54 replies
1d4h
This is a fascinating idea, but (honest question, not a judgement) would the output be reliable? It would be hard to identify hallucinations since recompiling could produce different machine code. Particularly if there is some novel construct that could be a key part of the code. Are there ways of also reporting the LLMs confidence in sections like this when running generatively? It’s an amazing idea but I worry it would stumble invisibly on the parts that are most critical. I suppose it would just need human confirmation on the output
{kind=link}
This is why round-tripping the code is important.
If you decompile the binary to source, then compile the source back to binary you should get the original binary.
You just need to do this enough times until the loss drops to some acceptable amount.
It's a great task for reinforcement learning, which is known to be unreasonably effective for these types of problems.
You really can't expect that if you're not using exactly the same version of exactly the same compiler with exactly the same flags, and often not even then.
You try your best, and if you provide enough examples, it will undoubtedly get figured out.
I think you're misunderstanding OP's objection. It's not simply a matter of going back and forth with the LLM until eventually (infinite monkeys on typewriters style) it gets the same binary as before: Even if you got the exact same source code as the original there's still no automated way to tell that you're done because the bits you get back out of the recompile step will almost certainly not be the same, even if your decompiled source were identical in every way. They might even vary quite substantially depending on a lot of different environmental factors.
Reproducible builds are hard to pull off cooperatively, when you control the pipeline that built the original binary and can work to eliminate all sources of variation. It's simply not going to happen in a decompiler like this.
Well, no, but yes.
The critical piece is that this can be done in training. If I collect a large number of C programs from github, compile them (in a deterministic fashion), I can use that as a training, test, and validation set. The output of the ML ought to compile to the same way given the same environment.
Indeed, I can train over multiple deterministic build environments (e.g. different compilers, different compiler flags) to be even more robust.
The second critical piece is that for something like a GAN, it doesn't need to be identical. You have two ML algorithms competing:
- One is trying to identify generated versus ground-truth source code
- One is trying to generate source code
Virtually all ML tasks are trained this way, and it doesn't matter. I have images and descriptions, and all the ML needs to do is generate an indistinguishable description.
So if I give the poster a lot more benefit of the doubt on what they wanted to say, it can make sense.
Oh, I was assuming that Eager was responding to klik99's question about how we could identify hallucinations in the output—round tripping doesn't help with that.
If what they're actually saying is that it's possible to train a model to low loss and then you just have to trust the results, yes, what you say makes sense.
I haven't found many places where I trust the results of an ML algorithm. I've found many places where they work astonishingly well 30-95% of the time, which is to say, save me or others a bunch of time.
It's been years, but I'm thinking back through things I've reverse-engineered before, and having something which kinda works most of the time would be super-useful still as a starting point.
Have you ever trained a GAN?
Technically, yes!
A more reasonable answer, though, is "no."
I've technically gone through random tutorials and trained various toy networks, including a GAN at some point, but I don't think that should really count. I also have a ton of experience with neural networks that's decades out-of-date (HUNDREDS of nodes, doing things like OCR). And I've read a bunch of modern papers and used a bunch of Hugging Face models.
Which is to say, I'm not completely ignorant, but I do not have credible experience training GANs.
That's true but a solvable problem. I once tried to reproduce the build of an uncooperative party and it was mainly tedious and boring.
The space of possible compiler arguments is huge, but ultimately what is actually used is mostly on a small surface.
Apart from that, I wrote a small tool to normalize the version string, timestamps and file path' in the binaries before I compared them. I know there are other sources of non-determinism, but these three things were enough in my case.
The hardest part were the numerous file path' from the build machine. I had not expected that. In hindsight, stripping both binaries before comparison might have helped, but I don't remember why I didn't do that.
What exactly are you suggesting will get figured out?
The mapping from binary to source code.
Even ignoring all sources of irreproducibility, there does not exist a bijection between source and binary artifact irrespective of tool chain. Two different toolchains could compile the same source to different binaries or different sources to the same binary. And you absolutely shouldn't be ignoring sources of irreproducibility in this context, since they'll cause even the same toolchain to keep producing different binaries given the same source.
Exactly, but neither the source nor the binary is what's truly important here. The real question is: can the LLM generate the functionally valid source equivalent of the binary at hand? If I disassemble Microsoft Paint, can I get code that will result in a mostly functional version of Microsoft Paint, or will I just get 515 compile errors instead?
This is what I thought the question was really about.
I assume that an llm will simply see patterns that look similar to other patterns and make assosciations and assume ewuivalences on that level, meanwhile real code is full of things where the programmer, especially assembly programmers, modify something by a single instruction or offset value etc to get a very specific and functionally important result.
Often the result is code that not only isn't obvious, it's nominaly flatly wrong, violating standards, specs, intended function, datasheet docs, etc. If all you knew were the rules written in the docs, the code is broken and invalid.
Is the llm really going to see or understand the intent of that?
They find matching patterns in other existing stuff, and to the user who can not see the infinite body of that other stuff the llm pulled from, it looks like the llm understood the intent of a question, but I say it just found the prior work of some human who understood a similar intent somewhere else.
Maybe an llm or some other flavor of ai can operate some other way like actually playing out the binary like executing in a debugger and map out the results not just look at the code as fuzzy matching patterns. Can that take the place of understanding the intents the way a human would reading the decompiled assembly?
Guess we'll be finding out sooner of later since of course it will all be tried.
The question was about the reverse mapping.
Except LLMs cannot reason.
LLMs can mimic past examples of reasoning from the dataset. So, it can re-use reasoning that it has already been trained on. If the network manages to generalize well enough across its training data, then it can get close to reproducing general reasoning. But it can't yet fully get there, of course.
Do you have evidence LLMs can indeed generalize outside their training data distribution?
https://twitter.com/abacaj/status/1721223737729581437/photo/...
No. I know only that they can generalize within it, and only to a limited degree, but don't have solid evidence of even that.
Err, no, sorry, it won't. Compilers don't work that way. There's a lot of ways to compile down source to machine code and the output changes from compiler version to compiler version. The LLM would have to know exactly how the compiler worked at which version to do this. So the idea is technically possible but not technically feasible.
Maybe we then need an LLM to tell us if two pieces of compiled code are equivalent in an input-output mapping sense (ignoring execution time).
I'm actually serious; it would be exceedingly easy to get training data for this just by running the same source code through a bunch of different compiler versions and optimization flags.
Why would an llm be the tool for that job?
Without analytical thinking how else would you come to conviction that two functions are identical, for a computationally unfeasible number of possible inputs?
An LLM cannot do this. I don’t even mean this in a formal sense, because your problem is addressed by Rice’s Theorem, which places bounds on what any system (LLM or not) can do here; I mean it in the sense that an LLM isn’t even appropriate to use here because the best it can possibly do is provide you with its best guess at the answer. And while this might be a useful property for decompilation in general that’s not what was being discussed here.
Rice's theorem does NOT prevent a program from giving correct answers to non-trivial properties of programs (including the halting problem or other undecidable problems) for 99.99% of inputs and "I don't know" for 0.01% of inputs. It only states that you cannot write a program that provides a correct and definitive yes-or-no for 100% of inputs.
For a decompiler, being able to decompile even 90% of programs would be awesome. We're not looking for theoretical perfectness.
Right.
A less formidable problem with higher chances of succeeding is from a given binary to figure out first compiler, compiler-version, compiler-flags.
From there you could have a model for every combination or at least a model for the compiler variant and use the other info (version, flags) as input to the model.
Yes, that's a limitation of trying to ensure exact binary reconstruction. Luckily there is also a separate line of work on detecting the compiler version and optimization flags based on a binary – it turns out this is not that hard and it's easy to get a bunch of labeled data for a classifier.
If folks are interested in reading more there's a nice paper by Grammatech on the idea: https://eschulte.github.io/data/bed.pdf (though it's pre-LLM and uses evolutionary algorithms on the initial decompilation to search for a version that recompiles exactly).
Doesn't that depend on the compiler's version though? Or, for that matter, even the sub-version. Every compiler does things differently.
From the README:
As this is in the metrics section, I guess fully automating this is not part of the research.
According to the project's README, they only seem to be checking mere "re-compilability" and "re-executability" of the decompiled code, though.
The way to do this is to have a formal verification tool that takes the input, the output, and a formal proof that the input matches the semantics of the output, and have the LLM create the formal proof alongside the output. Then you can run the verification tool to check if the LLM’s output is correct according to the proof that it also provided.
Of course, building and training an LLM that can provide such proofs will be the bigger challenge, but it would be a safe a way to detect hallucinations.
That would require the tool to prove the equivalence of the two programs, which is generally undecidable. Maybe this could be weakened to preserving some properties of the program.
No, it would not. It would require the LLM to provide a proof for the program that it outputs, which seems reasonable in the same way that a human decompiling a program would be able to provide a record of his/her reasoning.
The formal verifier would then merely check the provided proof, which is a simple mechanical process.
This is analogous to a mathematician providing a detailed proof and a computer checking it.
What is impossible due to undecidability is for two arbitrary programs, to either prove or disprove their equivalence. However, the two programs we are talking about are highly correlated, and thus not arbitrary at all with respect to each other. If an LLM is able to provide a correct decompilation, then in principle it should also be able to provide a proof of the correctness of that decompilation.
Yes, and then someone needs to check that proof. It’s not particularly clear if that decompilation proof would be any more helpful than just doing the lifting by hand.
No, nobody needs to check the proof; that's the whole point of formal theorem proving, the machine checks it for you.
That doesn’t mean that it’s impossible, right? Just that no tool is guaranteed to give an answer in any case. And those cases might be 90%, 10% or it-doesn’t-matter-in-practice %
What if there are hallucinations in the verification tool?
I think the idea is that you'd have two independently-develooed systems, one LLM decompiling the binary and the other LLM formally verifying. If the verifier disagrees with the decompiler you won't know which tool is right and which is wrong, but if they agree then you'll know the decompiled result is correct, since both tools are unlikely to hallucinate the same thing.
No, the idea is that the verifier is a human-written program, like the many formal-verification tools that already exist, not an LLM. There is zero reason to make this an LLM.
It makes sense to use LLMs for the decompilation and the proof generation, because both arguably require creativity, but a mere proof verifier requires zero creativity, only correctness.
Then it's not a formal verification tool. Generative models are profoundly unfit for that purpose.
There may be bugs, but not hallucinations. Bugs are at least reproducible, and the source code of the verification tool is much, much smaller than an LLM, so has a much higher chance of its finite number of bugs to be found, whereas with an LLM it is probably impossible to remove all hallucinations.
To turn your question around: What if the compiler that compiles your LLM implementation “hallucinates”? That would be the closer parallel.
Good luck formally proving Linux.
The goal is to prove that the source code matches the machine code, not to prove that the code implements some intended higher-level semantics. This has nothing to do with formally proving the correctness of the Linux kernel.
Generators' nature is to hallucinate.
One man’s hallucination is another’s creativity.
Well we need to remember that "hallucination" here is not a concept but a language figure for the output of a stochastic parroting machine. So what you mentinoed would be a digitally induced halluciation out of some dancing matrix multiplications / electrons on silicon.
LLMs are by nature probabilistic, which is why they work reasonably well for "imprecise" domains like natural language processing. Expecting one to do decompilation, or disassembly for that matter, is IMHO very much a "wrong tool for the job" --- but perhaps it's just an exploratory exercise for the "just use an LLM" meme that seems to be a common trend these days.
The bigger argument against the effectiveness of this approach is that existing decompilers can already do a much better job with far less processing power.
In the future efficient rule based compilers and decompiler may be generated by AI systems trained on inputs and outputs of what we use today.
This effort is an exploration to find a radically different AI way that may give superior results.
Yes. For all the reasons you give above, AI for this job is not practical today.
One could as well use differential fuzzing.
I'm amazed that there are so many good responses above only this mentions fuzzing. In the context of security, inputs might be non-linear things like adjacent memory, so I don't see anyway to be confident about equilivancy without substantial fuzzing.
Honestly I just don't see a way to formally verify this at all, it's sounds like it could be a very useful tool but I don't see a way for it to be fully confident. But, heck, just getting you 90% of the way towards understanding it with LLMs is still amazing and useful in real life.
Even if it isn't fully reliable, often it's only necessary to modify a few functions for most changes one wants to make to a binary.
You'd therefore only need to recompile those few functions.
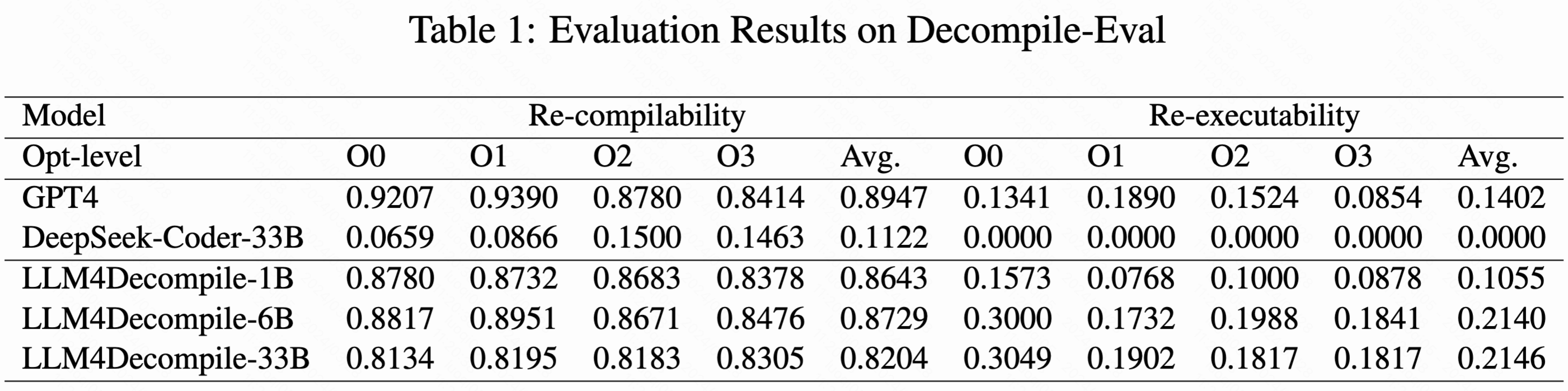
The detail how they measure this in the readme. This is directed at all the sibling comments as well!
TLDR they recompile and then re-execute (including test suites). From the results table it looks like GPT4 still "outperforms" their model in recompilation, but their recompiled code has a much better re-execution success rate (less hallucinations). But, that re-execution rate is still pretty lacking (around 14%), even if better than GPT4.
Sounds like it should be able to split the code into functions with inferred API, then you should be able to fuzz these functions in binary and source versions.