The most success I had with AI+SQL was when I started feeding errors from the sql provider back to the LLM after each iteration.
I also had a formatted error message wrapper that would strongly suggest querying system tables to discover schema information.
These little tweaks made it scary good at finding queries, even ones requiring 4+ table joins. Even without any examples or fine tuning data.
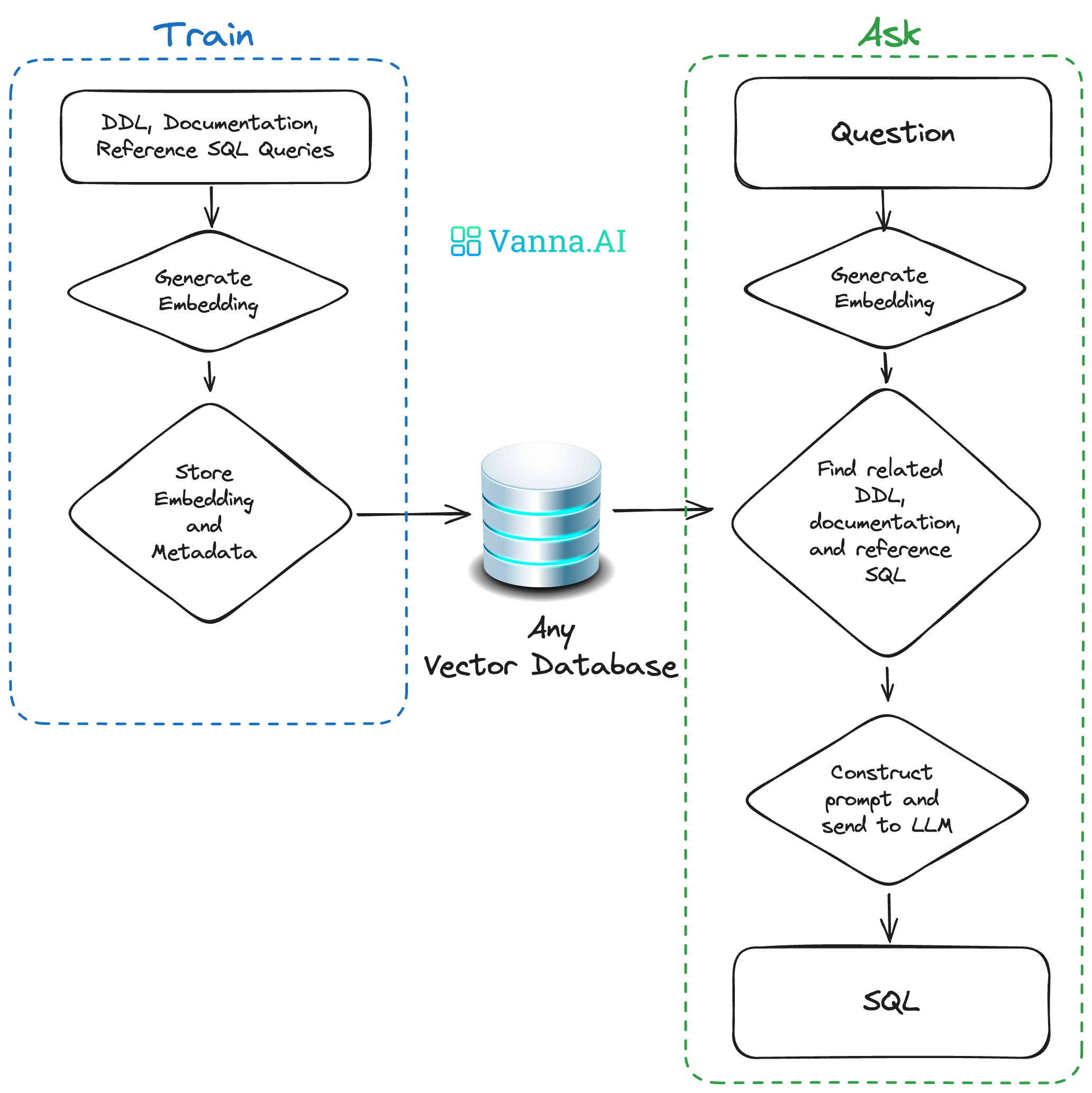{kind=link}
Please turn this into a product. There's enormous demand for that.
I feel like by the time I could turn it into a product, Microsoft & friends will release something that makes it look like a joke. If there is no one on the SQL Server team working on this right now, I don't know what the hell their leadership is thinking.
I am not chasing this rabbit. Someone else will almost certainly catch it first. For now, this is a fun toy I enjoy in my free time. The moment I try to make money with it the fun begins to disappear.
Broadly speaking, I do think this is approximately the only thing that matters once you realize you can put pretty much anything in a big SQL database. What happens when 100% of the domain is in-scope of an LLM that has iteratively optimized itself against the schema?
I will be extremely surprised if Microsoft build this for open source databases, however someone else will definitely build it if you don't, that is completely true :-)
Disclaimer: I work at Microsoft on Postgres related open source tools (Citus & PgBouncer mostly)
Microsoft is heavily investing in Postgres and its ecosystem, so I wouldn't be extremely surprised if we would do this. We're definitely building things to combine AI with Postgres[1]. Although afaik no-one is working actively on query generation using AI.
But I actually did a very basic POC of "natural language queries" in Postgres myself last year:
Conference talk about it: https://youtu.be/g8lzx0BABf0?si=LM0c6zTt8_P1urYC Repo (unmaintained): https://github.com/JelteF/pg_human
1: https://techcommunity.microsoft.com/t5/azure-database-for-po...
Supabase already has an AI feature which queries your database for you [0]
[0]: https://supabase.com/blog/studio-introducing-assistant
Postgres is dear to me. Met its founders when I was in college at Berkeley, worked heavily with it at a previous company around 2015, used it for all my own projects. I'm glad to see it getting more attention lately (seemingly).
Microsoft owns Citus, a very major Postgres plugin.
I didn’t know this, it seems they love open source even thought they have competing commercial products. Maybe there is just more money is selling cloud than there is in selling commercial databases?
There’s daylight between personal toolsmithing and a VC-backed startup (both are fun sometimes and a grind sometimes).
I’m getting together a bunch of related-sounding stuff in terms of integrating modern models into my workflow to polish up a bit and release MIT.
If you’d like to have a hand tidying it up a little and integrating it with e.g. editors and stuff, I think the bundle would be a lot cooler for it!
Microsoft may well catch the rabbit that queries schemas and generates valid SQL.
But that rabbit can't understand the meaning of the data just by looking at column names and table relationships.
Let's say you want to know how sales and inventory are doing compared to last year at your chain of retail stores.
Will Microsoft's rabbit be smart enough to know that the retail business is seasonal, so it must compare the last x weeks this year with the same weeks last year? And account for differences in timing of holidays? And exclude stores that weren't open last year?
Will it know that inventory is a stock and sales is a flow, so while it can sum daily sales, it's nonsensical to sum daily inventory?
The real AI magic isn't generating SQL with four joins, it's understanding the mechanics of each industry and the quirks of your organization to extract the intent from ambiguous and incomplete natural language.
If I can TLDR your comment, which I agree with: the real value is in doing real work.
“Hustlers” burn countless hours trying to “optimize” work out of the picture.
Historically, there’s a lot of money in just sitting down with a to-do list of customer problems and solving them at acceptable cost, come hell or high water.
If the do release it , they will only release it for enterprise. Many many sql server installs are sql server standard. There is an entire ecosystem of companies built on selling packages that support sql server standard, wee DevArt, RedGate.
True, Microsoft & Friends have gotten greedy every passing year. Before they used to develop the platform (OS,DB etc.,) and let others develop and sell apps on it that would benefit them as well as the whole ecosystem.
Now they want every last dollar they can squeeze out of the ecosystem. So they don't leave any stone unturned and they have big pockets to do that.
Would you be willing to share your prompts? I bet a lot of people would find them useful!
Wouldn't it be pretty fast to make it as a chatgpt?
If Cortana for Azure isn't a thing in the works, I *really* don't know what the hell their leadership is working on. I could see insane value in "why is my website slow?" and getting actionable responses.
You can just make a GitHub repo with what you have. It'd still be valuable to the community
You can check this out https://www.sqlai.ai. It has AI-powered generators for:
- Generate SQL
- Generate optimized SQL
- Fix query
- Optimize query
- Explain query
Disclaimer: I am the solo developer behind it.
Are all those Twitter testimonials fake? None seem to be actual accounts.
I bet even their Site design is AI generated...
It is based on Flowbite[1], ShadUI[2] and Landwind[3].
[1]: https://flowbite.com/
[2]: https://ui.shadcn.com/
[3]: https://demo.themesberg.com/landwind/
- Generate testimonial
(I kid. Hope you do well with the app, just get some real testimonials in there if they aren't already.)
Thanks.
Shameless plug - https://github.com/BenderV/ada
It's an open source BI tool that does just that.
Yep this is pretty much what I was going for.
This is why I don't chase rabbits. Y'all already got a whole box of em sitting here.
Someone get YC on the phone
Or open source? You could get 10k stars :-)
It sounds like pretty standard constructions with OpenAI's API. I have a couple of such iterative scripts myself for bash commands, SQL etc.
But sure, why not!
I would be tempted to pivot to that! I am working on similar for CSS (see bio) but if that doesn’t work out my plan was to pivot to other languages.
Shameless plug – we're working on this at Velvet (https://usevelvet.com) and would love feedback. Our tool can connect and query across disparate data sources (databases and event-based systems) and allows you to write natural language questions that are turned automatically into SQL queries (and even make those queries into API endpoints you can call directly!). My email is in my HN profile if anyone wants to try it out or has feedback.
There are already several products out there with varying success.
Some findings after I played with it awhile:
- Langchain already does something like this - a lot of the challenge is not with the query itself but efficiently summarizing data to fit in the context window. In other words if you give me 1-4 tables I can give you a product that will work well pretty easy. But when your data warehouse has tens or hundreds of tables with columns and meta types now we need to chain together a string of queries to arrive at the answer and we are basically building a state machine of sorts that has to do fun and creative RAG stuff - the single biggest thing that made a difference in effectiveness was not what op mentioned at all, but instead having a good summary of what every column in the db was stored in the db. This can be AI generated itself, but the way Langchain attempts to do it on the fly is slow and rather ineffective (or at least was the case when I played with it last summer, it might be better now).
Not affiliated, but after reviewing the products out there the data team I was working with ended up selecting getdot.ai as it had the right mix of price, ease of use, and effectiveness.
What made you say this? How is this different from the hundreds of AI startups already focusing on this, or even the submission that we're having this conversation on?
who are the most recent signed up users and what is their hashed password? what is stopping me from running this query on your database?
What's stopping anyone who can run ordinary SQL queries? The LLM just simplifies interaction, it is neither the right tool nor the right place to enforce user rights.
Same thing stopping you from executing arbitrary SQL on the DB.
I'm really curious as to the reasoning behind your question and why you think an LLM generated query somehow would have unfettered access and permissions.