98 replies
1d10h
box plots always make distributions look bell shaped
I feel like this is where the confusion stems from for the author and everyone else here. Box plots don't make anything bell shaped (they don't change the distribution), they assume that your data follows a bell/gaussian shape. This is correct in cases where the central limit theorem can be applied (which is almost everywhere) - but when that is not the case, the assumption is wrong and you shouldn't use a box plot anyways, because the values it shows have no real use. There are very real use cases for box plots, but people need to understand the basics of statistics before they can use them.
{kind=link}
{kind=link}
This should be the topmost comment. Box plots are made for visualizing generalized normal distributions and nothing else.
Edited to preempt nitpick.
Why? They’re non-parametric and make zero assumptions of normality.
How else would you calculate the quartiles to render the boxes?
Count data points in each quartile. You can do that for any sortable data, independent of distribution.
If you do that in your paper, you better write next to the graph that you did that.
Arguing that nobody who might be professionally expected to look at a box plot can be reasonably expected to understand how box plots are defined doesn't make a compelling case that using them is a good idea.
If the method how the plot boxes are calculated is not clear (this thread references at least two different methods), you'll need to explicitly write it down which methods you did use.
No, as the sidethread comment notes, there is only one way you can compute quartiles. You seem to be arguing that the correct thing to do is to impute them, and that calculating them is such a deviant practice that it would need to be specially remarked on.
Isn't this what i was saying from the beginning?
And now people in this thread argue you can calculate them from something else. Not sure if you are replying to the right post.That might be what you were saying from the beginning, but the only thing that that would establish is that you're completely out of touch with reality. Box plots are made for visualizing quartiles.
Your theory would imply, among other things, that the median line going through the box part of a box plot always divides it in half, which obviously is not the case.
No? Exponential Gaussian?
Whatever you do, you should explain first what you do that your whiskers stay meaningful and are not just whatever randomness your outliers produced.
It is actually a fascinating argument that shows how little of what is being decided is based on actual data ( or at least our understanding of it ), but rather that data visualization is being used to push already pre-approved decisions with data being used merely as a 'for' argument.
I agree that if there is an indication that if most professionals don't really know what boxplot is supposed communicate, maybe it should not be used.
Perhaps I expressed myself poorly, and left room for misunderstanding, because I cannot possible imagine that we have any real disagreement on how to compute quartiles.
Any set of numbers I give you, you can compute quartiles for it. There is no algorithm for doing that that breaks down if the numbers don't follow a normal distribution.
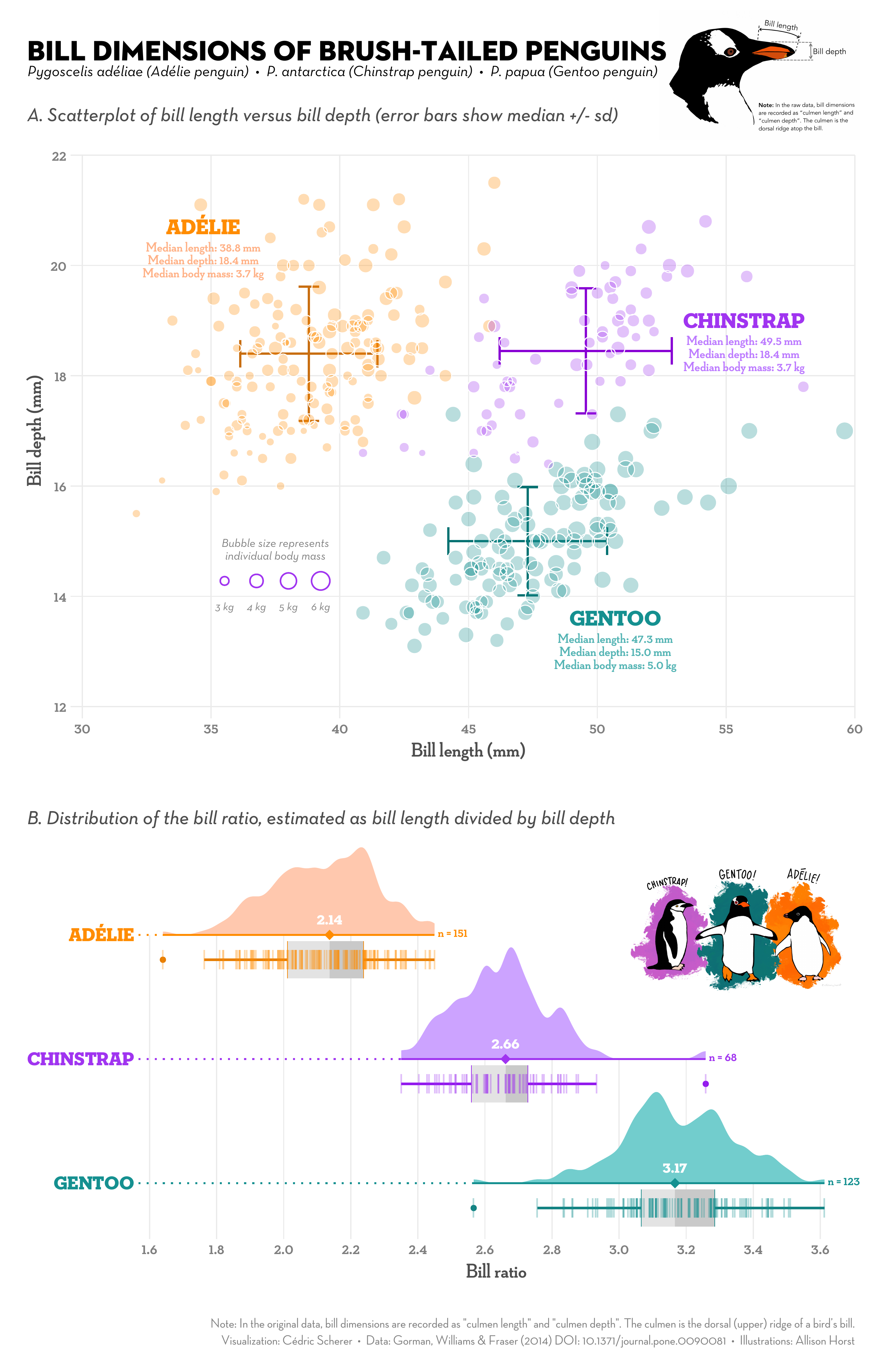
Look at this SVG from wikipedia: https://upload.wikimedia.org/wikipedia/commons/1/1a/Boxplot_...
When you calculate the box plot using normal distribution parameters, the outliers are outside the outer bracket.
If you split the dataset into 4 equal parts, the bracket will be larger because the outliers are still inside it.
The methodologies are not equal.
This thread is the first time i heard people do the "split dataset into 4 quarters" and using that for box plots.
For what it's worth, you've convinced me that my beloved box plots need to be explained if I want to use them again.
The SVG you've provided clearly shows that the box plot splits the data in 4. The interquartile range (IQR) is clearly marked and it even has a comparison for what the standard deviation (variance) measure would be.
Secondly, if the data truly came from a normal distribution, there are no outliers. Outliers are data points which cannot be explained by the model and need to be removed. Unless you have a good reason to exclude the data points they should be included. This is why I like the IQR and the median, they are not swayed by a few wide valued data points. The 1.5*IQR rejection filter I think is lazy and unjustified. Happy to discuss this point further as it is a bug bear of mine.
When i said "splitting", i meant it like my parent explained: Basically sorting your datasets and then splitting into quarters.
What you want to explain to me (IMHO to the wrong person) is the correct approach of calculating a mean and standard deviation and drawing the box from that. Lets stay with that (and thats what i said earlier in the thread)
After i wrote the post you replied to, i realized that the pure "splitting" method for box plots is nonsensical since the outer brackets interval is determined by the two most extreme values. They are too random to be meaningful. It does not make sense to draw a box plot from that.
As I'm sure you know, there are a lot of variations on how quantiles are calculated in various software. The 25th percentile, e.g., doesn't always line up with a value in the dataset, so sometimes nearest rank methods are used, otherwise a linearly interpolated data point, where interpolation is done in various ways.
In any event, none of these methods assume normality, or rely on CDFs of a normal curve.
If they did, every box plot would be symmetric.
The fact some people think that boxplots are constructed in such a way is a pretty good reason to take the author's article seriously as for how boxplots are confusing.
On second thought, this method makes the outer brackets / whiskers pretty much useless since their position is determined by the largest outliers, which is quite much random.
That's not how they're drawn. Outliers (More than 1.5 times the interquartile range outside the 1st/3rd quartile) are plotted as dots beyond the whiskers. The whiskers go at Q1-1.5×IQR and Q3+1.5×IQR.
Better is! Look what i was replying to.
This is also wrong. Gaussian curves are symmetric. Box plots do not have to be. In fact representing skew in a batch is one of the fundamental purposes of them.
But representing skew is precisely to show how "off" from a Guassian it is.
Because real data is never perfectly Guassian, or perfectly anything.
But the idea of a box plot is that it's for data which is in theory Gaussian or a similar unimodal kind of bell-shaped curve.
Then you can look at the box plot and see if it actually is -- are the two boxes roughly equal-sized? Are the lines a bit longer than the boxes but not insanely so?
You model skew in Gaussian distributions by adding an exponential parameter.
But is that what they're actually used for?
The data has been reduced to three numbers, throwing away most of the information that you would need to assess whether the distribution is gaussian or not. If it's not, how will you ever know?
Nah, there's nothing in a box plot which assumes a bell-shape. It does, however just visualise the parameters which reasonably well characterize a smooth single-mode distribution regardless of the underlying distribution. So it's a valid criticism of using box plots, especially when the alternatives can just as well visualise a bell-shaped distribution, as well as showing when it is not.
That IS a bell curve. While it's true that the Guassian distribution is often called a bell curve or even "the" bell curve, a non-Guassian single mode distribution is still absolutely bell shaped in a general sense.
So, although you started your comment with "nah", you're actually in agreement with the content you replied to.
In the mathematical sense this is clearly not true - it’s easy to come up with a smooth single mode distribution that doesn’t look like a bell.
Is it? How?
You could include a lot of little bells far from the single mode, but that's reading a little too much into the literal meaning of "single mode" - a "bimodal" distribution isn't one where the two most common values are both modes. It's one where there are two distinct local maxima.
The tails to the left and right must asymptotically approach zero (or you don't have a smooth distribution, because you have discontinuities somewhere), and if there's just one local maximum, your curve will look like a bell.
The exponential distribution (modal value 0) is not bell shaped. If you don't like it's range of non-negative, then take some smooth mollification
And the smooth mollification will look like...?
It looks like a spike, not a bell.
A spike is not smooth (typically meaning continuous in the variable and its first derivative), which was one of the conditions.
Then take a Cauchy or a t-distribution. Basically anything with a longer tail than exp(x^2). The Gaussian summary will be misleading because of the tails.
in the simplest case... just mirror it (some call this a Laplace distribution). if you don't like how it's not differentiable at the mode there are further smoothings (see, e.g., the wikipedia article for this distribution) but this simple construction is continuous.
Yes or the chi-square distribution with k=1 or 2 or any other of the gamma distributions[1] with the right parameters will have a shape that is one-sided with the mode at the lower extreme and no "low tail" in the normal sense.
[1] https://en.wikipedia.org/wiki/Gamma_distribution or https://stats.libretexts.org/Bookshelves/Probability_Theory/...
The bell curve IS the smooth single mode with LOWEST ENTROPY.
Do you mean greatest entropy? Not if the support is, for example, the positive reals.
The problem is that the four quantile groups contain equal numbers of items, but are not represented by equal areas, even if we replace the whiskers with a bar of the same width as the box.
The bottom whisker contains 25% of the data, yet is just a thin line, which can furthermore be arbitrarily short.
It really is a dumb visual presentation.
The only way to use it is to recover the five parameters from it, and then stop looking at it.
For that purpose, a QR code would be just as good, if not better. You'd need a device with a camera to get the parameters (but "everyone" has that now), and when you're looking at it with your bare eyes, it doesn't tell you any visual lie.
...which is its intended use case since Tukey invented it as a way of visualising the "5 number summary". I think part of his criteria were that it should be easy to make by hand which is clearly no longer a consideration so there are plenty of reasons to just do something else most of the time these days.
Not sure how to square that with this statement on Wikipedia's page on box plots:
Box plots are non-parametric: they display variation in samples of a statistical population without making any assumptions of the underlying statistical distribution[3]
If you want to see why that is not fully correct you should read the article. For a box plot you need to calculate mean, variance and certain percentiles. These values don't make sense if your distribution does not follow a certain shape (because these values unambiguously define such a shape). See the examples in the article for what happens if you still try to use them in those cases. You can still extract the values of course (hence probably why wiki says they don't assume anything), but you lose significant information about the distribution. So you can no longer reverse the process.
The mean and variance are not features of a box plot. Box plots show the quartiles, which are about the cumulative distribution.
Which is why I find the article so compelling because I'd always read box plots as being about variance. To me the plot implied a quite normal distribution.
Note that "not knowing how to correctly interpret a boxplot" is not equivalent to "boxplots are useless".
If people like me are in the audience, they might be worse than useless.
Sure. But if someone is using, for example, a notched boxplot to quickly evaluate differences in medians (i.e., they know how to correctly interpret a boxplot), it can still be a useful plot that conveys specific information that you would otherwise not get when looking at a violin plot, histogram, kernel density estimate or a strip plot.
My point, again, was: just because a boxplot is not useful to some people, doesn't mean that it is not a useful plot (particularly when augmented with a rugplot or a strip plot). Plots are not just used to convey information to others: they are also a useful tool in exploratory data analysis.
Notice that you can also apply the same critique to almost any plot: some people don't know how to interpret a violin plot (or kernel density estimate plot) correctly... does that make them useless?
The main advantage of a boxplot is that it is parameter-free (unlike histograms, violin plots and kernel density plots) and quickly conveys very specific information (median, range, quantiles, confidence interval for the median) that other types of plot usually don't.
I've never understood this to be the purpose of a boxplot, only a means of visualizing a distribution's quartiles.
You've gotten a flood of comments from upset people, so I'll keep it short by saying that a boxplot doesn't actually do what you claim for Gaussians, as the 0 and 100 percentile "whiskers" would be at plus/minus infinity. As for a bounded bell-shaped distribution, there are several non-unique ways to define such a distribution.
The point is not to plot an ideal Gaussian, the point is to plot the data.
In real life the whiskers are the actual minimum and maximum values observed.
Look at this: https://upload.wikimedia.org/wikipedia/commons/1/1a/Boxplot_...
0.7% of all values are outside the whiskers.
There are two standard ways of doing box plots. One is miniums and maximums, the other is the 1.5 IQR method.
The very Wikipedia article your image comes from explains this:
https://en.wikipedia.org/wiki/Box_plot#Whiskers
I think this is a misunderstanding, and I think it is shared by the author of the article. Boxpolots show ranges. That's it.
Mean and variance have nothing to do with boxplots, you are mistaken.
Quantiles and medians. (Plus min and max.) Non-parametric.
I agree. The author simply used the wrong chart.
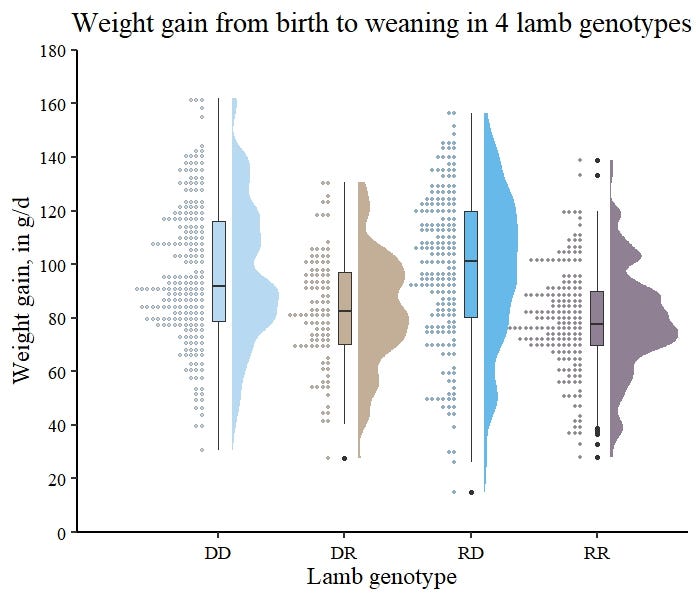
The author's example has a bimodal distribution (TWO peaks) and chooses a type of chart that has ONE peak (a box plot).
A little baffling tbh.
Well, to start with, how would you determine that about your distribution in the first place? And if that works well enough, why use a box plot afterwards?
Yes, exactly! Just plot all the bloody data and be done with it. No one is doing this by hand anymore so it is no extra work.
To my mind, if you have a genuine EDA attitude you plot it all.
Well no, because you can compare the datasets by eye and say questionable qualitative things about them, but you can't make definitively true quantitative statements about them.
Show me two plots of data points and I can show you two people who will in good faith argue over which one has the higher mean or higher median or higher variance. Because you often can't tell.
The entire point of something like a box plot is that it does part of the quantitative analysis for you. You can see where the median is. You can see the width of the quartiles.
But there are much better ways to do this than box plots! Lots of CS papers use CDF and it's great and very informative once you get used to it (although you do need to get used to them). You can have violin plots with all the box plots elements and more. Even if you want to restrict yourself to quartiles, author's design concepts with narrow/wide bars makes much more visual sense, and still convey exactly the same information as box plots.
It depends on the purpose.
CDF plots are great for plotting a single distributions, but contain way too much information if you want to plot 6 distributions next to each other for easy comparison.
Violin plots are interesting but also quite complicated, since you have to arbitrarily choose a kernel shape and this artificial smoothing can make it look like you have much more data than you really do.
I really don't like the author's "alternative designs" because I think they're even more open to misinterpretation than box plots. It's hard to judge though, because the central problem is that the author is trying to represent a bimodal distribution, and shouldn't be using box plots or the 2 "alternative designs" for that.
Well usually when you are analyzing some data, you toss it into the most basic chart like a histogram.
And a histogram for the author's example is perfectly acceptable to show that single data series.
But imagine if you have 10 different normal data series and you want to compare their medians and distributions between each other... well are you going to put 10 histograms side by side and expect the reader to compare them? No -- that's where the box and whisker plot shines.
Simple, use a histogram.
The author's first histogram clearly shows most of the distribution lies in [20,100), then the [10,20) bin is empty but the [0,10) bin is quite full. Hence, that's not a single-mode distribution. It has two modes, one around [50,60) and the other in [0,10).
Because it's very hard to rationally compare multimodal batches without single test statistics. And they present five summary figures for each batch, each of which are reasonable metrics to compare batches with.
Huh? A box plot doesn't have any peaks. A box plot is a histogram subject to the constraint that every bar in the histogram is equally tall. There can never be more than zero peaks.
The author argues otherwise, can you give an example of a use case where box plots would be preferable to the alternatives the author suggests?
Often people are interested in exact quantitative statistics like IQR, median, top/bottom deciles which are commonly represented in box plots. The alternatives are visually simpler but they contain less quantitative information.
The alternative plots in TFA after
present the exact same info in much less visually confusing ways, through the use of brightness (weight) and area. Just better box plots.
And of course you can always draw some lines for the quartiles on any kind of plot with a linear scale for the value.
If you want quantititive information it's better to use a table anyway - precisely because it doesn't mislead you about the internal distribution.
No, in the article he says he wouldn't recommend them _in most_ situations. It's a part that a lot of people here seemed to have missed whether arguing for or against box plots.
(Emphasis mine)
From the article:
„So, no, I can’t think of any situations when a box plot would be the truly best choice, other than those in which the audience demands box plots because that’s what they’re used to seeing. If you can think of any such situations, though, please let me know on LinkedIn or Twitter.“
„Other reviewers suggested that the conclusion should be that box plots are a useful chart type, but only for statistically savvy audiences. Again, I’m going a step further, suggesting that even those audiences would be better served by other chart types in virtually all situations.“
Comparing location, spread and skew of multiple batches.
Exactly this on the last point. Although rereading this the distribution point is explained poorly.
People waltz in with assumptions and then complain when they don’t work because they don’t really understand the tools they are using. The author is one of them. It’s a bad article and the author should not be using or demonstrating things they clearly don't understand.
Isn't that the whole point? That the graph type is very easy to misunderstand. If you are right, and not even a professional data visualization consultant properly understands the graph, then who will?
Some of us are perfectly qualified to understand them and the nuances.
A plot that requires the reader to be perfectly qualified is a bad plot.
They teach this to 15 year olds in the UK.
If it's a bad plot, perhaps some introspection is required...
They also teach pie charts and use color scales with non-uniform brightness. Just because it's possible to read a plot doesn't make it a good plot.
Yes.
A lot of people here are commenting that no, technically box plots don't assume any distribution. And I mean, technically you can ride from NYC to SF in a lawnmower.
But I completely agree that box plots shouldn't ever be used for anything but unimodal distributions similar enough to a bell/gaussian distribution.
All of the criticism of the article seems to be that they're misleading when the distribution is not bell/gaussian, e.g. bimodal.
To which my reply is, of course. Box plots shouldn't be used then. But if your distribution is bell/gaussian, they seem fine and I see no particular issue with them.
Well, how do you readers know if your distribution is bell/gaussian? Sure, sometimes you plot means of large samples, and then it is true by construction; but a lot of time people use box plots when there is no intrinsic reasons for data to be gaussian. Like most experimental papers.
Or take the first example from wikipedia page on box plot [0]: "Box plot of data from the Michelson experiment", which is just 20 points per run. Would I want to see this in the paper? No please. There is no evidence that the experimental data is gaussian (or even single-modal). Or further down that page, "A series of hourly temperatures" - why would one box-plot it either?
And even if you claim your data is gaussian by construction, maybe because you surveyed lots of people - I still want to see the evidence, as it's pretty simple to make experimental mistakes that turns data non-gaussian (say you only surveyed two neighborhoods with very different properties)
In other words, the domain where box plots are sufficient is very small. Most publications should never use them.
[0] https://en.wikipedia.org/wiki/Box_plot
This article is very click-baity.
Boxplots are a single tool for data analysis. They do not apply in every situation, nor do any other tools. The same goes for pie charts, which are constantly being accused of always distorting data. Pie charts, like box plots, have their place.
The article's full argument seems to be that there are alternatives which are applicable where box plots are not and, at least in most cases, better where they are (there is a tacit (IIRC) subtext of "given that we're using software to do the plotting.")
This is debatable, but noting that box plots are satisfactory for unimodal gaussian-ish distributions is not a very persuasive response.
Murphy's law for data viz:
If a plot can mislead, it will.
No they don't. They show quartiles mostly, and don't assume symmetry or any parameters of a gaussian.
What you say is technically correct, but in the sense where you can put rat poison in One of those ceramic cookie jars they sell in houseware shops. There is nothing wrong in doing it, but it may lead to interesting failure modes Because someone can have implicit assumptions about what’s in there.
Quartiles are relevant for almost any distribution
If by "almost any" you mean "unimodal".
Quartiles are not relevant, i.e. can be highly misleading, for a bimodal distribution or beyond...
they are misleading if you assume unimodality, but are always relevant. If you care about how many modes there are then likely you would prefer deciles or centiles.
But even in the first image of the article the fact that two quartiles are close together means that there some density peak around there.
I agree with the author that box plots are not good plots, but quartiles/deciles/medians are useful even for multimodal distributions
Sorry I don’t understand. The central limit theorem describe the distribution of the sample means from a population. It describes the distribution of the mean, not the distribution of the population itself. The shape of the distribution of the sample mean isn’t super interesting when you’re interested in the distribution of the samples themselves as a proxy for a population. So I’m not sure I understand your assertion. Could you explain more your reasoning? Maybe I’m missing something, but the estimation of the sample mean distribution isn’t the only metric that’s useful, and almost nothing in nature is normally distributed otherwise. Normal distributions are generally a useful assumption mostly because of the analytic form of the Gaussian and our understanding of how to work with it. But that estimation isn’t useful as it might seem. A Poisson distribution is much more common for instance.
I't appears you don't understand the central limit theorem fully. You gave the definition you find in textbooks, but you don't see how it applies to real world measurements and already explains your question. I can only recommend to visit a university level statistics course at this point. Maybe you will understand when you actually deal with some real data. Then you will indeed see its consequences pop up everywhere. The issue (also for the blog author) is that it is often implicitly assumed. It is one of many common pitfalls in statistics. You should also learn what the difference is between a poisson and a gaussian distribution. They may look similar, but there is a drastic difference in their definition and they are used in very different circumstances.
The GP here did not claim a poisson was the same thing as a Gaussian. They also don’t look similar.
As far as I can tell you’re making the introductory student error of thinking the central limit theorem means any sufficiently large sample makes a distribution look normal.
Could you please elaborate on the reason? I assume it’s related to a unique null derivative instead of multiple maxima, but I couldn’t find any papers or information on this.
Additionally, I find the article informative but believe it could be improved with this clarification. As someone who has worked with data analytics but is not a mathematician or actuary, I know people who probably review these types of graphs. Now, I understand that it is essential to check the underlying data distribution to avoid being misled by the information, even if the source and axes seem trustworthy
I think the word you're trying to use is "bimodal" and yes, that is one example where the author's reasoning fails. But it's not the only one.
You said you have no formal higher education in mathematics - how would you even go about finding (let alone understanding) papers? Regardless, just to be clear, this is not something you would learn from papers but from introductory textbooks and university courses. Everyone who has to deal with statistics in science needs to go through a whole lot of extra education exactly because there are many pitfalls like this.
That is another half-truth that everyone on the outside seems to agree on, but it is useless in practice. What do you do if the underlying data is not accessible. And what if you don't have the means to process it for every paper you read (which is what usually happens)? Then you have to rely on the actual tricks of the trade, which will come naturally if you worked with tons of statistics before. There are lots of telltale signs that let you spot bad analyses by only looking at a plot or summary chart. Granted, you won't catch all of them, but it often takes real malice and deep statistical competence on the author's side to cover up these things.
A bell shape has no minimum/maximum, like the box has.
In theory. In pratice you always have a finite sample size and thus a min and max.
This is exactly why the author says you should stop using Box plots. The plot is easy to misinterpret.
The argument is more about the relation between the visualization and the audience, not the data and the visualization. I see a lot of commenters missing this point.
Boxplots don't assume anything about your data. They just measure percentiles and put them on the y-axis.
Yes! You are right and my gears were grinding the whole time reading that article because right of the bat they make some gross and incorrect assumptions.
A box plot isn't trying to show the same thing a histogram is, it's like saying we should stop using Venn diagrams because they confuse people when trying to show the exact amount of overlap, so pie charts are better...
It's silly.
You sir just failed basic statistics