18 replies
22h43m
I wonder how this would compare against a random sample of jobs on, say, Indeed or LinkedIn. My experience of Hacker News is that it’s a very biased group (in a good way) to the general industry.
I wonder how this would compare against a random sample of jobs on, say, Indeed or LinkedIn. My experience of Hacker News is that it’s a very biased group (in a good way) to the general industry.
Any chance you could run a comparison of the number of Rust vs Golang jobs over time?
I seem to have noticed that Rust has gotten more common than golang in the job postings, but it's hard to verify without code because there are so many false positives for "go" on any post.
Using a 100 billion parameter LLM to `grep --count` surely is something
Read the second part of what they said
it's hard to verify without code because there are so many false positives for "go" on any post.
Hence grep being insufficient in this case.
You can’t really trust that the LLM gets it right either, though.
It didn't. As noted elsewhere, there the bubble cloud has Vue.js and "Vue Js", among others.
Using a 100B parameter LLM to overcome the large amount of experience required to learn how to do natural language processing one's self rather than using a library to do it sure is something.
I should write a bot to analyze users and hide those who are actively and regularly negative online or on a particular forum and hide their comments.
I should write a bot to analyze users and hide those who are actively and regularly negative online or on a particular forum and hide their comments.
Yes, please! I'd sponsor this work if you want donations.
A browser plugin would be even better.
I want to filter out (or at least highlight): ads, sponsored content, clickbait, rage, negativity, trolling, crypto (much of it anyway), assholes, rudeness, politically partisan, spam emails, etc.
If this could work on every website, and eventually every pane of glass (phone, etc.), it would be truly magical and absolutely game changing for the trajectory of the internet.
I want more signal and less negativity. And fewer people trying to sell me on things (unless those things are interesting ideas).
This is the correct way to fight the algorithm and the walled off platforms.
There's 3 matches for " go " on this page (before writing my comment) but only 2 of them pertain to GoLang.
Can't wait to be able to run this locally using electron.
While this made me laugh and there is some truth to it, the nice thing when running the process described in the blog post is that you don't need to know what or how you want to count - the LLM has the knowledge to classify it correctly enough to get good estimations. Go and Rust are both good examples of words that have multiple meanings and are pre-/suffix to many other words.
It's not doing that though, and if you'd done classification tasks you'd realise the huge benefit that comes from taking a computationally expensive system and using it to solve one off problems that were very time consuming, and doing it easily.
The article says it cost ~$50. That's astonishing. That's 25 minutes of my billable time.
-
how do you create these perfect tables with just text?
In total numbers I got 539 jobs saying that they want Rust experience and 695 want Go experience. I think I should have added another line-chart showing the programming language distribution over time, thanks for the idea.
Thanks for looking this up. It's especially interesting bc if I search "golang" on LinkedIn jobs, I see 5,185 results (in the US), but I only get 148 results for "rust".
Hardly scientific, but shows the risk of using Hacker News to draw overly strong conclusions of language popularity.
We need LLMs for this?
I'm more interested in technical side of this, but I'm not seeing any links to GitHub with the source code of this project.
Anyway, I have a tangential question, and this is the first time I see langchain, so may be a stupid one. The point is the vendor-API seems to be far less uniform than what I'd expect from a framework like this. I'm wondering, why cannot[0] this be done with Ollama? Isn't it ultimately just system prompt, user input and a few additional params like temperature all these APIs require as an input? I'm a bit lost in this chain of wrappers around other wrappers, especially when we are talking about services that host many models themselves (like together.xyz), and I don't even fully get the role langchain plays here. I mean, in the end, all that any of these models does is just repeatedly guessing the next token, isn't it? So there may be a difference on the very low-level, there my be some difference on a high level (considering different ways these models have been trained? I have no idea), but on some "mid-level" isn't all of this utlimately just the same thing? Why are these wrappers so diverse and so complicated then?
Is there some more novice-friendly tutorial explaining these concepts?
[0] https://python.langchain.com/v0.2/docs/integrations/chat/
You really don't have to use langchain. I usually don't except on a few occasions I used some document parsing submodule.
The APIs between different providers are actually pretty similar, largely close to the OpenAI API.
The reason to use a paid service is because the models are superior to the open source ones and definitely a lot better than what you can run locally.
It depends on the task though. For this task, I think a really good small model like phi-3 could handle 90-95% of the entries well through ollama. It's just that the 5-10% of extra screw ups are usually not worth the privilege of using your own hardware or infrastructure.
For this particular task, I would definitely skip langchain (but I always skip it). You could use any of the top performing open or closed models, with ollama locally, together.ai, and multiple closed models.
It should be much less than 50 lines of code. Definitely under 100.
You can just use string interpolation for the prompts and request JSON output with the API calls. You don't need to get a PhD in langchain for that.
Well, I mean, it appears langchain just technically doesn't support structured response for Ollama (according to the link above). But, as I've said, I have absolutely no idea what all this middle-layer stuff actually does and what may be the reason why different vendors have different integration capabilities in this regard.
I'm totally new (and maybe somewhat late) to the domain, literally just tried right now to automate a fairly simple task (extracting/guessing book author + title in nice uniform format from a badly abbreviated/transliterated and incomplete filename) using plain ollama HTTP-API (with llama3 as a model), but didn't have much success with that (it tries to chat with me in its responses, instead of strictly following my instructions). I think, my prompts must be the problem, and I hoped to try the langchain, since it somehow seems to abstract the problem, but saw that it isn't supported for a workflow the OP used. But since this is a field where I'm really totally new, I suppose I also may be making some more general mistake, like using a model that cannot be used for this task at all. How would I know, they all look the same to me…
Ollama project itself is fairly stingy with explanations. Doubtfully there are many people out there trying to automate an answer to the "Why is the sky blue?" question.
So, I wonder, maybe somebody knows a more digestible tutorial somewhere, explaining this stuff from the ground up?
1. Use temperature 0. Anything over that is asking for randomness, which not useful unless you actually want it to say something random rather than following instructions.
2. Use the best/largest model possible. Small models are generally stupid. phi-3 might work as an exception of a very well trained tiny model. Very large models are generally dramatically smarter and better at following directions.
3. Tell it to output JSON and give it examples of acceptable outputs.
4. The API for OpenAI and Anthropic is very very similar to ollama. The models are vastly better than llama3 7b. You can basically make some minor modifications and if you have the temp right I bet it will work.
Personally I think that langchain will just make it more complicated and has nothing to do with your problem, which is probably that you used a tiny rather dumb model with a higher than optimal temperature and didn't specify enough in your prompt. The biggest thing is the size and ability of the model. Most models that will run on your computer are MUCH MUCH stupider than ChatGPT (even 3.5).
Temperature 0 will not prevent randomness, only reduced it. I addition, there may be times when temperature > 0 is essential for reproducing the text accurately. Consider a model with a knowledge cutoff 3--6 months out of date and trying to write e.g. a model name which did not exist when the model was trained. In that case temperature 0 will make it more likely to fix your code by replacing the model name it's never heard of with one more likely according to the model training data.
In other words, if the text you want was not in the model training data, a higher than normal temperature may be required, depending on how frequently the term appears in the input data. If you provide a few samples in the input, then you may be able to use 0 again.
Right, temperature only controls the distribution of tokens, not answers - for many use cases, the “same” answer can be represented with many different sequences of tokens. If you consider the entire space of possible input texts, at temperature=0 some model outputs are going to be “wrong” because the single most likely token did not belong to the set of tokens corresponding to the most likely answer (of course it’s also possible that the model didn’t “know” the answer, so temp>0 only helps in some cases). Temperature > 0 increases the likelihood of a correct answer being given in those cases.
The problem with generating structured output like JSON is that temperature > 0 also increases the likelihood of a token belonging to the set of “wrong” answers being chosen. With prose that’s not the end of the world because subsequent tokens can change the meaning. But with JSON or code, the wrong token in the wrong place can make the output invalid: it’s no longer parseable json or compilable code. In the blog they were also generating bools in one spot, and temp > 0 would probably result in the “wrong” answer being chosen sometimes.
For that reason I’d suggest generating JSON fields independently and then create the full JSON object from those outputs the old fashioned way. That way different fields can use different temperature settings. You’d probably want temperature=0 for generating bools/enums/very short answers like “New York”, and temperature > 0 for prose text like summaries or descriptions.
You can run llama.cpp and structured output with GNBF. There are tools to convert JSON schema to GNBF.
This won’t directly answer your question, but it hit the front page here a while ago and I think you may enjoy it:
https://www.octomind.dev/blog/why-we-no-longer-use-langchain...
Why we no longer use LangChain for building our AI agents
https://news.ycombinator.com/item?id=40739982 (14 days ago, 300 comments)
Thanks. Indeed, it doesn't directly answer my question. For one, the author seems to be failing the "Chesterton's fence" test here: it doesn't even try to answer what langchain is supposed to be good at, but ends up being bad. It just plainly says it's bad, that's all.
And, as stated, I also don't know the answer to that question, so this is kinda one of the primary concerns here. I mean, one possible answer seems pretty obvious to me: it would be better to keep your app vendor-agnostic (to be able to switch from OpenAI to Anthropic with 1 ENV var) if at all possible. Neither of articles and doc-pages I've read in the past few hours tries to answer to what extent this is possible and why, and if it even is supposed to be a real selling-point of langchain. TBH, I still have no idea what the main selling point even is.
Honestly, langchain solves no problems besides being an advertisement for langchain itself
It gets picked by people with more of a top-down approach maybe, who feel like adding abstraction layers (that don't abstract pretty much anything) is better. It isn't
Yeah langchain is not necessary for this. The author appear not to have shared his code yet (too bad, the visualizations are nice!), but as a poor replacement I can share mine from over a year ago:
https://github.com/m3at/hn_jobs_gpt_etl
Only using the plain OpenAI api. This was on GPT-3.5, but it should be easy to move to 4o and make use of the json mode. I might try a quick update this weekend
This should have "Show HN" tag Also you don't have to use selenium or HN api - there are DBs with updated HN data
Show HN is for things someone has made that other people can try and this is a write up which is perfectly fine as it is - https://news.ycombinator.com/showhn.html
To post, submit a story whose title begins with "Show HN".
I'm not sure what you mean by that. Most reading material is just fine as a regular post and can't be a Show HN, thats very near the top of the thing I linked:
On topic: things people can run on their computers or hold in their hands. For hardware, you can post a video or detailed article. For books, a sample chapter is ok.
Off topic: blog posts, sign-up pages, newsletters, lists, and other reading material. Those can't be tried out, so can't be Show HNs. Make a regular submission instead.
Things that can't be Show HN can be perfectly fine regular HN posts, just like this thing already is.
Please don't use HN primarily for promotion. It's ok to submit your own stuff occasionally, but the primary use of the site should be for curiosity.
I don't know, 0 posts and two comments, first post with self promotion right away. I had a feeling it's not allowed, oh well
I'm completely confused here, sorry. Are you talking about this submission? People submitting their own work with their first post is totally fine, especially if they're around to talk about it. These are some of the best threads HN has to offer, often. The guideline is about not using HN to post your own stuff exclusively but it's, you know, a guideline rather than a mathematical constraint so the trivial case of posting your own stuff on HN for the first time is not merely fine, it's a good thing.
Edit: Maybe I'm figuring it out, is it that you thought that self-posting is strongly discouraged and that 'Show HN' is a label you're supposed to use to identify self-posting? They're not directly related, Show HN is just a special HN category with its own subsection and its own extra rules. Nobody has to use it but if you do use it, the post has to be within those rules. The other, somewhat orthogonal thing is that you can post your own stuff (in or outside Show HN), just don't overdo it.
Could you maybe link me one of those? I've googled a bit but didn't find ready-to-use DBs with that data.
Thank you, looks promising.
It's handy but I think for your use case, the regular API works fine. For instance, you could have just pulled all the whoishiring posts
https://hacker-news.firebaseio.com/v0/user/whoishiring.json?...
without the googling hoops. Not that this is very helpful after you're done!
https://news.ycombinator.com/item?id=40782787
Also the clickhouse dataset, which is free.
Google BigQuery can become very expensive.
This is very neat! Thanks for using your time and literal dollars to work through this!
As an added detail regarding the "remote" v "in-person", another interesting statistic, to me, is to know how many of those in-person job-seeking companies are repeats! It could absolutely mean they're growing rapidly, OR it could mean they're having trouble finding candidates. Equally, missing remotes could mean either they're getting who they need OR they're going out of business.
All interesting plots on the graph!
We're a growing B2B company in Norway. We struggled for years to fill in-person positions. We've been at least 2-3 devs short for the past 6+ years.
That is, until December last year. Then it was like a flood gate had opened up. Suddenly we had tons of candidates to try to select from.
I knew things were bad over in bay area and such, but I didn't expect it to hit the market over the pond here so quickly and abruptly.
It is getting more and more apparent that BLS has been cooking jobs numbers.
I don’t understand the downvotes. Chairman of the federal reserve stated that jobs are overstated.
https://www.federalreserve.gov/mediacenter/files/FOMCprescon...
You got downvoted for saying that BLS is intentionally lying about jobs numbers. That’s what “cooking” means in this context and it is a big accusation.
The Fed chair’s statement you cite doesn’t support it. He’s just saying that the jobs numbers may not be perfectly representing the actual job market. That is not exactly news; it’s a very hard thing to measure. He’s not accusing the BLS of lying.
Check the revisions from BLS over the past year. BLS revised down both April and May numbers by 30%. These are big revisions. This is a pattern now. Media only reports the initial figures.
Here’s what the chairman of the federal reserve actually stated about payroll numbers:
there’s an argument that they may be a bit overstated
Not one, not two, but three qualifiers[1] that you left out of your retelling.
[1] “there’s an argument,” “may be,” and “a bit”
It is more nuanced than that. The BLS and ADP jobs report numbers sometimes diverge significantly. This is explainable by differences in how the data is sourced and modeled.
Roughly, BLS accurately reflects government employment and then extrapolates to the private sector using a census model that can be several years old. ADP is private sector data and doesn’t reflect government employment. They are essentially sampling disjoint employment pools which leads to some known artifacts.
Sometimes there are large spasms of government job growth through expansion of spending and jobs programs when there is no matching growth in the private sector and the private sector may actually be declining (as seen in ADP data), yet BLS will extrapolate that the private sector must have similarly grown based on the government growth data. Similarly, ADP is generally considered a reasonably accurate model of private sector job growth but doesn’t account for government employment even when it is substantial. ADP can significantly exceed BLS in boom markets.
A heuristic that has been around forever for tracking “productive employment” is that the job market is good when (ADP - BLS) is a positive number and bad when it is negative. Currently, this heuristic is tracking at something like -100k to -150k, which indicates a poor job market.
This kind of input is exactly what I've hoped for submitting it here, thank you. I agree!
https://tamerc.com/posts/ask-hn-who-is-hiring/#what-javascri...
"Node.js" and "NodeJS" are drawn as separate spheres, is that intentional? Similarly for "Vue.js" and "VueJS". (Maybe the same for "Angular" vs "AngularJS" too, although the former might be referring to Angular TypeScript).
AngularJS support has officially ended as of January 2022. Angular is the actively supported "version".
My vague memory of this is that AngularJS from v1 to v2 was such a huge difference (and arguably some percentage of the community qualify this update as a colossal f up), that they decided to go with a different name, and they also came to their senses and their backwards incompatible changes are no longer so bad.
I’m convinced Angular’s adoption of RxJS for HTTP requests was a cunning move to cement job security.
I saw express and express.js in the bubble chart
Thanks, is fixed now.
Angular and AngularJS are distinct from each other; the other pairs are not.
Nit: There appears to be both a "React Native" and a "React-Native" bubble in the JS framework graph.
there's also a Node.js and NodeJs
Both fixed now, thanks.
Also perhaps MariaDB and MySQL should be joined together as well.
Also SQL Server and MSSQL
There's also gaps in the labels on the database chart.
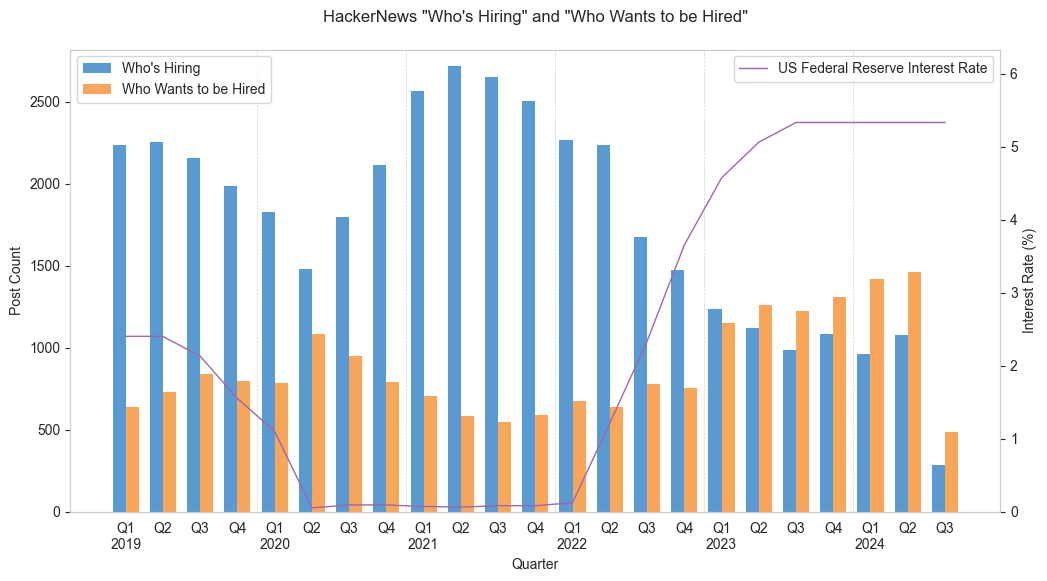
Nice work, OP. Looking at the graph, I sure hope we did not hit "Peak HN" in Q2 2023.
IMHO, I believe the peak was due to a combination of Zero Interest Rate Policy (ZIRP) and the pandemic, both of which have faded out this year. Elon Musk's highly publicized firing of a big part of the Twitter work force also set a precedent for lay-offs in the industry. But I am still optimistic that we will many such peaks ahead of us.
Elon Musk's highly publicized firing of a big part of the Twitter work force also set a precedent for lay-offs in the industry
Layoffs across the industry were already well underway when Musk completed his first round. I think some tech company execs were happy to use Musk as a high profile excuse, but investors everywhere were demanding layoffs/corrections as early as Summer 2022.
yep it was the bad economy, not to worry it will improve next year.
But I am still optimistic that we will many such peaks ahead of us.
I'm not. But I don't think my industry is too represenative on what affects HN hirings. I've seen maybe 5-ish game positions on Ycomb job boards ever (they don't even have it as a category to filter into).
I'm just waiting out React, using my own much cleaner SPA framework for the last 10 years that's only about 5k LOC and avoids a lot of debouncing and fragmentation issues. From that three.js diagram, it looks like React should turn into a red giant at any moment. Can't wait.
React has already jumped the shark, people just haven't realized it yet. The backlash will be big. I think most people will jump to Preact or Vue.
The standard tech cycle:
1. Awesome new tech,
2. Tech gets more and more popular,
3. Tech gets more and more features to better cope with new use cases,
4. People get sick of bloat and create awesome new tech to replace it,
5. Go to 1.
The fuse is now lit for lots of apps currently working fine in production to be suddenly labelled 'legacy', and nobody wants to work on the crusty old React or (heavens to Betsy!) Angular anymore.
In 5 years time earnest conversations will be had about trying to find somebody who is willing to maintain the thing, or do we have resource for a complete rewrite?
More details are welcome. React seems to be doing fine and why Preact and not Solid for example?
I think it's bad to stack bars in a graph, because it means you can't properly gauge the second layer (for example, the remote jobs quantity, at the beginning of the results section). Better to have two bars side by side (for each timestamp), one for remote, and another for not remote.
Stacked bars are the right choice when you care more about the magnitude of the sum and less about the precise relative breakdown. Separate bars are the right choice when you're comparing multiple things that are similar and their combined magnitude isn't meaningful.
Could you have a the separate bars and a total line to capture both?
Yes, but it's busier/less information dense, so it's not a straight upgrade.
At least he does have remote jobs percentage on the same plot. But this is always the problem with plots. They always show what the author wants to show, not necessarily what the reader wants to see. I've often dreamed of a document format that embeds the data and allows the user to easily select the plot themselves. In this case you'd at least be able to toggle between stacked and side by side, but you might even prefer different bins or a different plot entirely.
Using Selenium, I used a script to google iteratively for strings query = f"ask hn who is hiring {month} {year}" to get the IDs of the items that represent the monthly threads.
FYI, you could've just used the hackernews API, and get all posts by the user `whoishiring`, which submits all these who is hiring posts. And then filter out only the posts where the title starts with "Ask HN: Who is hiring?", as this bot also submits the 'Who wants to be hired?' and 'Freelancer? Seeking Freelancer?' posts.
https://hacker-news.firebaseio.com/v0/user/whoishiring.json?...
This makes just so much sense and would spare me 65 lines of code. Thank you!
Also NER would have done a better job imo
Also if you want to manually browse them, look at https://news.ycombinator.com/submitted?id=whoishiring
No worries! Btw in your database graph "Snowflake" seems to be off by two positions, as it has a smaller count than ElasticSearch and ClickHouse, but appears in front of them.
This seems like a great blend of LLM and classic analysis. I've recently started thinking that LLMs (or other ML models) would be fantastic at being the interface between humans and computers. LLMs get human nuance/satire/idioms in a way that other NLP approaches have really struggled with. This piece highlights how ML is great at extracting information in context (being able to tell whether it's go the language or go the word).
LLMs aren't reliable for actual number crunching though (at least from what I've seen). Which is why I really appreciate seeing this blend!
I would say they're very bad at inferring any sort of complicated nuance.
So we win the war against the machines with sarcasm, irony and double meanings? That would be one hell of a shitty Terminator movie.
I've recently started thinking that LLMs would be fantastic at being the interface between humans and computers
Join the club :) I'd say that's a pretty mainstream idea right now.
Exciting nonetheless
Surprised to see Redux featured so prominent in JS frameworks section, since it is so often criticized while many praise newer competitors like Zustand.
From my experience some of these companies that are already using new state libraries still have code in older libs like Redux and it's important for them to hire candidates that understand how they work since they changed the way you think about state, and if you understand that it's very likely you'll understand the other ones.
It is really common for both Redux and React to be mistakingly labelled as frameworks by the people who don't really understand that these are libraries providing specific narrow piece of functionality leaving the architectural decisions and the overall application structure up to the developer.
Chat GPT seems to have statistical awareness of this fact, yet people generally choose not to figure it out
or Jotai!
What a great write up - thank you.
Someone in NYC give this person a job! ^_^
GPT-4o is not a person.
Did GPT-4o do the write up?
Maybe
Cool analysis with GPT-4o! I was doing some messing around with the same dataset recently around the "Who is Hiring" and "Who wants to be hired". Although I was just using pandas and spacy. (I was job supply and demand with the US FED interest rates here: https://raw.githubusercontent.com/bobbywilson0/hn-whos-hirin...)
I can actually see how nice it would be for an llm to be able to disambiguate 'go' and 'rust'. However, it does seem a bit disappointing that it isn't consolidating node.js and nodejs or react-native and react native.
I'm curious on the need to do use selenium script to google to iterate, here's my script: https://gist.github.com/bobbywilson0/49e4728e539c726e921c79f.... Just uses the api directly and a regex for matching the title.
Thanks for sharing!
This seems to have a similar problem in the Apple notes calculator where items that you set to as a variable in the new calculator mode can’t have spaces or any other delimiters.
The training data or some kind of enrichment of the data would have to make the systems understand node.js and nodejs are the same just like on the new notes calculator Apple-sauce = $2.50 * 8 makes the first statement a variable.
I've been working on similar functionality for jsonresume -> https://github.com/jsonresume/jsonresume.org/blob/master/app...
What the author could have done, and what I should have (but didn't) also, is add a bunch of possible values (enums) for each possible field value. This should solve it from coming up with variations e.g. node, nodejs
In zod/tooling it would look like this; remote: z.enum(['none', 'hybrid', 'full']), framework: z.enum(['nodejs', 'rails']),
But this just shifts the problem further down, which is now you need a good standard set of possible values. Which I am yet to find, but I'm sure it is out there.
On top of that, I am working on publishing a JobDescription.schema.json such that the next time the models train, they will internalize an already predefined schema which should make it a lot easier to get consistent values from job descriptions.
- Also I tend to forget to do it a lot recently in LLM days but there are plenty of good NER (Named Entity Recognition) tools out there these days, that you should run first before making robust prompts
Interesting that the job supply is highly co-relevant to interest rate. Thanks for sharing.
HAS TO BE A BOOLEAN VALUE!
How we can have a world where this statement exists, and anyone is bullish about LLMs?
The lack of precision is appalling. I can see how a gpt-4o can be fun for toy projects, but can you really build meaningful real-world applications with this nonsense?
Yes, I have built many. Also, have you met any humans? What about their lack of precision?
OMG have you forgotten why we got up to our asses in computers in the first place??
Ah right, humans are notoriously wonderful communicators and seldom have issues sharing ideas or making contracts with each other.
Once bank of america and every other banking app hooks up one of these to my accounts, i better not have to dispute a charge with "HAS TO BE FRAUD, REALLY!"
Interesting data, but I think the percentage of remote listings is misleading. Many “remote” jobs now require you to live within commuting distance of a particular city, usually SF or NY.
I agree, I've realized too late that I should have introduced a "Hybrid" category in this.
Another thing to improve this, is to ask posters to add GLOBAL_REMOTE, COUNTRY_REMOTE or something that indicates is not local remote only (within the same country).
I would add one more category.
Beyond the in-office and the N-days-a-week-hybrid, you have within _actual_ remote roles:
- Country remote (mostly for taxation/regulatory)
- Time zone remote (remote first companies but constraint to within 2 or 3 hours of HQ time zone)
- Anywhere remote (actual remote but often as a contractor or EoR)
I really like the graph at the 'what javascript frameworks are in demand?' part. Any insight to share about that?
Honestly I would just prefer to see it ranked as a table or similar to the databases on.
Yes, later this week I will follow up with something to tell a little bit about the animation and the sphere positioning, that graph was kind of the most fun in writing this blog post. Thank you for your feedback!
Nice charts, which lib? I'm on mobile currently and can't easily dig any deeper to answer my own question
Chart.js is mentioned 1000 words into the article, and three.js is mentioned 1100 words into the article.
Chart.js (with the geo plugin for the choropleth chart) and three.js for the bubble-chart.
The irony of using a chatbot to gain insight into the current problems with the job market
Are you saying you think chat bots are the current problem with the job market?
Maybe you can ask ChatGPT to analyze his comment for you.
"...so the only way to make this diagram not look ridiculous would be to use a logarithmic scale...as I have just realized some minutes earlier. Instead I’ve spent two hours to build a bubble-chart in 300 lines of code with three.js"
Been there. Hackers will do what hackers will do.
So funny to see the results presented as animated circles! But really good too. I guess it presents the data as sqrroot(x).
It would be interesting to run this same analysis using Claude 3 Haiku, which is 1/40th of the price of GPT-4o. My hunch is that the results would be very similar for a fraction of the price.
I was thinking the same, would love to hear the author's reasoning for going with gpt-4o. In my experience, anything above gpt-3.5-turbo is overkill for data extraction.
It is not comprehensive to compare actual JS frameworks and UI/state management libraries. Obviously React will eclipse the frameworks since it is a simple interface library used by the frameworks themselves (like Next.js or React Native)
Also seems a bit silly to include the JS runtime itself in comparison with the JS frameworks. In fact it is almost 100% of the time used along with a front-end framework/library at least on a build-level. I would not put a ton of trust in that frameworks demand data ;)
Yes I also noticed nodejs is included in comparison with the JS frameworks.
If Tamer is reading this, I know of opportunities in NYC for sharp ML people. Feel free to drop me a line at b7r6@b7r6.net and I’ll be more than happy to make an introduction or two.
NYC clearly doesn’t have the level of activity in this area that the Bay does, but there’s a scene. LeCun and the NYU crowd and the big FAIR footprint create a certain gravity. There’s stuff going on :)
I'd hire him if the conversation for the last question I asked went something like this.
Me: On your first day of work, what would you say to me if I asked you to do the samething in your writeup but in production and at scale using the same third party services (chatgpt etc) you used in your writeup.
T: "You're an idiot. I quit."
Me: You're hired!
Clearly it's a fun exploratory excercise, kind of like using kafta instead of a db for the main store for a crud app just to see how it works. But if you asked a senior engineer who follows the sector he would probably guess all the answers correctly blind. Tamer himself says it was his most expensive sunday hobby night. Now scale that uselessness to enterprise level. And you're not even sure if some of the results are hallucinated.
Is 10,000 comments a large enough sample size to gain insights from?
If you read TFA then you will see the answer is yes. Not deep insights though, it is basically just keywords and a few numbers.
I think bytes is generally a better metric than number of entries, naturally 10,000 books will have a lot more insight than 10,000 one-liners.
Great analysis! The only thing I'd suggest changing is how the salary distribution is represented—a simple histogram might present it more effectively. Also, would you consider publishing the dataset you scraped?
Very cool idea indeed. Love the creativity level.
Really cool.
I’d love to see a similar analysis to “Who Wants to be Hired”. What trends exist in folks struggling to find work? That can help point people to how to target their career growth.
So, 50+ bucks to learn React+Postgres are good enough to find a job, cool.
Beautiful analysis! Great to see the hard stats on the technology breakdowns on the hiring threads with a clever LLM approach. And the write up was super clear.
Crazy, didn't know that React is so important! Well done!
Very interesting, I did something similar but in reverse, looking at who wants to be hired.
I only used OpenAI to determine location and then some (failed) analysis of candidate’s HN comments. The rest of the tools I wrote didn’t need LLMs (just string matching).
Given the high price due to high token count, I wonder how different the results would be running the same analysis with a local model.
Great post, thanks for sharing.
Nit: There appears to be both MongoDB and Mongo in the database graph.
Also, could you do a write up on how you actually used GPT-4o to assist you in this exploration? Or share some of the main prompts you used? Thanks!
{kind=link}
I've heard that many of the jobs posted on general jobs boards like that are never intended to result in a hire. They are posted when the company already knows who they are going to hire, but are legally obligated to post the position, or when the company wants to manufacture evidence that "no qualified candidates" could be found locally.
I’ve never heard of this outside of government contracts that require n+X. Is this a visa related workaround or what?
Or is it just chatter from the grapevine?
I can tell you that when I moved from a contract position to full time at Dell Services (now NTT Data Services), they had to review and possibly? interview 2 additional candidates despite hiring from within.
We did have many work visa employees though.
We worked with Healthcare clients. Big ones.
Could be visa-related, it's very easy to craft a posting that only your already-identified preferred candidate will qualify for. I firsthand know of companies that did this for H-1B employees.
Or any public sector job where positions have to be posted but you already have your internal hire, son-in-law, or cousin lined up.
But, it's mostly just rumor I've heard.
H1B visa workaround. Companies have to show that there are no qualified US candidates before they are able to use the H1B visa process. But there have been many abusers of the system. https://www.utahbusiness.com/systemic-abuse-of-the-h-1b-lott...
H-1B visas. To convert to a green card, you need to demonstrate a labor shortage, and a common way is to post job openings, look at the candidates, and tell the government "They all sucked compared to the guy we currently have."
If they don't suck, the guy fails the labor certification and may have to wait a year to apply for the green card again. However, he doesn't lose his job, and the qualified candidate never gets an interview.
So yes, it's pretty standard for the companies to post openings they don't have.
But I really doubt they post on the HN jobs board. Most will go through more formal channels.
I would say that's more prevalent in HN. A lot of the "Who's Hiring" posts are veiled show-and-tells. Some of those companies clearly have no intention of hiring. Even got an automatic rejection email from one of those (within a minute of applying). To be fair, it does work - I've discovered some interesting startups and market niches from the Who's Hiring threads.
As an opposite data point, when I was looking for a job I interviewed with multiple companies that I found on HN who is hiring. And one of them ended up hiring me. Two years later I work for them still.
Interesting. I hadn't considered that angle, and my expectation was that this would be less prevalent here.
There's usually tells that it's a compliance post.
Used to be very specific instructions about mailing a resume to an address with a reference number. And advertised only in the newspaper. But Immigration said they can't do that one anymore; has to be the same submission methods (email, webform, whatever) as an actually open position and advertised/listed in the same places too.
But they'll still have the other tells, which is very specific experience and education requirements which happen to line up exactly with their preferred candidate. Sorry, we did our best, but we can't find any local candidates with a 4 year BS degree, a minor in Clown Studies, and 3 years experience with very specific software that isn't used many places (experience most likely obtained at the hiring company during internship or while on OPT; or while on H1-B if this is in support of a green card, rather than in support of H1-B).
Yes, but I doubt they use the HN jobs board for that. In fact, it will hurt their chances. They can simply post on a very generic job board (e.g. Monster) and say no qualified candidate applied.
The HN job board is much more likely to produce a qualified candidate.
I've had few interactions with HN crowd as I've posted my availability for consulting/freelancing and I feel like I don't like the bias.
People needing freelancers for few weeks/months to complete projects where the requirements are glueing the usual APIs and solving the usual Safari bugs asking me Leetcode questions are out of their mind.
I am not applying for a full time position, I'm not a cofounder that is going to make or break your startup and no sorry I am not sharing your vision/mission whatever.
Discord is by far better for finding work in your domain and related to technologies you like, and you can ask for much more money because people already know you're experienced on the topics you share on that discord.
Mind to share the discord server/link?
I’m currently working with tamagui. I interact with their discord a lot, helping people troubleshoot or asking questions. I’ve gotten a few offers to consult through that alone.
Pick a framework or library, get involved.
I assume there are specific Discord servers per ecosystem? How do you find those?
My primary domain is functional programming and effect systems (effect/zio/rio) related, all of those communities have plenty (even too many) gathering places that are one google search away or the related libraries (for me would be effect-ts, typescript and some other microsoft tooling) have official discords linked on GitHub or docs.
Another good source of work are local meetups/communities chats.
I've tried to interact on a variety of gamedev discords, and the results are about as dry as LinkedIn. But I suppose probing based on the 2020's market won't garner typical results. (still, open to checking out any suggestions. Far from a census here).
Money, though... ha. Less money and usually very few VC's so you're taking a hit compared to trying to grind interviews with EA/Activision. But that's games for you.
definitely a skew here, yes. You'll get about the same web dev role demand, but it feels like there's more of some deeper domains here (embedded, compilers, etc) and less of other domains (games, IT).