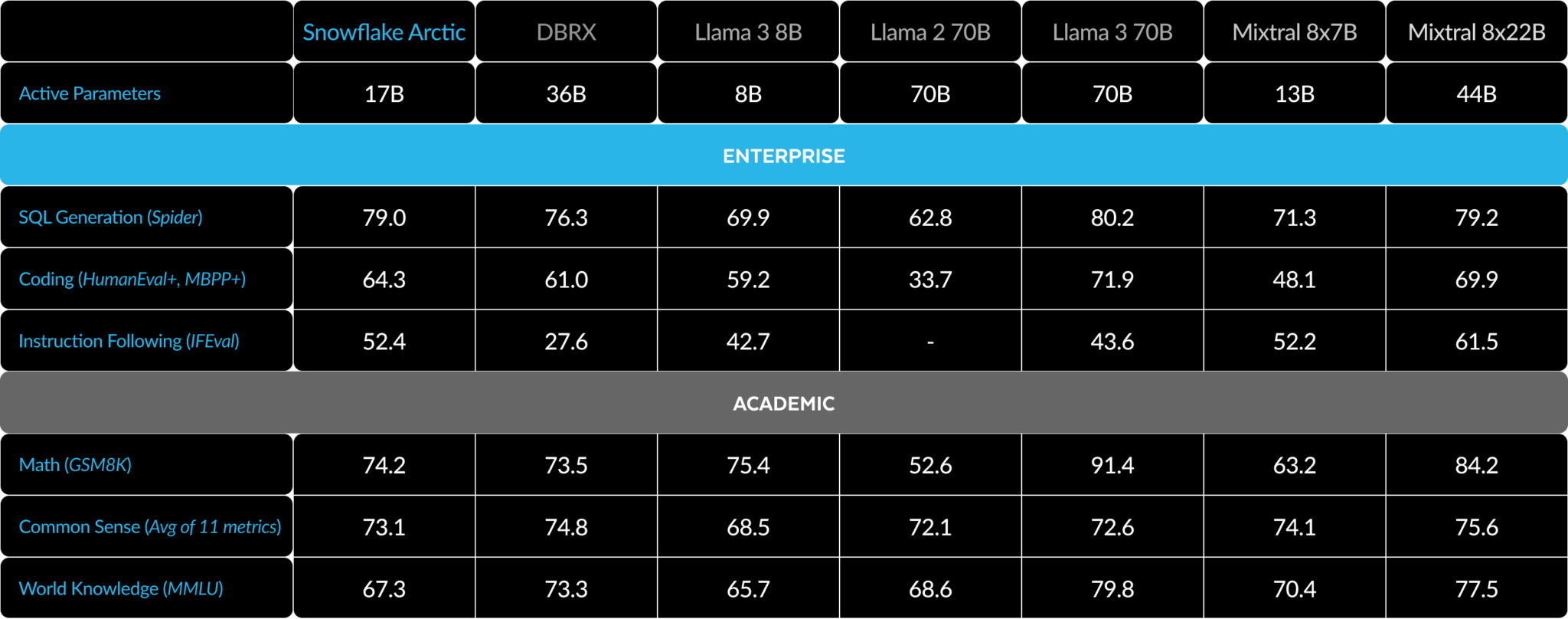
Wow, 128 experts in a single model. That's a lot more than everyone else. The Snowflake team has a blog post explaining why they did that:
https://www.snowflake.com/blog/arctic-open-efficient-foundat...
But the most interesting aspect about this, for me, is that every tech company seems to be coming out with a free open model claiming to be better than the others at this thing or that thing. The number of choices is overwhelming. As of right now, Huggingface is hosting over 600,000 different pretrained open models.
Lots of money has been forever burned training or finetuning all those open models. Even more money has been forever burned training or finetuning all the models that have not been publicly released. It's like a giant bonfire, with Nvidia supplying most of the (very expensive) chopped wood.
Who's going to recoup all that investment? When? How? What's the rationale for releasing all these models to the public? Do all these tech companies know something we don't? Why are they doing this?
---
EDIT: Changed "0.6 million" to "600,000," which seems clearer. Added "or finetuning".
{kind=link}
The model seems to be "build something fast, get users, engagement, and venture capital, hope you can grow fast enough to still be around after the Great AI cull".
One estimate I saw was that training GPT3 released 500 tons of CO2 back in 2020. Out of those 600k models, at least hundreds are of a comparable complexity. I can only hope building large models does not become analogous to cryptocoin speculation, where resources are forever burned only in a quest to attract the greater fool.
Those startups and researchers would better invest in smarter algorithms and approaches instead of trying to outpolute OpenAI, Meta and Microsoft.
So absolute nothing in the grand scheme of things?
That's the amount that would be released by burning 50,000 gallons of gas, which is about that ten typical cars will burn throughout their entire lifespan.
Done once, I agree, that's very little.
But if each of those 600,000 other models used that much (or even a tenth that much), then that now becomes impactful.
Releasing 500 tons of CO2 600,000 times over would amount to about 1% of all human global annual emissions.
500 tons is like a few flights between SF and NYC dude.
And those 600k models are mostly fine-tunes. If running your 4090 at home is too much then we're going to have to get rid of the gamers.
This CO2 objection is such an innumerate objection. Just making 100 cars already is more than making one of these LLMs from scratch. A finetune is so cheap in comparison.
In fact, I bet if you asked most LLM companies they'd gladly support a universal carbon tax with even dividend based on emissions and then you'd see who's actually emitting.
There are two groups here.
One sees the high impact of the large model, and the growth of model training, and is concerned with how much that could increase in coming years.
The other group assumes the first group is complaining about right now, and thinks they're being ridiculous.
This whole thing reminds me of ten years ago when people were pointing out energy waste as a downside of bitcoin. "It's so little! Electricity prices will prevent it from ever becoming significant!" was the response that it was met with, just like people are saying in this thread.
In 2023, crypto mining accounted for about 0.5% of humanity's electricity consumption. If AI model training follows a similar curve, then it's reasonable to be concerned.
Yes, but one can at least still imagine scenarios where AI training being 0.5% of electricity use could still be a net win.
(I hope we're more efficient than that; but if we're training models that end up helping a little with humanity's great problems, using 1/200th of our electricity for it could be worth it).
The current crop of generative AIs seems well-poised to take over a significant amount of low-skill human labor.
It does not seem well-poised to yield novel advancements in unrelated-to-AI fields, yet. Possibly genetics. But things like solving global warming, there is not any sort of path towards that for anything we're currently creating.
It's not clear to me that spending 0.5% of electricity generation to put a solid chunk of the lower-middle-class out of work is worth it.
There was an important "if" there in what I said. That's why I didn't say that it was the case. Though, no matter what, LLMs are doing more useful work than looking for hash collisions.
Can LLMs help us save energy? It doesn't seem to be such a ridiculous idea to me.
And can they be an effort multiplier for others working on harder problems? Likely-- I am a high-skill worker and I routinely have lower-skill tasks that I can delegate to LLMs more easily than I could either do myself or delegate to other humans. (And, now and then, they're helpful for brainstorming in my chosen fields).
I had a big manual to write communicating how to use something I've built. Giving GPT-4 some bulleted lists and a sample of my writing got about 2/3rds of it done. (I had to throw a fraction away, and make some small correctness edits). It took much less of my time than working with a doc writer usually does and probably yielded a better result. In turn, I'm back to my high-value tasks sooner.
That is, LLMs may help attacking the great problems directly, or they may help us dedicate more effort to the great problems. (Or they may do nothing or may screw us all up in other ways).
I fully agree that any way you cut it, LLMs are more useful than looking for hash collisions.
The trouble I have is, what determines whether AI grow to 0.5% (or whatever %) of our electricity usage is not whether the AI is a net good for humanity even considering power use. It's going to be determined by whether the AI is a net benefit for the bank account of the people with the means to make AI.
We can just as easily have a situation where AI grows to 0.5% electricity usage, is economically viable for those in control of it, while having a net negative impact for the rest of society.
As a parent said, a carbon tax would address a lot of this and would be great for a lot of reasons.
Sure. You're just talking about externalities.
Except this is obviously not the case, as "the other group" is aware that many of these large training companies, such as Microsoft, have committed to being net negative on carbon by 2030, and are actively making progress with this whereas the other group seems to be motivated by flailing for anything they can use to point at AI and call it bad.
How many carbon-equivalent tons does training an AI in a net negative datacenter produce? Once the datacenters run on sunlight what is the new objection which will be found?
The rest of the world does not remain static with only the AI investments increasing.
Are you claiming that by 2030, the majority of AI will be trained in a carbon-neutral-or-better environment?
If not, then my point stands.
If so, I think that's an unrealistic claim. I'm willing to put my money where my mouth is. I'll bet you $1000 that by the year 2030, fewer than half of (major, trailed-from-scratch) models are trained in a carbon-neutral-or-better environment. Money goes to charity of the winner's choice.
I'm willing to take this bet, if we can figure out what the heck "major" trained-from-scratch models are and if we can figure out some objective source for tracking. Right now I believe I am on the path to easily win given that both the major upcoming models, (GPT-5 and Claude 4?) are training in large companies actively working on reducing their carbon output (Microsoft and Amazon data centers)
Mistral appears to be using the Leonardo supercomputer, which doesn't seem to have direct numbers available, but I did find this quote upon its launch in 2022:
You might have a greater chance to win the bet if we think about all models trained in 2030, not just flagship/cutting-edge models, as it's likely that all the GPUs which are frantically being purchased now will be depreciated and sold to hackers by the truckload here in 4-5 years, the same way some of us collect old servers from 2018ish now. But even that is a hard calculation to make--do we count old H100s running at home but on solar power as sustainable? Will the new hardware running in sustainable datacenters continue to vastly outpace the old depreciated?
For cutting-edge models which almost by definition require huge compute infrastructure, a majority of them will be carbon neutral by 2030.
A better way to frame this bet might be to consider it in percentages of total energy generation? It might be easier to actually get that number in 2030. Like Dirty AI takes 3% of total generation and clean AI 3.5%?
Something else to consider is the algorithmic improvements between now and 2030. From Yann LeCunn: Training LLaMA 13B emits 24 times less greenhouse gases than training GPT-3 175B yet performs better on benchmarks.
I haven't done longbets before, but I think that's what we're supposed to use for stuff like this? :) My email is in my profile.
One more thing to consider before we commit is that the current global share of renewable energy is something close to 29%. You should probably factor in overall renewable growth by 2030, if >50% of energy is renewable by then, I win by default but that doesn't exactly seem sporting.
Yeah that’s the annual emissions for only 100 people at the global average or about 30 Americans.
Flights from the Western USA to Hawaii are ~2 million tons a year, at least in 2017, wouldn’t be surprised if that number doubled.
500t to train a model at least seems like a more productive use of carbon than spending a few days on the beach. So I don’t think the carbon use of training models is that extreme.
GPT3 was a 175 bln parameters model. All the big boys are now doing trillions of parameters without a substantial chip efficiency increase. So we are talking about thousands of tons of carbon per model, repeated every year or two or however fast they become obsolete. To that we need to add embedded carbon in the entire hardware stack and datacenter, it quickly adds up.
If it's just a handfull of companies doing it, fine, it's negligible versus benefits. If it starts to chase the marginal cost of the resources in requires, so that every mid to large company feels that a few million $ or so spent training their a model on their own dataset makes them more in competitive advantages, then it quickly spirals out of control hence the cryptocoin analogy. That's exactly what many AI startups are proposing.
AI models don’t care if the electricity comes from renewable sources. Renewables are cheaper than fossil fuels at this point and getting cheaper still. I feel a lot better about a world where we consume 10x the energy but it comes from renewables than one where we only consume 2x but the lack of demand limits investment in renewables.
It's also a great load to support with renewables because you can always do training as "bulk operations" on the margins.
Just do them when renewable supply is high and demand is low; that energy can't be stored and would have been wasted anyway.
This is a complete fantasy as the depreciation rate on the hardware is higher than the prices of electricity.
Again, look at bitcoin mining, the miners will happily pay any carbon tax to work 24/7, it's better to run the farm to cover electricity prices and then make some pennies then to keep it off and incur depreciation costs.
This is a dangerous fantasy. Everything we know about the de-carbonation of the grid suggests that conservation is a key strategy for the next decades. There is no credible scenario towards 100% renewables. Storage is insanely expensive and green load smoothing capacity such as hydro and biomass is naturally limited. So a substantial part of the production when renewables drop will be handled by natural gas, which seem to have equivalent emissions similar to coal when you factor in the lost methane, fracked methane in particular.
In addition, even 100% renewable would be attainable, that would still require massive infrastructure investment, resource use and associated emissions, since most of the corresponding industries, such as concrete and steel production, aluminum and copper ore mining and refining etc. are very far from net zero and will stay that way for decades.
To throw into this planet-sized bonfire a large uninterruptible consumer, whose standby capital depreciation on things like state of the art datacenters far exceeds the cost most industries are willing to pay for energy, all predicated on the idea that "demand spurs renewable investments", is frankly idiotic.
Sounds like we'll have to adjust the price of non-renewables to reflect total cost, not just extraction, transportation, and generation cost.
Especially if one were to only run the servers during the daytime, when they can be powered directly from photovoltaics.
Which isn't going to happen, because you want to amortize these cards over 24 hours per day, not just when the renewables are shining or blowing.
We currently don't live in a world where renewable energy is available in excess.
It's likely not the model size that's bigger, but the training corpus (see 15T for llama3). I doubt anyone has a model with “trillions” of parameters right now, one trillion maybe as rumored for GPT-4, but even for GPT-4 I'm skeptical about the rumors given the inference cost for super large models and the fact that the biggest lesson we got since llama is that training corpus size alone is enough for performance increase, at a reduce inference cost.
Edit: that doesn't change your underlying argument though: no matter if it's the parameter count that increases while staying at “Chinchilla optimal” level of training, or the training time that increases, there's still a massive increase in training power spent.
The average American family is responsible for something like 50 tons per year. The carbon of one family for a decade is nothing compared to the benefits. The carbon of 1000 families for a decade is also approximately nothing compared to the benefits. It's just not relevant in the scheme of our economy.
There aren't that many base models, and finetunes take very little energy to perform.
I wonder what is greater, the CO2 produced by training AI models, the CO2 produced by researchers flying around to talk about AI models, or the CO2 produced by private jets funded by AI investments.
Institute a carbon tax and I'm sure we'll find out soon enough
For sure; I didn’t realize sensible systemic reforms were on the table.
I’m not sure if any of these things would be the first on the chopping block if a carbon tax were implemented, but it is worth a shot.
They're probably above the median on the scale of actually useful human activities; there's a lot of stuff carbon tax would eat first.
Yup, but even for the useful stuff, a greater price of carbon-intensive energy would change some about how you consider doing it.
So less than Taylor Swift over 12-18 months, since she burned 138t in the last 3 months:
https://www.newsweek.com/taylor-swift-coming-under-fire-co2-...
> "build something fast, get users, engagement, and venture capital, hope you can grow fast enough to still be around after the Great AI cull"
Snowflake is a publicly traded company with a market cap of $50B and $4B of cash in hand. It has no need for venture capital money.
It looks like a case of "Look Ma! I can do it too!"
I've seen estimates that training gpt3 consumed 10GWh, while inference by its millions of users consumes 1GWh per day, so inference Co2 costs dwarf training costs.
Far fewer than 600,000 of those are pretrained. Most are finetuned which is much easier. You can finetune a 7B model on gamer cards.
There is basically the big guys that everyone's heard of (google, meta, microsoft/openAI, and anthropic) and then a handful of smaller players who are training foundation models mostly so that they can prove to VCs that they are capable of doing so -- to acquire more funding/access to compute so that they may eventually dethrone openAI and take a piece of the multi-billion dollar "enterprise AI" market for themselves.
Below that, there is a frothing ocean of mostly 7B finetunes created mostly by individuals who want to jailbreak base models for... reasons, plus the occasional research group.
The most oddball one I have seen is the databricks LLM which seems to have been an exercise of pure marketing. Those I suspect will disappear when the bubble deflates a bit.
You've nerdsniped me so hard that I had to make an account.
There are DOZENS of orgs releasing foundational models, not "a handful."
Salesforce, EleuthierAI, NVIDIA, Amazon, Stanford, RedPajama, Cohere, Mistral, MosaicML, Yandex, Huawei StabilityLM, ...
https://docs.google.com/spreadsheets/d/1kT4or6b0Fedd-W_jMwYp...
It's completely bonkers and a huge waste of resources. Most of them will see barely any use at all.
Very nice! This list is super convenient for LLM “connoisseurs”(?) like me.
Did you have a script to generate it or was it manually done?
Just spotted this link. Just to clarify, I (not the original poster, although everyone's welcome to share this link, it's a public doc) maintain this list (and the rest of the sheet) manually. While I keep the foundation models that I'm interested in fairly up to date, obviously there are too many fine-tunes/datasets to track now. I started this when LLaMA was first released and I was getting myself up to speed on the LLM landscape.
A group at the CRFM maintains a bigger list of models (their goal is stated for cataloguing foundation models, but it looks like they have some tunes mixed in these days): https://crfm.stanford.edu/ecosystem-graphs/
This site also seems to keep track of models, with more closed/announced models that I don't bother to track: https://lifearchitect.ai/models-table/
Very useful info. Thank you!
Competition isn't a waste of resources, it's the best mechanism we have to ensure quality.
Furthermore, I'm happy to be in a golden age with lots of orgs trying things and many options. It's going to suck once the market eventually consolidates us and we have to take whatever enshittified thing the ologopolists feed us.
Gods if this isn't exactly how it'll turn out.
Interesting! That is more than I thought. Honored to have caused a nerdsnipe.
In the grand scheme of things, though, most of these are quite small -- 7b range. A 7b model is nothing to sneeze at but it's not megacorp resources either. It's in the range of "VC check" size.
The "big boys" who are training 70b plus are FAANG or government-scale entities. Microsoft, Google, and Meta have multiple entries on that "big" LLM foundation list -- it's because the GPUs are already bought, have to train something to keep utilization up. Also bear in mind that training of these things is still something closer to an art than a science; you put terabytes of data into the cauldron, let it brew, and only after it's done can you taste what you've made. Makes sense that some of these models will be junk.
It’s like cryptocurrency hashing but, now, all the players are large extremely rich corporations. It is gonna be the funniest historical rhyme ever.
Yep, seems like every company is taking a longshot on a AI project. Even companies like Databricks (MosaicML) and Vercel (v0 and ai.sdk) are seeing if they can take a piece of this every growing pie.
Snowflake and the like are training and releasing new models because they intend to integrate the AI into their existing product down the line. Why not use and fine-tune an existing model? Their in-grown model maybe better suited for their product. This can also fail like Bloomberg's financial model being inferior to GPT-4, but these companies have to try.
Their biggest competitor release a model. They must follow suit.
It isn't like they could have started this after the release and been done by now.
Not all of them have permissive licenses for whatever the companies may want (or their clients want). Kind of a funny situation where everyone would benefit, but no one wants to burn their money for the greater good.
> an exercise of pure marketing
Yes. Great choice of words. A lot of non-frontier models look like "an exercise of pure marketing" to me.
Still, I fail to see the rationale for telling the world, "Look at us! We can do it too!"
Mid-level managers at a lot of companies still have no clue what LLMs are or how they work. These companies (like databricks) want to have their salespeople upsell such companies on "business AI." They have the base model in their back pocket just in case one of the customers in the room has heard the name Andrej Karpathy before and starts asking questions about how good their AI solution is... they can point to their model and its benchmarks to say "we know what we are doing with this AI stuff." It's just standard marketing stuff which works right now because of how difficult it is to actually objectively benchmark LLMs.
Interesting you'd say that in a discussion on Snowflake's LLM, no less. As someone who has a good opinion of Databricks, genuinely curious what made you arrive at such a damning conclusion.
600k?
> Who's going to recoup all that investment? When? How? What's the long-term strategy AI of all these tech companies? Do they know something we don't?
The first droid armies will rapidly recoup the cost when the final wars for world domination begin…
Even before that, elections are coming end of the year, chat bots are great for telling whom to vote for.
2020's elections costed 15B USD in total, so we can't afford to lose (we are the good guys, right ?)
How will the LLMs be used for this? They can't solve captchas, and they're not smart enough to navigate the internet by themselves. All they do is generate text.
Transformers can definitely solve captchas. Not sure why you think otherwise.
So captchas are obsolete now?
For a while now, even before the latest AI models. Paid services exist (~2$/1k solves https://deathbycaptcha.com/)
Seems like capitalism is doing its thing here. The potential future revenue from having the best model is presumably in the trillions.
I heard this winner-takes-all spiel before - only last time, it was about Uber or Tesla[1] robo-taxis making car ownership obsolete. Uber has since exited the self-driving business, Cruise is on hold/unwinding and the whole self-driving bubble has mostly deflated, and most of the startups are long gone, despite the billions invested in the self-driving space. Waymo is the only company with robo-taxis, albeit in only 2 tiny markets and many years away from general availability.
1. Tesla is making robo-taxi noises once more, and again, to juice investor sentiment.
Uber and Tesla are valued at 150B and 500B respectively, I'd say in terms of an ROI on deploying large amounts of capital these are both huge success stories.
No investment in an emerging market is a sure thing, it's an educated guess. You have to take a lot of swings to occasionally hit a homerun, and investing in AI seems like the most plausible swing to make at this time.
I didn't claim there's no positive ROI. I only noted that the breathlessly promised "trillion+ dollar self-driving market" failed to materialize.
I suspect the AI market will have a similar trajectory in the next decade: no actual AGI - maybe one company still plugging away at it, a couple of very successful companies whose core competencies don't include AI, but with billions in market cap, and a lot of failed startups littering the way there.
It doesn't seem like that's true at all.
If the "best model" only stays the best for a few months and if, during those few months, the second best model is near indistinguishable, then it will be extremely hard to extract trillions of dollars.
L0L Trillions ROFL
In the short-term, these kinds of investments can hype up a stock and create a small bump.
However, in the long-term, as the hype dies down, so will the stock prices.
At the end of the day, I think it will be a transfer of wealth from shareholders to Nvidia and power companies.
I just wish that AMD (and, pie in the sky, Intel) had gotten their shit together enough that these flaming dumptrucks full of money would have actually resulted in a competitive GPU market.
Honestly, Zuckerburg (seemingly the only CEO willing to actually invest in an open AI ecosystem for the obvious benefits it brings them) should just invest a few million into hiring a few real firmware hackers to port all the ML CUDA code into an agnostic layer that AMD can build to.
Groq seems to be well positioned to give Nvidia a run for their money, actually.
*Depending on govt interventions
This seems to me to be the simple story of "capitalism, having learned from the past, undertands that free/open source is actually advantageous for the little guys."
Which is to say, "everyone" knows that this stuff has a lot of potential. Everyone is also used to what often happens in tech, which is outrageous winner-take-all scale effects. Everyone ALSO knows that there's almost certainly little MARGINAL difference between what the big guys will be able to do and and what the little guys can do on their own ESPECIALLY if they essentially 'pool their knowledge.'
So, I suppose it's the whole industry collectively and subconsciously preventing e.g. OpenAI/ChatGPT becoming the Microsoft of AI.
This seems rather generous.
Yeah, I don't mean it to sound that generous, as in "capitalism likes little guys."
More like "little guys, or even literally any 'guy' that isn't dominant in this space -- which tends toward dominance -- have learned, perhaps counterintuitively, that free/open source is best for their own greedy interests."
:)
Snowflake has a pretty good story in this space: "Your data is already in our cloud, so governance and use is a solved problem. Now use our AI (and burn credits)". This is a huge pain-point if you're thinking about ML with your (probably private) data. It's less clear if this entices companies to move INTO Snowflake IMO
And streamlit, if you're as old as me, looks an awful lot like a MS-Access application for today. Again, it lives in the database, runs on a Snowflake warehouse and consumes credits, which is their revenue engine.
Snowflake could have the same story by hosting Llama 3 which is probably more efficient/better.
Snowflake hosts a couple models: https://docs.snowflake.com/en/user-guide/snowflake-cortex/ll...
It diminishes the story that Databricks is the default route to privately trained models on your own data. Databricks jumped on the LLM bandwagon really quickly to good effect. Now every enterprise must at least consider Snowflake, and especially their existing clients who need to defend decisions to board members.
It also means they build large scale rails necessary to use Snowflake for training and can market such at every release.
I don't think that you understand Databricks. Databricks gives you the tools to train, tune or build RAG models. Snowflake doesn't.
Having said that, I'm a big fan of Llama-3 at the moment.
What a peculiar way to say: 600,000
You're right. I changed it. Thanks!
Why 0.6 million and not +600k ?
You're right. I changed it. Thanks!
At a bare minimum, training and releasing a model like this builds critical skills in their engineering workforce that can't really be done any other way for now. It also requires compilation of a training dataset, which is not only another critical human skill, but also potentially a secret sauce if it turns out to give your model specific behaviors or skills.
A big one is that it shows investors, partners, and future recruits that you are both willing and capable to work on frontier technology. Hard to put a price on this, but it is important.
For the rest of us, it turns out you can use this bestiary of public models, mixing pieces of models with their own secret sauce together to create something superior than any of them [1].
[1] https://sakana.ai/evolutionary-model-merge/
These bigger companies are releasing open source models for publicity. For Databricks and Snowflake, both want enterprise customers, and want to show they can handle swathes of data and orchestration jobs, what better way to show that than by training a model. The pretraining part is done on a GPU but everything before that is managed on the Snowflake infra or Databricks. Databricks' website does focus heavily on this.[1]
I am speculating here, they would use their own OSS models to create a proprietary version which does one thing well. Answering questions for customers based on their own data. It's not an easy problem to solve as it seemed initially given enterprises need high reliability. Need models which are good at tool use, and can be grounded well. They could have done it on an oss model, but only now we have Llama-3 which is trained to make tool use easy. (Tool use as in function calling and use of stuff like OpenAI's code interpreter)
[1]: https://www.databricks.com/product/data-intelligence-platfor...
I am not worried. Someone will make a search engine to find the model that knows your answer . It will be called Altavista or Lycos or something
These projects all started a long time ago, I expect, and they're all finishing now. Now that there are so many models, people will hopefully change focus from training new duplicate language models to exploring more interesting things. Multimodal, memory, reasoning.
Money is for accounting. AI is a new accountant. Therefore money no longer is what it was.
It’s mostly marketing for the company to appear to be modern. If you aren’t differentiated and if LLMs aren’t core to your business model, then there’s no loss from releasing weights. In other cases it is commoditizing something that would otherwise be valuable for competitors. But most of those 600K models aren’t high performers and don’t have large training budgets, and aren’t part of the “race”.
Training LLM is the cryptobro pivot.
And huggingface is hosting (randomly assuming 8-64 GB per model) 5..40 PB of models for free? That's generous of them. Or can the models share data? Ollama seems to have some ability to do that.
Most of those are fine tuned variants of open base models and shouldn't be included in the "every tech company" thing you're trying to communicate. Most of those are researcher or engineers learning how to work with these models, or are training them on specific data sets to improve their effectiveness in a particular task.
These fine tunes are not a huge amount of compute, most of them are doing these trainings on a single personal machine over a day or so of effort, NOT the six+ months across a massive cluster it takes to make a good base model.
That isn't wasted effort either. We need to know how to use these tools effectively, they're not going away. It's a very reductionist and inaccurate view of the world you're peddling in that comment.
Hype and jumping on the bandwagon are perfectly good reasons for a business. There's no business without risk. This is the cost of doing business which you want to explore greenfield projects.