62 replies
1d4h
Comments about the marketing driven nm measurements aside, this still looks like another solid advance for TSMC. They are already significantly ahead of Samsung and Intel on transistor density. TSMC is at 197 MTr/mm2 wile Samsung is at 150 MTr/mm2 and Intel is at 123 MTr/mm2. This 1.6nm process will put them around 230 MTr/mm2 by 2026. When viewed by this metric, Intel is really falling behind.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Intel has a 1.4nm process in the pipeline for ~2027. They just took delivery on their first high NA EUV machine in order to start working on it.
Their gamble however is that they need to figure out DSA, a long storied technology that uses self-forming polymers to allow less light to sharply etch smaller features.
If they figure out DSA, they will likely be ahead of TSMC. If not, it will just be more very expensive languishing.
Do you know the name of the company that produces the EUV machine? is it ASML?
It is my understanding that only ASML had cracked the EUV litography, but if there's another company out there, that would be an interesting development to watch.
>It is my understanding that only ASML had cracked the EUV litography
Ackshually, EUV was cracked by Sandia Labs research in the US, with EUV light sources built by Cymer in the US. ASML was the only one allowed to license the tech and integrate it into their steppers after they bough Cymer in 2013. Hence why US has veto rights to whom Dutch based ASML can sell their EUV steppers to, as in not to China, despite ow much ASML shareholders would like that extra Chinese money.
More on the history here:
https://www.asml.com/en/news/stories/2022/making-euv-lab-to-...
Pretty cool story of the National Lab system and the closest thing the US has to “government scientists” massively shaping the future.
Thanks for the source. I'm glad Bell labs pounced on the opportunity.
They don't need anyone else's money. Intel has bought all of TSMC's EUV and High-NA EUV machines for the next several years.
>They don't need anyone else's money
There's no such thing in capitalism. Limited supply semi is(was) a bidding war, where China had a blank cheque and was willing to outbid everyone else to secure semi manufacturing supremacy.
Do you think Intel or TSMC could have scored all that ASML supply at that price if China would have been allowed to bid as well? ASML would have been able to score way higher market prices per EUV stepper had China been allowed in the game, and therefore higher profits.
You think ASML shareholders hate higher profits or what? Nvidia sure didn't during the pandemic. You wanted a GPU? Great, it would cost you now 2x-3x the original MSRP because free market capitalism and the laws of supply and demand.
More like it was started. There were a ton of gnarly problems left that took over ten years and billions of € to solve.
Producing a few flashes of EUV and getting a few photons on the target is relatively easy. Producing a lot of EUV for a long time and getting a significant fraction (...like 1%) of the photons on the target is very hard.
EUV was supposed to ship in the early 2000s and the work on it started in earnest the 90s. It turned out that EUV is way harder than anyone imagined. The only reason we did stuff like immersion DUV was because we couldn’t get EUV to work.
Did not know that. Thanks
It’s ASML.
Yes, and Intel was the first to install the first High-NA EUV machine from ASML, TWINSCAN EXE:5000 https://www.youtube.com/watch?v=3PCtf1ONYMU
ps. Intel used to own 15% of ASML in 2012, now they own less than 2%.
The nomenclature for microchip manufacturing left reality a couple generations ago. Intel’s 14A process is not a true 14A half-pitch. It’s kind of like how they started naming CPUs off “performance equivalents” instead of using raw clock speed. And this isn’t just Intel. TSMC, Samsung, everyone is doing half-pitch equivalent naming now a days.
This is the industry roadmap from 2022: https://irds.ieee.org/images/files/pdf/2022/2022IRDS_Litho.p... If you look at page 6 there is a nice table that kind of explains it.
Certain feature sizes have hit a point of diminishing returns, so they are finding new ways to increase performance. Each generation is better than the last but we have moved beyond simple shrinkage.
Comparing Intel’s 14A label to TSMCs 16A is meaningless without performance benchmarks. They are both just marketing terms. Like the Intel/AMD CPU wars. You can’t say one is better because the label says it’s faster. There’s so much other stuff to consider.
"Likely better" doesn't come from 14A vs 16A. It comes from Intel using High NA-EUV vs TSMC using double pattern Low NA-EUV.
If Intel pulls off DSA, they will be using a newer generation of technology compared to TSMC using an optimized older generation. Could TSMC still make better chips? Maybe. But Intel will likely be better.
I am not sure where that would come from. There is nothing about dsa that means this.
Dsa is one of many patterning assist technologies, just...an old one. Neat, but not 'new'. You use patterning assist to make smaller, more regular features, which is exactly what the 16a vs 18a refers to.
That has somewhat less to do with performance, which is tied as much to material, stress, and interface parameters. Nothing gets better from being smaller in the post dennard scaling era, the work of integration is making better devices anyway.
Patterning choices imply different consequences. For example,.a.double euv integration can take advantage of spacer assists to reduce ler and actually improve cdu even with a double expose. Selective etch can improve bias, spacer trickery can create uniquely small regular features that cannot be done with single patterns. Conversely, overlay trees get bushier, and via CD variance can cause horrific electrical variance. It is complicated, history dependent, and everything is on the developmental edge.
DSA is what is going to make it possible for Intel to compete at all. Without it, they are going to have fancy machines in fancy foundries that are too expensive to attract any customers.
To the best of my knowledge, DSA never made it out of the lab.
But still, what is stopping others from also developing DSA? I am not sure the technology alone will be Intel's savior. They've been on the decline for a while, ever since they took a jab at Nvidia for releasing CUDA, they demonstrated a narrow vision, consistently, and now they're playing a catch up game.
Is Intel working on "an optimized older generation" as a backup plan? I don't follow semiconductors very closely, but my impression is the reason they're "behind" is they bet aggressively on an advanced technology that didn't pan out.
From what I remember the aprocyphal story is that Intel dragged their feet on adopting EUV and instead tried to push multi-patterning past it's reasonable limits.
If that's the actual root cause, then Intel's lagging is due to optimizing their balance sheets (investors like low capital expenditures) at the expense of their technology dominance.
would performance per watt be the right way to benchmark?
When comparing fab processes, you wouldn't want performance of a whole processor but rather the voltage vs frequency curves for the different transistor libraries offered by each fab process.
Benchmarks are tricky because it all depends on workload and use case. If you are in a VR headset for example, it’s all about power envelope and GPU flops. If you are in a Desktop used for productivity it might be all about peak CPU performance.
Very interesting document - lots of numbers in there for real feature sizes that I had not seen before (Table LITH-1).
And this snippet was particularly striking:
Chip making in Taiwan already uses as much as 10% of the island’s electricity.
DSA = Directed Self-Assembly
Intel says a lot of things but until they put them out in the field I don't believe a word they say
Not understanding chip design - but is it possible to get more computational bang with less transistors - are there some optimizations to be had? Better design that could compensate for bigger nodes?
Yes, generally one of the trends has been movement toward specialized coprocessors/accelerators. This was happening before the recent AI push and has picked up steam.
If you think of an SOC, the chip in your phone, more and more of the real estate is being dedicated to specialized compute (AI accelerators, GPUs, etc. vs general purpose compute (CPU).
At the enterprise scale, one of the big arguments NVIDIA has been making, beyond their value in the AI market, has been the value of moving massive, resource intense workloads from CPU to more specialized GPU acceleration. In return for the investment to move their workload, customers can get a massive increase in performance per watt/dollar.
There are some other factors at play in that example, and it may not always be true that the transistors/mm^2 is always lower, but I think it illustrates the overall point.
JavaScript accelerator would probably half the power consumption of the world. The problem is just, that as soon as it would have widespread usage it would probably already be too old.
Reminiscent of the Java CPUs: Not even used for embedded (ironically the reason Java was created?). And not used at all by the massive Java compute needed for corporate software worldwide?
Weren't they used in Java Cards?
Basically, every single credit card sized security chip (including actual credit cards, of course) is a small processor running Java applets. Pretty much everyone has one or more in their wallet. I'd assume those were actual Java CPUs directly executing bytecode?
Not sure: https://en.wikipedia.org/wiki/Java_processor doesn't seem to mention any in current use. I am ignorant of the actual correct answer: I had simply presumed it is simpler to write the virtual machine using a commercial ISA than to develop a custom ISA.
https://en.wikipedia.org/wiki/Java_Card_OpenPlatform has some history but nothing jumped out to answer your question.picoJava processors (Sun Microsystems) https://www.cnet.com/culture/sun-releases-complete-chip-desi...
Patriot Scientific's Ignite processor family https://www.cpushack.com/2013/03/02/chuck-moore-part-2-from-...
ARM Jazelle technology https://developer.arm.com/documentation/ddi0222/b/introducti...
https://www.eetimes.com/nazomi-offers-plug-in-java-accelerat...
It's all dot-com era stuff and Sun Microsystems also created a Java OS that could run directly on hardware without a host operating system.
That's about it
No, credit cards do not have CPUs or run Java code.
I believe ARM has some instructions that is JavaScript specific so we're kinda in that direction already.
Back in the day, they supported byte code execution - https://en.wikipedia.org/wiki/Jazelle
Yeah the https://developer.arm.com/documentation/dui0801/h/A64-Floati... but a full jit helper that is generalized is way way harder and as said will take a long time tobe generally available. Just look at wasmgc and that only has the minimum denominator.
The design optimization software for modern semiconductors is arguably the most advanced design software on earth with likely tens if not hundreds of millions of man-years put into it. It takes into account not only the complex physics that apply at the nano-scale but also the interplay of the various manufacturing steps and optimizes trillions of features. Every process change brings about new potential optimizations, so rather than compensating for bigger nodes it actually widens the gap further. By analogy, the jump from hatchet to scalpel in the hands a layman is far less than the jump from hatchet to scalpel for a skilled surgeon.
How is this kind of software developed without becoming a massive pile of spaghetti code?
As someone who worked for a startup that was bought by Cadence: I have some bad news for you about that.
What about the effect of heat? More transistors per area equate a hotter chip, no?
More transistors switching I thought? It isn't about raw transistors e.g. memory isn't as power hungry as GPU?
Heh, as long as you're not talking about UX...
Yeah, I don't think we really have any equivalent technology that is advanced or as detailed as chip making. Chip making is kind of the parent of pretty much every other technology we have at this point.
Some yeah, but many of these optimizations aren't across-the-board performance improvements, but rather specializations that favor specific kinds of workloads.
There are the really obvious ones like on-board GPUs and AI accelerators, but even within the CPU you have optimizations that apply to specific kinds of workloads like specialized instructions for video encode/decode.
The main "issue", such as it is, is that this setup advantages vertically integrated players - the ones who can release software quickly to use these optimizations, or even going as far as to build specific new features on top of these optimizations.
For more open platforms you have a chicken-and-egg problem. Chip designers have little incentive to dedicate valuable and finite transistors to specialized computations if the software market in general hasn't shown an interest. Even after these optimizations/specialized hardware have been released, software makers often are slow in adopting them, resulting in consumers not seeing the benefit for a long time.
See for example the many years it took for Microsoft to even accelerate the rendering of Windows' core UI with the GPU.
Everyone generally does that before sending the design to the fab.
Not to say that improvements and doing more with less are impossible, they probably aren't, but it's going to require significant per design human effort to do that.
Such optimisation would apply equally to the more dense processes, though.
In general, yes, but all the chip design companies have already invested a whole lot of time and engineering resources into squeezing as much as possible from each transistor. But those kinds of optimizations are certainly part of why we sometimes see new CPU generations released on the same node.
Stupid beginner question: is MTr/mm² really the right thing to be looking at? Shouldn't it be more like mm²/MTr ? This feels kind of like these weird "miles per gallon" units, when "gallons per mile" is much more useful...
200 million transistors per square millimeter.
Gallons per mile only makes sense when you are talking about dragsters.
gallons per hundred miles make much more sense than that.
incidentally, this is the measure rest of the world is advertising, except usually in liters per 100km.
there's a good reason for this: comparisons linear instead of inversely proportional. 6l/100km is 50% better than 9l/100km. 30mpg vs 20mpg is... not as simple.
How so?
Gallons per hundred miles would be more useful.
I guess it's a matter of approach. Europeans are traveling familiar, constant distances and worry about fuel cost. Americans just fill up their tank and worry how far they can go :)
If I buy 2 gallons of gas, and my car gets 30 mpg, then I can go 60 miles. Doesn't seem that hard to me. Need the other way around? I need to go 100 miles. At 30 miles per gallon, that's a little over 3 gallons. This is simple mental math.
What’s the argument for either? They are, of course, equivalent… might as well pick the one where bigger=better.
Are intel really just the best chip designers on the earth or why can they compete with such densities with AMD?
I'd say they haven't been very competitive with AMD in performance per watt/dollar in the ryzen era, specifically due to process advantage. (On CPU dies especially, with less advantage for AMDs I/O dies.) I'd agree they have done a good job advancing other aspects of their designs to close the gap, though.
Its so hard to even fathom 200+ Million Transistors in 1 square millimeter !
And, to think, it's all done with light !
We live in interesting times !
Well, "extreme UV" these days. 13.5nm, larger than the "feature size". And even that required heroic effort in development of light sources and optics.
Would it be that x2 (for front & back)?
E.g., 230 on front side and another 230 on back side = 460 MTr/mm2 TOTAL
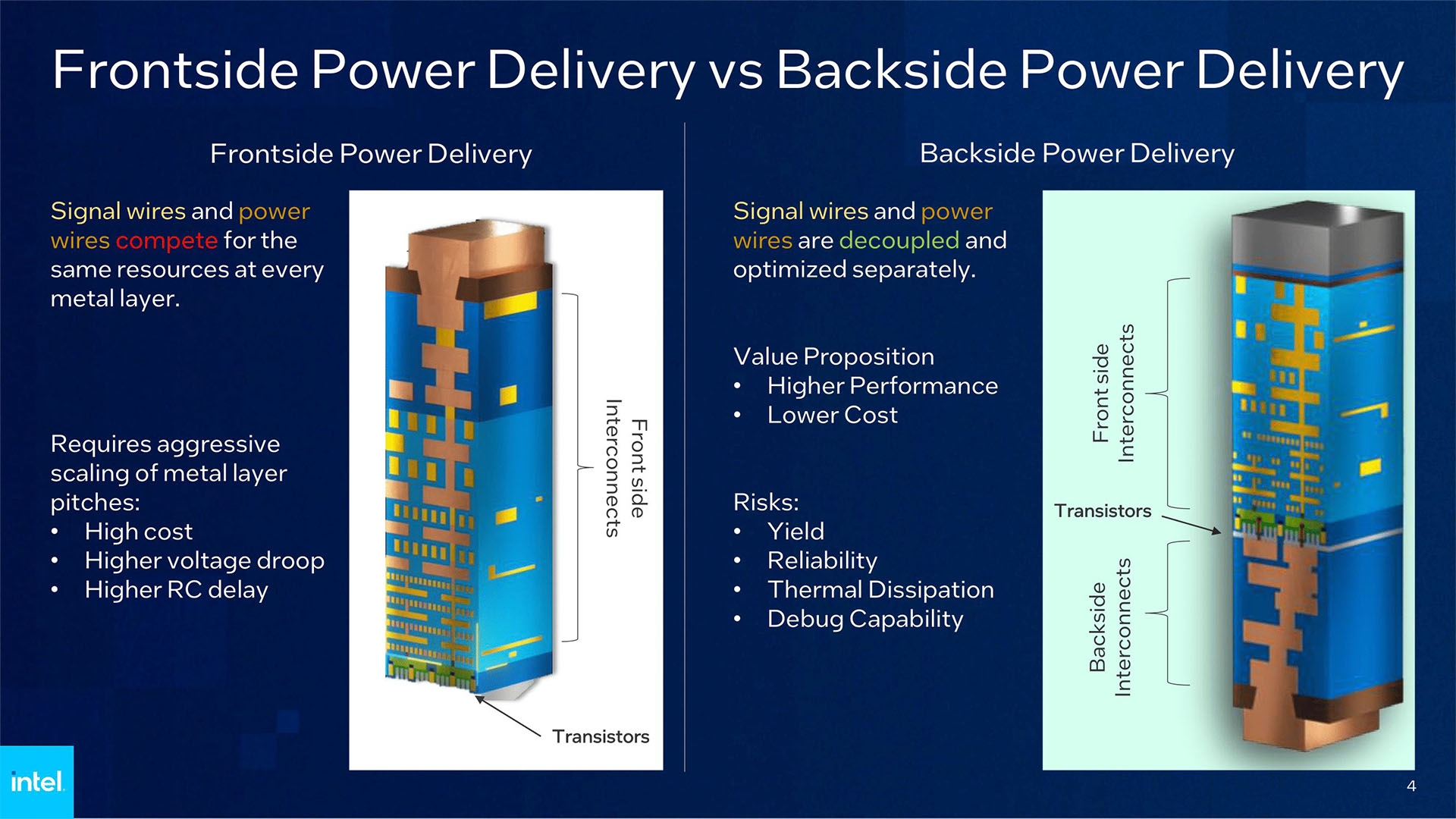
BSPDN is not about putting devices on the front and back, the logic layer is still mostly 2D, it's about the power connects moving to the back of the chip so there's less interference with logic and larger wiring can be used.
Translating 197 M/mm2 into the dimensions of a square, we get a dimension of 71nm. If we compute the "half-pitch", that's 35.5nm.
230 M/mm2 translates to 33nm "half-pitch".
Of course, transistors aren't square and aren't so densely packed, but these numbers are more real IMO.