasonable and might be somehow used in other development environments. But obviously, Houdini is a modeling software and the feedback is quite fast.
Great article. I do agree with it, while I'd add this conclusion (personal opinion):
- Usefulness of visualizing the codebase, interconnections, memory layouts - all of these are attempts of an overview of the things that aren't immediately clear. It's an attempt for an outside-of-the-box view, which becomes necessary in larger codebases/environments/companies. This is very useful for, say, an architect of a system (or systems), and even for individual contributors that are not comfortable in the current view (they may be struggling, or they may achieve better performance, of either the app or themselves with the insight gained from these visualizations).
- Actual visual programming only offers "boxes" of functionality and makes you frame everything the way it was initially imagined. It's limiting expressiveness and makes your mental model adopt the framework's way of thinking. Everyone I know has abandoned any visual programming only because they feel it is limiting them ("It's a nice toy, but it's too difficult for me to create something more complex" is a common thing I hear).
Great article. To circle back to the point, some of these visualisations also contain hints to how they could be used for actual programming.
E.g. changing arrow type in the ownership diagram is a good example of a change that is very annoying to do manually in Rust but it's trivial in the diagram.
The challenge is to connect this action to the whole programming workflow, which is currently optimized for text, I'd even say overfitted. Rust especially is famously difficult to process by tools. I think we might need to use a language that is specifically designed to be processed by visual tools to make it all work.
Speaking of visual anything. I once ran across an experiment* where instead of leaving non programmers with the GUI, they encouraged them to experiment with a CLI to do their tasks. Guess what, everyone got more productive and preferred the CLI after they figured it out.
So do you have to waste resources on pretty graphs, or is it more efficient to stick a text based DSL in there for your non programmers?
Is the current fetish for meta meta meta programming a feature or a bug?
Can't you give your business analyst a BASIC like DSL that they can use to script most of their specific problems away? Like, you know the stuff in ms office?
Of course, to do that you need to unlearn your C++ and Rust and even python while designing the DSL :)
* With web search being what it is these days, I'm not going to even try and find a citation.
** Even what TFA is talking about can be considered a DSL. A DSL for debugging and software maintenance. They say it should be graphical, but a good part of the stuff that's mentioned would work as well in text reports.
Graphical interfaces for Propagation Networks seems like a great idea. Propagation networks are computational methods like formulas where you can input known values for any variable, and the other variables are calculated on the fly, propagating "new" information and error values as they accumulate. Like Dataflow or Reactive Programming, but instead of a DAG (Directed Acyclic Graph) structure for the flow of information you have a true Graph that can back propagate information.
All the textual code I've seen to make these has been ugly, despite the concept being similar to formulas laid out like circuit diagrams with "cells" for the unknown values.
What we need is auto-generated diagrams. Not visual programming.
I just hope Epic someday puts a text scripting language in the Unreal Engine.
There are production-level visual programming systems, Mendix is one of them, I have a friend who works on a industrial system fully built in Mendix with just a small amount of custom java code, but processes, data handling, UI all is made in it.
I build one of these visual frameworks too (https://www.ondiagram.com/) and I agree completely with the author.
People think it's a good idea because it will save them time and I get many messages about different questions, use cases and support but the reality is you trade convenience for risk that something will be missing. What most people really want is a boilerplate for the SaaS, some building blocks for their UI and to not think about deployments.
VCs love this too, and many reach out, especially a couple of years ago. Maybe they know something I don't, maybe it was just phase.
A unique project I saw recently, that is developing a kind of visual programming environment with the goal of unifying design and code.
Pax: Build UIs visually in Rust
A library for building web & native applications alongside visual creative tools
Programmable Logic Controllers (PLCs) that follow the IEC 61131-3 standard [0] utilize 5 different programming languages, three of which are visual/graphical, and two of which are text-based.
The graphical languages are well-suited to industrial programming contexts - and especially object-oriented modalities - as nearly everything that is being programmed is a representation of something in the physical world.
Plants have process lines which have equipment types (classes) with different variations (inheritance) which have sensors which have various configuration parameters and so on. Many of these types of equipment have common functionality or requests made of them (interfaces).
One of the IEC text-based languages - Instruction List (IL) - is deprecated, the while other - Structured Text (ST) - is Pascal-based, great for more complex math and logic functions, and likely runs a significant portion of the infrastructure you interact with on a daily basis. This is especially true if you live outside of North America, which tends to still rely heavily on ladder logic.
The three graphical languages have somewhat different ideal use cases and functionality, though for historical reasons ladder logic is frequently used to do 100% of the work when other languages may perhaps be more appropriate. The same may be said of some 100% structured text implementations.
Ladder logic (LD) was designed to represent banks of physical relay logic hardware. It is read left to right, and if a connection exists between the two, the right side is active. As such, it is great for simple controls that rely on boolean logic and simple functional logic. A good ladder program can be seen and understood and debugged quickly by anyone who has any knowledge of the underlying physical system, which makes it very popular for basic on/off systems such as motors or pumps.
Function Block Diagrams (FBD) are exactly what the name implies, and like LD are read and processed left-to-right. I like them for certain kinds of math processing such as linear interpolations.
Sequential Function Chart (SFC) is, like FBD, exactly what it sounds like. These are ideal for describing state machines with a defined start and end point, and discrete steps in between. They are not expressly limited to a single active state at any one time, and can have multiple parallel active branches. Codesys-based systems extend on the base IEC specification by expanding upon the way that actions and transitions can be defined and worked with.
Codesys-based systems also have Continuous Function Chart (CFC) and Unified Modeling Language (UML) languages. CFC may be thought of as an extension of FBD and/or SFC, and is useful for creating higher-level equipment coordination diagrams and designs. UML has class and state diagrams, and I've used it not at all, so I won't comment on it further.
For me this is a class of “super-linter” - and potentially a unit test
If (if!) you can extract the diagram (or better the graphviz representation of the diagram) from the code, then you immediately have a test that says “hang on you chnaged the code so it no longer reflects the agreed diagram - that seems like a test fail to me”
This is not to dismiss the article - it’s fantastic and I want all of those capabilities now. It’s just to emphasise (as the article does) that in almost no cases is this visual first - it’s code first
Another example of good visualization is the Node Event Loop from this JS Conf talk - https://www.youtube.com/watch?v=8aGhZQkoFbQ
Unreal engine and unity have visual programming, and I think they're great. Complex enough to code very specific features, easy enough to learn when you put enough time into it.
I think people get too hung up on the visuals. There was a (failed) attempt to create something called intentional programming by Charles Simonyi. That happened in the middle of the model driven architecture craziness about 20 years ago.
In short, his ideas was to build a language where higher level primitives are created by doing transformations on lower level syntax trees. All the way down to assembly code. The idea would be that you would define languages in terms of how they manipulate existing syntax trees. Kind of a neat concept. And well suited to visual programming as well.
Weather you build that syntax tree by typing code in an editor or by manipulating things in a visual tool is beside the point. It all boils down to syntax trees.
Of course that never happened and MDA also fizzled out along with all the UML meta programming stuff. Meta programming itself is of course an old idea (e.g. Lisp) and still lives on in things like Ruby and a few other things.
But more useful in modern times is how refactoring IDEs work: they build syntax trees of your code and then transform them, hopefully without making the code invalid. Like a compiler, an IDE needs an internal representation of your code as a syntax tree in order to do these things. You only get so far with regular expressions and trying to rename things. But lately, compiler builders are catching onto the notion that good tools and good compilers need to share some logic. That too is an old idea (Smalltalk and IBM's Visual Age). But it's being re-discoverd in e.g. the Rust community and of course Kotlin is trying to get better as well (being developed by Jetbrains and all).
But beyond that, the idea seems a bit stuck. Too bad because I like the notion of programs being manipulated by programs. Which is what refactoring does. And which is what AI also needs to learn to do to become truly useful for programming.
All in all, this is a good post. I look forward to sharing it with coworkers tomorrow with regards to documentation improvements.
But nobody ever made a flow chart to read
for (i in 0..10) if even?(i) print(i).
Developers familiar with code already like and understand textual representations to read and write business logic
Yes, but workflow diagrams help non-programmers even more. Product teams, hardware teams, and training/reference manuals can all be better derived with all three (workflow diagrams, autogenerated/comments, code snippets)
let me ask you: do you know exactly how your data is laid out in memory? Bad memory layouts are one of the biggest contributors to poor performance. Yet it is very hard to "see" how a given piece of data is laid out and contrast it with the access patterns present in the codebase.
Yes. I would love to see a tool that builds on a C++ language server to show memory layouts of each concrete class at the instantiation of `new` or anything which calls it such as `make_unique` or `make_shared` or similar static functions or etc. Show me call trees where allocations occur, especially ephemeral allocations!
I would love to see how many of a given object might fit on typical cache lines or page sizes, to optimize reserve sizes of containers especially memory pools. That can be done in code with sizeof() fairly easily, but it would be cool to have a it shown graphically in the IDE.
do you know all the external dependencies your code hits when responding to a given HTTP request?
No, but I use open source software stack up to and including the kernel, and can read the whole stack if I find any odd behavior.
Are you sure?
Yup, most recent complex issue was related to Address Sanitizer memory layout and kernel ASLR changes. Complex issue prior to that was gRPC or protobuf library crashing before main() starts. That was never fixed, it was worked around multiple times. Good luck anyone using protobuf in C++ for anything more complicated than the examples! protobuf and gRPC code is a f00kkin nightmare of bad practices!
Didn't you notice that Bob just added a call to a rate limiter service in the middleware? Don't worry, you'll learn about it in the next outage.
Don't blame the outage on Bob, he did pretty good work. I even approved the unit tests for it. It's my fault I didn't catch the rate limiter's O(n) quickly ramps up logarithmically with connection count per instance, I forgot to ask for an automated benchmark test for it.
One reason is because we think that other, more inexperienced, programmers might have an easier time with visual programming. If only code wasn't as scary! If only it was visual!
Reminds me of the Mythical Non-Roboticist: https://generalrobots.substack.com/p/the-mythical-non-roboti...
Visual programming works best when it is used on a limited domain with a higher level of abstraction than programming languages such as C. For example data transformation, image manipulation, sound processing etc. More discussion of isual vs code here:
https://successfulsoftware.net/2024/01/16/visual-vs-text-bas...
Here is our attempt at Visual Programming: BuildShip[0]
Top level layer is a no-code box but you can dig in a level deep to look at the code. You can edit the workflow with nocode or lowcode. AI can help with code gen. Plus connected to your database, tools like S3, Postgres, Firebase, Supabase etc and ships in one click to a Cloud platform like Google Cloud.
When you look at a visual model of a program it should be easy to trivially understand what each visual element does. If that is the case it becomes a great tool for debugging why your program is wrong because in a visual model you could spot an element and say: Why is this element here?. Perhaps simple as "Why is this element so much bigger than others?"
If a tool provides just a view of some aspect of the code it is easy. If you require that the model be editable and will synchronize the changes from code to visuals and vice versa I think it is an order of magnitude bigger problem, less likely to scale.
Should you replace all the features of your favorite programming language with a tool for building visual models which don't really support the advanced language-features at all?
Consider that there are a myriad of different programming languages each claiming to be better than the others. But if you program by creating visuals first then of course you cannot do everything with it that you can in your favorite best programming language.
It makes me think of https://moldabledevelopment.com/
You do not code in the visual environment but it helps you to create tools to visualize exactly what you want/need to see. The interactivity is hard to beat and once you are used to it, you can quickly create visualizations that you can throw away (or keep).
I’ve been dreaming about a visual editor for Clojure/LISP, where inputs, outputs, and side effects are clearly identified visually similar to Feynman diagrams. Gave a talk about these ideas at a local Clojure meet up a while back: https://youtu.be/edQyRJyVsUg?si=q0M0D2jfsq9GmnqB
I have never seen any of these visual programming systems > even be mentioned while trying to solve problems.
I'd say that's because drawing diagrams, especially in a non-fugly way, requires concentration on the action of drawing, and is slow, whilst typing requires almost no concentration, nor even looking at the keyboard, so it's much faster, even if less pretty.
The Big Tech monolith (`bingo`, `papaya`, etc.) is a fantastic callback to this video: https://www.youtube.com/watch?v=y8OnoxKotPQ. Although that video is perhaps ironically about microservices.
Perhaps some readers are traveled enough to have actually used this site owner's fortuitous product: Yahoo! Stores. You would pick commands from a button nav at the top, and then enter values. I came to realize, this was probably pretty heavily LISP based, but at the time the people I knew were creating these "visit data" like recursive structures in Java. Good times.
Re-posting my 5 years old article "Rethinking visual programming with Go" here [1]
There's one kind of visual programming that I find interesting:
ProtoFlux, found in Resonite: https://www.youtube.com/watch?v=qxXRbHDaMKg
Part of the point of this is making it possible to write code that does something useful while wearing a VR headset, using VR controllers. The downside is that you can tangle it up in all 3 dimensions!
That's not visual programming, because you can't influence its behavior by manipulating the diagram. They are useful diagrams generated from code, but it's fundamentally a different thing.
I really want to be able to program with swimlanes for concurrent systems. I think BPMN is close(ish) but I would like it to be typed in a way which can check of the types of the code I write in a box.
It’s a problem I think about more generally quite a bit. In general, the problem is optimizing efficiency of translating thought into machine code. Our thoughts move much faster than our hands. Our thoughts don’t execute linearly— able to seek to many random ideas and back without much of a sweat. I don’t think visual vs. text is going to make much of a difference, because both use the same interface device. Honestly, if you think about it that way, text based workloads are going to win every time because the keyboard is much more precise and fast than a mouse. My point is that this will always be an interface device problem, not a visual vs text (mouse vs keyboard) problem. FWIW I think KBM and text with modern tooling is incredibly efficient already, but my mind is open to some new interface device that changes everything. Not so sure that means VR, because VR is really just a pair of pointers (two mice)
My take, in a few years many "frameworks" for front end and back end will be LLM based. Areas where you document your tables with pure language, what tables are ok to be manipulated by what kind of user. And LLMs will make a REST/GQL service exist from all of that.
For the front end, I believe that front-end frameworks will rely on LLMs to costumize the look and feel. It will also allow you to define "forms" that know how to call the right back-end service, as long as you give it the appropriate doc links.
I think the no-code revolution may get a huge boost now that llms exist. It will take 2-3 years before this is commonplace.
I have never seen any of these visual programming systems even be mentioned while trying to solve problems.
Unreal Engine’s Blueprints and Material Graphs are visual programming tools used heavily in indie to AAA games. So that’s one visual programming language used to solve problems all the time.
More broadly it feels like there's a lot of potential alpha in the tooling space that just gets left on the table by the industry
I don't know what the reason is. Making tools is hard? Thankless? Tough to generalize? Devs are reluctant to adopt new tools?
Whatever the reason, I feel like workflows could be an order of magnitude more effective with better tooling. And I don't even mean the table stakes of "can install dependencies and reliably build and run on different laptops" (which some ecosystems still fail). There's huge untapped potential for "tools that tell you interesting things about your code and/or program"
My personal theory is that the design of most programming languages today makes static analysis much harder than it needs to be. And then I guess, runtime analysis is just fundamentally hard to tack onto an existing language no matter how it's designed
Two domain focused examples: Blender material node: I could imagine certain material nodes to be highly annoying to script (or even represented differently than nodes), even something relatively simple like this https://i.imgur.com/kETcJYE.png (nodes), https://i.imgur.com/eddAhcv.png (final render) Fusion comp node: On the other hand, this seems like a lot of blocks for this simple image: https://i.imgur.com/ftfHngt.png (Cool thing about Fusion is that any node can be copy/pasted to notepad as text and vise-versa) Note: I'am neither Blender nor Fusion expert.
{kind=link}
{kind=link}
{kind=link}
The kinds of visualisation discussed by the article remind me very strongly of Glamorous Toolkit [0], most recently posted to HN at [1]. It’s something I’ve never really felt a need for, mostly because the software I work on is mostly very small in terms of code size (for physics research etc.). The idea is certainly fascinating, however… there are a lot of possibilities for a codebase which can introspect itself.
I feel like one of the reaaally tricky bits of visual programming is avoiding bundling language and interface together.
Developers all have lots of (different) opinions about editors, but they're fortunately seperated from the language they choose. People can work together on TypeScript usong Emacs, VSCode, Zed etc and it all gels.
The second someone starts with "to use this language you have to use this editor" the bar is sooo high for developers not getting their backs up.
It would be immense to have a visual way of programming that was language agnostic, but you'd need a seriously intense protocol to make that possible.
It does make me think of things like Smalltalk and Visual Basic that where designed to support multiple approaches. Interesting how that research avenue has drifted off recently.
I always like to make the destinction between models on architecture for developers (the solution description) and the models describing functionality (the problem description). One is a result from the other. Both sometimes are not written down but exists in team-members heads. Both are used for communication. Both should be in sync.
If an analyst can create the "perfect functionality model" than a developer can parse this into the "perfect software", provided he created the "perfect architecture model" to assist this. See my other post on MDA and MBSE.
When developing (parts of) complex software, I always liked doing something akin to "Unit Testing" (plus a custom UI/report) that basically checked the boxes of a Architecture-Model I wanted to adhere to. With near-instant compilation (or hot-reloading) it becomes easier to see a live reflection of the data going through your pipeline live.
A good End-To-End (E2E) test can do the same for a Feature-Model, e.g. using Test Driven Development (TDD) or any derative of this. However todays tooling is still behind on this, compared to tooling developers have for architecture. Only a few solutions exist and those are tech-giant level (IBM) or contained and highly specialized for one business sector / problem domain.
As a Software-Developer this article made sense, although I would want it to include a few more useful UML diagrams. Models is the keyword here to me, not "visual".
User Feature -> Feature Model -> Architecture Model -> Source Code
Some buzzwords to google: - Business Process Modeling and Notation (BPMN) - Model Driven Architecture (MDA) - Model Based System Engineering (MBSE)
In theory, the developer output is a function of the desired functionality. If the functionality fits a parsable model, we should be able to transcode this into sourcecode. In a nutshell this is can be a result from adoption of MDA and/or MBSE.
In a nutshell, I believe software development should happen from models to "generate" code, that then can be augumented by software developers. Updates from a model should result in updated code.
Transition diagrams for state machines, Swimlane diagrams for request / response protocols.
100%. especially because these things also form the basis for static analysis; if your state / protocol diagrams let you run something like TLA you are doing really good
Visual programming is more or less equivalent with node graphs. Node graphs are good at doing certain things that suck to do in text (e.g. defining a ton of wild connection graphs), but suck at other things like loops, etc.
That's why I would say: why not both?
I tried working on something like this for unit tests. This inspires me to get back to it.
My idea is to make a game out of every source code file. When you win the game, you will have 100% coverage.
What about node red?
I’ve seen some pretty sophisticated stuff done with that.
Algorithms are graphs, data structures are graphs, networks are graphs, relationships are graphs.
Let’s use text to describe everything!
Weird… I would have called most of those diagrams “Design” not “Implementation”.
This is how I work - draw a Control Flow Diagram as the design, implement it in actual code, then test the code against the diagram.
People have mentioned a bunch of successful visual programming applications, but one that I've been thinking a lot about lately is Figma.
Figma has managed to bridge the gap between designers, UXR, and engineers in ways that I've never seen done before. I know teams that are incredibly passionate about Figma and use it for as much as they can (which is clearly a reflection of Figma themselves being passionate about delivering a great product) but what impressed me was how much they focus on removing friction from the process of shipping a working application starting from a UI mockup.
I think Figma holds a lot of lessons for anyone serious about both visual programming and cross-functional collaboration in organizations.
I am a tool creator (serious tools count of one) that created a tool out of genuine personal need, in reference to the note linked from " serious contexts of use".
In my case it is in context to the state machine portion of the blog.
The link to Leslie Lamport and TLA+ is informative and the initial point of my tool making was to end up with an executable specification of a state machine that could be translated to TLA+ to allow validation by formal methods.
For functional safety (IEC 61508 and subsidiary standards) this is the Holy Grail for a significant number of applications. Think things like Rail Signaling, Burner Management Systems, Aircraft Landing Gear Hydraulic Sequencing, complex machinery automation and interlocking, to name a very few examples. It can also extend to Cyber Security and transactional systems like banking etc.
In my tool I haven't quite got to automatic translation to TLA+, yet, and maybe I personally won't, because as discussed in the blog and some of it's links, the interface itself prompts a certain level of thinking that is highly beneficial. So I have done everything but an automatic translation to TLA+, but I can see no reason it is not possible, I already automatically translate the specification into controller code.
But the key point arising from the definition of state based behavior, which is what TLA+ is all about, is that implicit state is the enemy. And if all states and transitions are not defined explicitly, then the door is opened to implicit state.
The often-quoted example is the Apple Facetime bug where you could follow a specific, unintended, sequence to make a call and then listen to a callees microphone before they answered.
https://medium.com/@DavidKPiano/the-facetime-bug-and-the-dan...
Also interesting is this one where a bug involving implicit state was fixed by changing two characters, after som eeffort.
https://blog.scottlogic.com/2020/12/08/finite-state-machines...
For finite state machines the problem is the State Chart (and or UML) - neither forces an exhaustive and unambiguous examination of every transition for every state.
In order to do this, you need a State Table, and ideally a dereferencing of the inputs by grouping them into Transition Input Conditions from raw inputs.
The State Table looks like columns with all possible "From" states heading them and the "To" state underneath. Where more than one possible "To" state is possible, a new column is created with the same "From" state.
The logic is "scanned" or "polled" at regular intervals, it generally cannot be event driven, to ensure deterministic outcomes are easily known, because the precedence for a state that might solve two different transitions at the same time is established by left to right on the table as the table is scanned (could be right to left, but it needs to be defined and repeatable).
Try being totally deterministic in your specification with a chart or UML, you end up having to assign order of execution numbers to each state bubble as a minimum, and it is hard to make intuitively clear the exact behavior that will emerge in edge cases.
But, straight away any impossible state transitions are explicitly excluded and all possible transitions are easily read off the first two rows
The state columns are crossed with rows of transition conditions, which are logic conditions derived from raw inputs. Every square for a transition possibility for any state must have an entry, even if just an X to indicate not allowed or don't care.
Not only that, every possible transition has a unique square (with grid reference if you want) which you can attach a design or user comment to for explaining the reasoning for the selected transition, or for generating an alarm for that transition condition. So even a square with an X might get a comment to explain why that transition was elected not to be valid.
Outputs are driven as a feature of state, as a Moore machine is better intuitively, even though you likely end up with more states. Often the state explosion is vastly improved with hierarchal state machines, the first thing to do is split out modes and states, often giving great improvement.
You then have the basis for an exhaustive and unambiguous definition of a state machine with no implicit state. It can be an executable specification, the tool I have created allows single stepping thru the "scans" of the logic, and generates things like state trace logs etc for debugging while designing.
If you want to specify known state based behavior with no implicit state, this is by far the best available practice, only improved by a further examination by formal methods (TLA+ or similar) of the resulting specification. UML won't get you here, and no methodology of state charts I have seen or can imagine can get to the same place in a comprehendible way.
But, I find the process that the designer is forced to use to create the state machine/s in tabular form like this yields immense improvements over traditional specification methods, which usually focus almost exclusively on expected behavior only and are in the form of the "crappy narrative".
Because the target is industrial safety and control systems I put an OPC server in so the logic could be simulated and hook up to a HMI to test user interaction, if desired.
Final point is the tabular form then also leads to an extremely compact and succinct algorithm for solving that reduces the logic required to handful of bitwise logic operations. Given the maxim that errors are proportional to LOC, this means the chances of errors can be substantially reduced over any other state machine implementation I have seen, by orders of magnitude, something highly desirable for a functional safety implementation.
I have spent years on this and development of the tool, for my own use at this stage. But I am very confident there is no better practice (yet I still wait for the world to beat a path to my door), and it starts with the correct interface to describe the specification, and flows naturally from there. There are hints of similar approaches, some around for a long time, but nothing I have seen that condenses all the dimensions into one 2D table like this and allows it to be executable in it's own format.
It is a little involved to explain, often needing a couple of hours of hours of focused attention. But once people see it and get it, they usually don't want to work any other way.
But I have found a significant portion of my colleagues, who are experienced engineers, just aren't able to grasp the full extents of what it means, why and how to use it or that it can be used to describe fully arbitrary behaviors - first clue is if they do not believe that such a simple basis can describe all wanted behaviors and/or they ask why they have to use the table and why not a chart or UML. UML is just not going to get you there, this way will.
There is a lot more, but I would be surprised if many people have read this far.
But I take my chance to explain the surprising benefits of a particular UI/interface in solving a particular problem and how it flows on. If anyone is genuinely interested feel free to DM me, as I said I have a tool I made in PyQt to enable this workflow. It has been used on design of some large industrial safety systems, some projects with overall value in excess of $1B, but lends itself to any state based behavior.
Virtually everything safety critical (cars, planes, biomedical..) uses Simulink which is not shown or mentioned by this post and it works fine for very large apps.
We don't need visual programming, we need moldable development like Glamours Toolkit but implemented in a language that does not suck.
We'll be back at IDEs that can convert to and from UML in no time :)
One thing to consider for visual programming is whether you are describing data flow or control flow.
Most of the examples where visual programming is working well are either for data flow: shader/material graphs in game engines, compositing and other node based editors in various video,3d,vfx software. Other examples of case where visual programming is used audio software and industrial automation logic - it's similar although here it describes more of continuously evaluated process that all happens at the same time, with some parts potentially being evaluated at different rates instead of simply evaluating whole thing in a loop.
All that is more similar to functional programming. Describing control flow, implies imperative programming. You have to ask why are imperative programming languages more popular than functional ones? I don't have a good answer to this part. The same reason might also be at fault why visual programming isn't more popular, assuming visual programming is better for functional programming.
But why is visual programming bad for describing control flow? It's not like we don't have standard way for doing that. Flow chart style diagrams, is one of the basic tools used when teaching programming. I guess one of the factors might be goto vs structured programing. ~50 years ago programmers realized that arbitrary jumps across the code makes a mess, and it is beneficial to restrict the control flow to few specific patterns. Flow chart style visual programming is more or less goto spaghetti. A disciplined programmer could restrict themselves to the patterns that match with structured programming, but the same could be said about using goto in text based programming languages. Reality shows that unless they are forced, relying on individuals being always disciplined (or knowing what the best practices) doesn't go very well. It's more effective to have a first class support for the preferred structures, and remove or strongly discourage unstructured tools (even though in theory they are more powerful).
With that said structured visual programming isn't impossible. Scratch is somewhat that, but it also shows why at that point it becomes somewhat pointless. You more or less get your usual imperative text program but with additional blocks drawn around. Closer to structured code editing(completely separate concept from structured programming) of text based language than visual programming. There is still bit of hope. All the examples for DRAKON language I have seen, looked mostly structured. Not sure how it's enforced. It does have first class loop structures, but supposedly branching based loops like in the flowcharts are also possible.
Most recommendations for best practices will encourage programmers to limit the control flow complexity within a function, as having too many nested loops and branching will still make the code hard to understand. This makes me wonder about cause and effect. Do we limit the control flow complexity because text based languages are bad at expressing it, or do we use text based languages as a tool to restrict complexity (which is always bad). Or is it just a coincidence that we can use text based languages, because the amount of local complexity that we can comfortably work with fits the limits of text based languages.
One more thought is that the text based programming isn't exactly purely text based. We don't perceive the code as stream of characters, like the computer does.Remove all whitespaces including newlines and it will become nearly impossibly to work with code beyond few expressions. Elements like line indentation and syntax highlighting rely on human visual pattern recognition. So maybe there is a way for more visual manipulation even for languages that strongly resemble our current text based programming languages.
The classic from The Daily WTF:
https://thedailywtf.com/articles/the_customer-friendly_syste...
I'm making two parallel attempts at solving this problem. I have some time on my hands for the next six months.
One serious as part of a long-term research project where I will be relying on some AI techniques to create the UI ( https://youtu.be/sqvHjXfbI8o?si=-PDXQes5i4JglBQj&t=411 ) and one as a game/exploration, kind of multi-layered/dimensional red-stone programming.
The first will be for tiny machine-generated programs linked together. The second is for an abstract physics game which will be for learning, fun, and hopefully some tiny profit on Steam. (Will appear here https://store.steampowered.com/search/?publisher=My64K when playable)
In, both I am adding severe constraints to the VP design but the game one will be the most interesting. I'm looking to add a kind of cellular automata mediated physics that also provides gradual automated optimization. Think programming in Minecraft with Redstone but with multiple dimensions and a regular polygon substrate. The key ideas I am exploring in both are:
1) Can we design a substrate that enforces some order that solves the tangle problem?
2) Within a substrate, can an algorithm be "crystalized" or "folded" into something recognisable by its shape?
Starting next week. Should be some fun coding.
Visual programming isn't a programming paradigm - it's just a way of representing code. The underlying paradigm is the important thing. It should be decided upon first, and only then should the representation be chosen.
In my opinion, the only paradigm that visual programming makes sense for is dataflow. Unfortunately, although there were dataflow hardware research projects in the UK, USA, and Japan several decades ago which resulted in prototypes, there are no hardware datafiow machines (MIMD - multiple instruction, multiple data) today. In these, there would be multiple general purpose processors. Whenever a processor receives all its inputs, it executes an instruction, and sends its outputs to other processors. There is no flow of control, and the order of independent operations isn't determined until run time. So programs, at the lowest level, are directed graphs. The advantage of dataflow is that it maximizes concurrent operations.
The few commercially successful visual dataflow languages (e.g. Prograph, LabVIEW) aren't pure dataflow. The way they handle conditionals and loops breaks the paradigm. In any case, they run on conventional hardware, instead of dataflow hardware, real or simulated. If you design your dataflow language to run on a MIMD dataflow machine, your language would be very different and, in particular, you'll need a way to handle conditionals and loops, which can no longer be control structures, to fit the paradigm.
There are a few languages which stand out as having been particularly well designed for their paradigm - Lisp (particularly the Scheme branch), Prolog, APL, and Smalltalk. All are about as simple as they can be - "Il semble que la perfection soit atteinte non quand il n'y a plus rien à ajouter, mais quand il n'y a plus rien à retrancher." This can and should be done for dataflow, where programs are directed graphs. You can either do this as a visual language with data flowing along edges between vertices, or textually. A visual representation seems more natural, and there's only one right way to do it. With text, you have less than satisfactory choices.
You're not choosing a visual representation because it's easier for non-programmers or anything like that. The decision is imposed on you by the paradigm. If you're dead set against visual programming, you effectively rule out dataflow programming.
Are there any advantages in dataflow programming if the underlying hardware doesn't support MIMD? I have found several: it permits a certain amount of liveness; it makes type inference more straightforward, as the types at each end of edges must match, and type checking can now be done in the editor; function and type definitions, as well as data, can be represented and manipulated as labelled directed graphs, and stored as the textual representation of graphs; and functions can be compiled by the functions themselves, by running them without executing the vertices.
Some of you might remember I've been working on my own dataflow language (https://www.fmjlang.co.uk/fmj/tutorials/TOC.html, https://www.fmjlang.co.uk/fmj/interpreter.pdf). At present I'm improving how the type inference works, and making the language fully homoiconic (programs are stored in the same data structure as other directed graph data structures). This involve a major rewrite of large parts of the code base, which will end up smaller and easier to maintain.
I love the return link from the footnote back to its reference.
I've only seen this done well once. Armory with Blender will actually output Haxe code after you create a visual code block.
If I can't tweak the actual code I don't want it.
With strong, expressive type systems such as those offered by Haskell, Rust, TypeScript, etc... I find that you front-load all of your debugging to compile/typecheck time. Instead of needing to experiment with your code at runtime through either manual or automated (TDD) tests, you are instead having a conversation with the compiler/typechecker to statically guarantee its correctness. There's just as tight a feedback loop with a typechecker as there is with a test runner; you in fact get your feedback even sooner during compile time, instead of during the subsequent runtime.
Where static verification against a typechecker shines over runtime verification against a test suite is that a test suite can only demonstrate the presence of bugs; type systems demonstrate their absence (presuming of course that you understand how to encode certain invariants into your types and don't do some foolishness such as simply asserting all values as `any`).
Type systems in languages like Haskell or Rust are very very very far from being able to "guarantee correctness". They can only realistically be used to specify extremely basic properties of your program ("doesn't have side effects", "doesn't write memory concurrently", this sort of thing).
For any more interesting properties (say "this function returns a sorted version of the input list", or "this function finds the smallest element in the set", or "this transaction is atomic"), you need something like dependent types, and that comes with a hell of a lot more work.
I would like to see improvements in the speed of feedback - particularly from language servers - but the value of those 'basic' guarantees is more than worth the current cost. Unexpected side effects are responsible for almost every trip I've taken with a debugger in any large Java or C++ project I've ever worked on.
I can remember about 20 years ago a colleague getting quite frustrated that a bug he had been looking at for quite a long time came down to someone doing something bizarre in an overloaded assignment operator in C++.
I've seen methods with names like "get_value()" have extensive side effects.
No type system can fix bad programming.
Of course I think we have all seen horrors like that - what I remember was his completely exasperated response not the technical details of the bug.
Complexity is mostly exponentiellt worse in the unknowns and you can not graph what you already know.
The point in the article is that when we read code we need another visualization to change or mental model. I can scan code and find most bugs fast, but when you are stuck a complexity by row/column sure would be handy to find overloaded assignments.
You're missing the most basic utility they provide... that of making sure other code is calling the function with the right types of arguments. That's a lot of coverage over a language without a compile type checked type system.
That's not a utility in itself, it depends on what the types represent to know if this is a useful property or not. For example, a Cfunction which is declared as "void foo(int a)" does ensure that it's called with an int, but if it's body then does "100/a", calling it as foo(0) is allowed by the compiler but will fail at runtime. It's true that that the equivalent Python function (def foo(a)) can fail at runtime when called as foo(0), but also foo("ABC"), but it's a matter of degrees, not kind.
Fair.
However, most people are using stuff like JS and Python. For them even the non-dependent type systems are an improvement.
I agree that one should refrain from ever using "guarantee correctness" in context of type systems outside of Coq & co. But "extremely basic properties" is IMO similarly exaggerating in the other direction.
Take the "basic" property "cannot be null" for example - Considering the issues and costs the lack of that one incurred over the decades, I'd call that one damn interesting.
And Rust? C'mon, its affine type system is its biggest raison d'etre.
While I prefer expressive type systems by a long shot, I would be much more careful about it "guaranteeing correctness".
Types can act as good documentation and as a safeguard for stupid mistakes. But the worst bugs are due to logic mistakes, wrong assumptions or non-foreseen corner cases. Here, either types do not help, or designing the type system is so difficult it is not worth the effort, and makes many future changes more difficult.
In my previous company we used Scala (with and without Spark) for everything, and this setup pretty much allows you both extremes. There was always a middle ground to be found, where types were expressive enough that they were useful, but not too much that they came in the way.
Just encode your business logic in types first! Coq, Idris, or F* will certainly get the job done for you!
/s
Yes, you do if you want to make money on decades timescales instead of some grifter vc 2 year thingy.
Unfortunately you end up selling your stuff to people building missiles and bombs that way—witness CompCert and Frama-C.
It guarantees certain correctness it is having conversations with you about - this way more correct
Yeah, you're not guaranteeing correctness. There's a quote from automated testing discussions that applies here...
Likewise, for a type system, it's guaranteeing the system is correct for the specific subset of "ways it can be incorrect" that the type system covers.
Where I see this fall down, is when you aren't able to learn from the partial code along the way. The sooner you get an end to end setup running where input to the system causes a change to the output from it, the better you are for this sort of feedback. Note, not the soonest you get code to output. The soonest you get users giving input to users getting output.
If you are able to internalize everything, you are constantly simulating expectations in your head on what you are coding. Seeing where your expectations fall down on outputs is a valuable thing.
So, yes. If you fully understand everything already, the "paying it upfront" cost of exhaustive types is good. Amazing, even. Until you get there, you are almost certainly pushing off the feedback of learning where you do not fully understand the system.
I feel like you can partly get around this by slowly increasing type specifically over time. With strong type checking the risk of refactoring is low.
Certainly, but that goes a bit against the idea of incredibly strong types that people often visualize in their mind.
Irony being what it is, most strongly typed programs that I have been introduced to were incredibly tight knots that were not easy to refactor. Many of the restrictions in the types would be far too strong from what was needed by the program, and refactors grow in difficult to explain ways.
This is all to say, the discourse here is fraught with nobody acknowledging that "well done" programs of near any paradigm/style are well done and work. Evidence is often used that languages that allow looser ideas are more numerous than those that don't. This ignores that lack of existing programs in the strongly typed world could also be lack of ability for many people to deliver using those practices at all. Which, in turn, ignores that that may be a trade off that is worthwhile in some industries. (I suspect it goes on.)
Eventual or gradual typing could leave everyone happy.
On the premise of the article, maybe the key to representing a program visually is a very expressive (and strong) type system. There could be a way to derive some Visual Types from good old regular types, and diagram the visual types in any level of granularity one desires.
Instead, gradual typing seems to always make everybody as unhappy as they can get.
Just like visual programming, it looks like we are doing gradual typing very wrongly.
I do not consider neither TDD or tests being about finding or solving bugs. They are about regression and refactoring safety. They are my guardrails for when I must change or add things, or need to discover how something works.
The rest of your comment I found to be a really good point in terms if feedback justification. The IDE checking your code before compile or runtime is faster than both. Good point.
Tests for me also help me write better code. When writing tests, I'm forced to switch from "how do I implement the behavior I want" to "how can this fail to do the right thing". Looking at the code from _both_ of those mindsets helps me end up with better code.
If you use ocaml you get near instant compile times and types, which is excellent for quick feedback.
I am very much of eventual static typing and even proofs for some parts; cl is pretty good and we have a gradual type system in our company for cl. But it’s just faster and easier to build it first and add types later we found (our company is almost 40 years old now).
I don't know what TypeScript projects you have worked on, but every one I have worked on is instant reload all the way down. Rust, on the other hand, is pretty miserable.
I don’t know; I am a programmer but more of a trouble shooter (it makes far more) and projects passing 100k LoC in ts which I see 100s a year, are not instant, in any way. I would love to see one, but I contribute to open source projects, and it’s all slow, very very slow.
I'm working on 250k LoC TS project. It's instant during dev. We don't bundle during dev so the server just has to compile which ever files changed.
Well, I would love to learn how it’s possible: you have a blog or YouTube or something?
Our front end is ~200k LOC of TypeScript and all changes are instant (<1s).
TypeScript compiler is too slow for hot module replacement so it’s used only for IDEs. During development, all transformation happens via esbuild/swc and is abstracted away with Vite https://vitejs.dev/
On what hardware? I have a m3 and yeah, it’s terrible with ts. Instant (milliseconds) with cl (of el even). Go is not terrible.
Same, M3. The DX within a modern frontend stack is indistinguishable from Bret Victor’s ideas (even if a decade late).
Ok, when can we meet? I have never seen it work, and, as said, I review 100s of project a year; everything ts is super slow so far. Maybe you have something.
Their hot reload cycle is fast because esbuild doesn't type check the code, it just removes types from Typescript so it turns into JS (it may do minification and tree shaking but in dev, they probably remove that). I've written some esbuild plugins and can confirm that on incremental builds, esbuild will probably never take more than a few ms even on larger projects (because it doesn't matter how big your project is, esbuild will only rebuild what changed, which usually is a few files only).
esbuild does not do type checking. You must invoke tsc explicitly to do that.
Type-checking is helpful in your IDE (for developer hints) and in your CI (for verification), but you don't want type-checking in your hot-reloading dev loop.
I pointed that out because your previous comment could be misinterpreted to mean you do full type checking on your dev cycle, which you probably don't.
I have a 1,5M LOC game codebase, where both the server and client builds and starts nearly instantly. Probably < 3sec total iteration time just because of typing stuff in the terminal. Build system is just a casual ccache + mold. But you have to do a lot of stuff in the background during startup.
Let’s see it. To not be a total gobshite, go download these things and see what ‘instant’ really doesn’t mean. Instant means not wait 1 second; it means when I type code, it has results in milliseconds. None of these have that.
Or show me a non trivial open source ts project that’s instant; doesn’t exist and I have literally no clue why people keep defending this stuff; you didn’t make it right? I would be embarrassed but definitely not defending it.
https://www.kirandev.com/open-source-nextjs-projects-open-fo...
While I totally agree with you, I'm looking for a counter example. The only one which comes to my mind, is non trivial and quite fast for js/ts is this : https://github.com/tsoding/raycasting An implementation of raycast in a 2D canvas The dev tried to implement hot reloading, and you can see all the process there https://www.youtube.com/playlist?list=PLpM-Dvs8t0VZ08cYW6yqN...
Even though I didn't measured the loading time, an effort has been made to accelerate everything that could be accelerated.
Even the simplest type inference can cause typescript to stall for minutes. The problem is in the inference. That problem goes away when you're actually specifying types. Tooling should add typing automatically (not implicitly)
Minutes? There’s no way you’ve seen a minutes-long stall caused by TypeScript inference..I need to see some evidence on this one
I think that's also true, but not the thing they're writing about.
My experience as an iOS developer has been mixed between places that use Interface Builder and those who create the UI in code. Something like Interface Builder is obviously a great idea for UI creation, which is why it survived so long and why Figma exists, but the actual tool itself (IB) isn't really useful for desigers who want one thing that works on all platforms. (Complaints like "xib and storyboard are hard to use with version control" miss the point; a UI designer shouldn't be seeing git-style text diffs anyway, they need a graphical diff).
Interface Builder is at least 5x faster than making the UI in code; one place in particular, I was making a native app by myself while a whole team was making a web app, and I wasn't simply keeping up with them, I also cought up the headstart they had built while I'd been assigned to a different project. The next place I joined a team and their app was a coded UI, and development was correspondingly slow. (Though how much of this is "teams are slower than solo developers" vs. my hypothesis is unclear to me).
My first coding job was before iOS existed, I was industrial placement student* in an academic research lab, and for that, my guess would be the best option mayhaps have been a mathematical formula WYSIWYG editor that output both latex and IDL.
* does this term get used outside the UK? What's the overlap between this and intern?
Haven't worked with the iOS interface builder but i worked with Delphi ages ago.
Question: how well does the interface builder thingy mix with interface in code?
Can you easily lay out the basics of an UI graphically and then add code where the builder is too limited for what you need?
Or it's the kind where if you start with the graphical builder you're stuck with just what the graphical builder can do?
A quick overview of Interface Builder is Steve Job's demo for NeXT --- perhaps:
https://www.youtube.com/watch?v=dl0CbKYUFTY
where they discuss how dragging/drawing allows one to make 80% of the app, and the balance of 20% is one's own code.
---
A video of historical interest - OpenStep's Interface Builder in 1997, the year Steve Jobs returned to Apple.
It shows how forward-thinking NeXT was. Many of its innovative user interface concepts are relevant and in use today in different guises and interpretations.
In the demo, Steve seems to use the word "object" with a depth of meaning closer to what Alan Kay explained, like independent (or rather interdependent) "cells" of software that communicate to each other via messages.
On the Meaning of “Object-Oriented Programming” - http://userpage.fu-berlin.de/~ram/pub/pub_jf47ht81Ht/doc_kay...
It's interesting that the Interface Builder was considered a "frosting" or visible representation of the underlying objects, which the users more or less directly created, edited, and connected together - without writing a line of code.
That ideal of user experience still hasn't been fully achieved to satisfaction, it feels. The ease and naturalness of creating software visually, as well as with other modalities, senses, medium of expression beyond text.
I'd give a lot to have a graphical development environment which:
- allowed drawing a user interface as naturally as I used to use Altsys Virtuoso (or Macromedia Freehand which I moved to when my Cube stopped working)
- allowed programming the UI as naturally as HyperCard (and to a lesser extent Lisp) "clicked" for me
- was as visual as Google's Blockly (which as BlockSCAD: https://www.blockscad3d.com/editor/ I've used a fair bit)
- exposed variables in a mechanism like to OpenSCAD's Customizer: https://en.wikibooks.org/wiki/OpenSCAD_User_Manual/Customize...
Currently plugging away with OpenSCAD Graph Editor: https://github.com/derkork/openscad-graph-editor but hoping that: http://nodezator.com/ will become a viable option (still a bit bummed that I rolled and crashed w/ https://ryven.org/ though in retrospect, maybe I should try to tie that latter in to: https://pythonscad.org/ )
It mixes well.
Apple has two UI frameworks, UIKit and SwiftUI, and Xcode's Interface Builder handles each differently. The Interface Builder for each is built into Xcode, but the UI they present when editing is quite different — I'm unclear if they're both officially called "Interface Builder" or if people like me stuck with the same name for the new one because it's a thing for building interfaces.
The older system is UIKit, where Interface Builder produces some XML files — .xib or .storyboard — and once those are loaded, they result in objects which are fully manipulable in code.
The newer system, SwiftUI, the source code is the source-of-truth for a WYSIWYG editor — any change made in the editor immediately updates the code, any change in code immediately updates the editor. That said, in my experience at least, this editor falls over quite often if you do that.
Mixes Well is an understatement. I couldn't imagine writing any more than a simple toy app without it. I've experimented with building an iOS UI purely in code, and while it is possible, it is a painful, masochistic, and slow way to develop.
As projects get bigger, things might get sadder. I worked at a certain large SF company that uses a lot of ruby, so most development was repl-based too. But this wasn't a boon but a curse, as the total lack of data format guarantees on the very large, critical monorepo meant a lot of uncertainty. What does this method really do? I guess we have to run it! It worked for this specific input... but will it work for any and all inputs that get to this data path? Let's hope so, because we aren't sure! The company spent massive amounts of money on servers for parallel testing, just so that the suite could run in less than a few weeks. And when you need a large test suite to have a chance, most of the advantages of the REPL vs a compiler have been lost.
Eventually they did the same thing you can do in common lisp: Add so much metaprogramming that doublechecks invariants, it might as well be a compiled language.
I think that OOP done right can address this problem through encapsulation of the logic.
One can make the case that a function can do the same. I agree, but a class is just a container for a set of related functions and state.
The problem with OOP seems to be that as a whole, devs are not that great at encapsulation and isolating domain logic.
The number of codebases I've worked on where developers automatically added getters and setters for all class members is too damn high.
I guess the upside is that you end up with a "compiler" that checks the invariants of your project and that domain rather than strict type safety. I love static typing, but I did try Elixir w/ Phoenix recently and was impressed that they were able to implement compile time checks like verifying that all redirects are valid routes, etc. Depending on what you're building, having a few small domain specific checks like that could be more valuable than strict type safety.
So, paraphrasing:
Any sufficiently complicated Ruby program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Java
Common Lisp has always allowed you to specify types anywhere you want. It's not a statically typed language but it supports types (and SBCL and other impls do static checking where possible).
Honest question as a java lover-- do rust and TS have slow compile times or something?
Because java has a robust type system and yet I've never had any issue with it's compile times. And the parsing in the IDEs is so fast and good I can pretty much get all the feedback in real time.
Ah, that's the luxury of using a battle tested language that other people have invested billions of dollars of effort into optimizing.
Do you guys not have that in Rust and TS? Bummer man. Hope you get there someday. This is exactly why I abandoned scala btw.
Yes - Rust has pretty slow compile times. It is perhaps my biggest gripe with it.
You might define java as having a robust type system, but I would rate Rust's as significantly better. Several things in Rust I miss when working in Java:
* Monomorphized types
* Sum type and product types. Think sealed classes in java, but with better ergonomics
* A really clever type system that prevents things like ConcurrentModificationException and data races (not dead-locks or race conditions generally though).
Though, IIUC, Rust made early decisions about module structure that have really hindered compile speed, not necessarily tied to the type system.
Another big factor that makes rust slow would be optimizations & slow system linkers; it doesn't have a JVM that can warm up to optimize stuff.
Source: work with both Rust and Java on a daily basis.
Edit: The way the type system works out in general makes me far less worried about making sweeping changes in a Rust codebase than in a Java codebase, but there are still logic bugs that I miss occasionally. Still, it moves quite a big bug finding from "run the program and see" to "make it pass typechecking", which is quite a bit faster than compiling; you can typecheck Rust without compiling it.
Making your compiler fast is easy when it doesn't do any work. The Go one seems to be even faster than Javac.
In my experience Rust still compiles as fast as I need it to (other than for the very first fresh compilation) and using language servers / rust-analyze I get literal instant feedback in vscode as I hit save. Not to mention autocomplete...
Typescript is pretty fast no? I've worked on the VSCode codebase a fair bit and the intellisense seems pretty fast. Like under a second, which is fine.
You don't need to resort to Lisp to get instant feedback. Try Dart - it's basically instant.
Rust I will give you...
Agreed, I just prefer lisp. We use flutter a lot, but we do it in cl -> dart; it makes everyone here (again taste, not gospel) happier.
What do you use to compile CL to Dart? Or you compile to JS?
As a fellow ancient person my only consolation is that the browser-based development experience most people now learn on is (with some path-dependent ugliness) basically the experience Smalltalk promised us in the 1980s and never quite delivered.
I'm confused? Smalltalk promised image based development where you could change things on the fly. That is far from what I typically see in browser based development.
I’ve got a 500 file, 100k sloc typescript project with instant feedback which makes me wonder: what is a large project?
Are most people somehow working on giant repos?