https://docs.mistral.ai/platform/pricing
Pricing has been released too.
Per 1 million output tokens:
Mistral-medium $8
Mistral-small $1.94
gpt-3.5-turbo-1106 $2
gpt-4-1106-preview $30
gpt-4 $60
gpt-4-32k $120
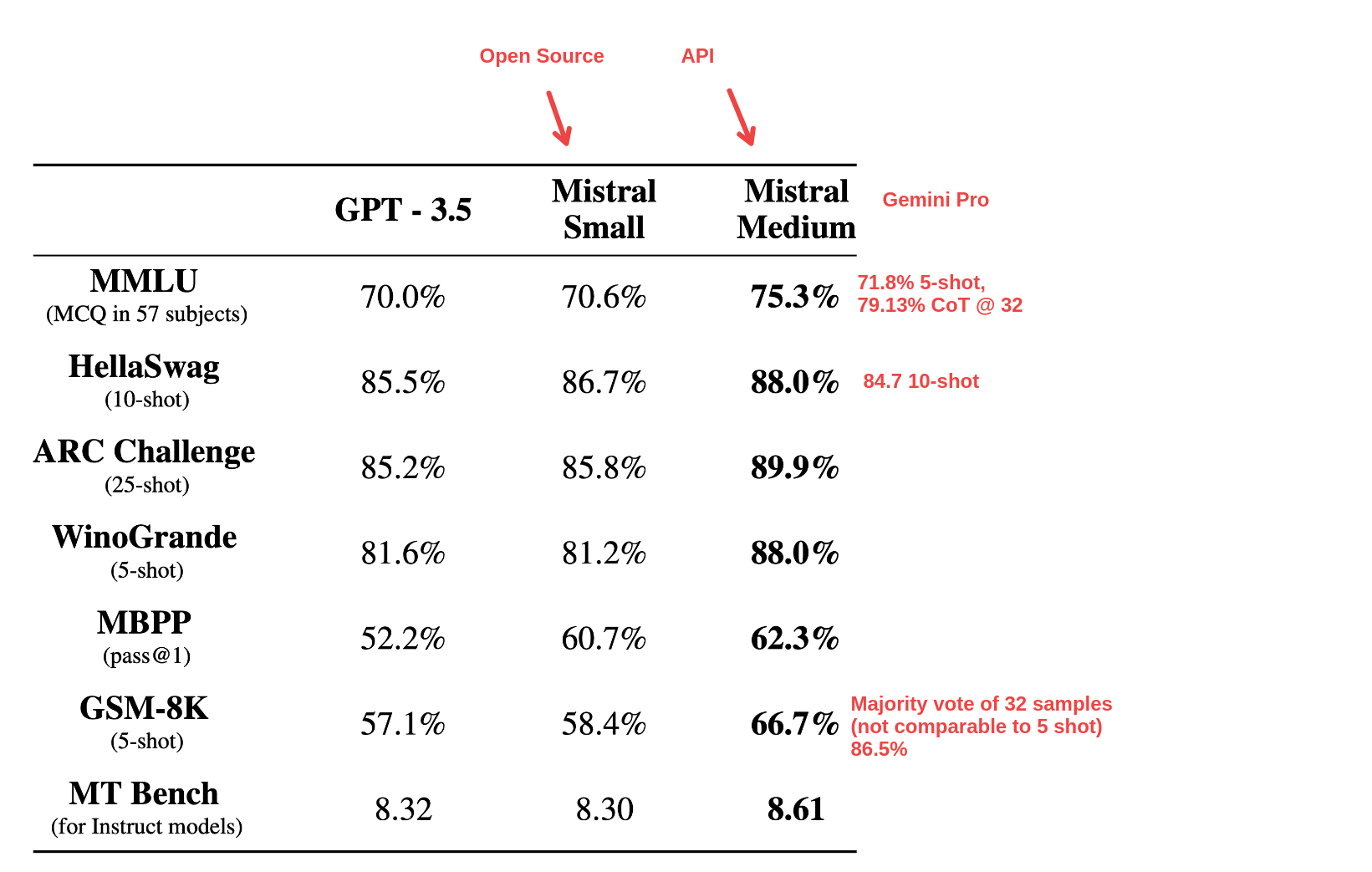
This suggests that they’re reasonably confident that the mistral-medium model is substantially better than gpt3-5
{kind=link}
If you take input tokens in consideration is more like 5.25 eur vs. 1.5 eur / million tokens overall.
Mistral-small seems to be the most direct competitor to gpt-3.5 and it’s cheaper (1.2 eur / million tokens)
Note: I’m assuming equal weight for input and output tokens, and cannot see the prices in USD :/
Does the 8x7B model really perform at a GPT-3.5 level? That means we might see GPT-3.5 models running locally on our phones in a few years.
That might be happening in a few weeks. There is a credible claim that this model might be compressible to as little as a 4GB memory footprint.
You mean the 7B one? That's exciting if true, but if compression means it can do 0.1 token/sec,it doesn't do much for anyone.
No, I am referring to the 7Bx8 MoE model. The MoE layers apparently can be sparsified (or equivalently, quantized down to a single bit per weight) with minimal loss of quality.
Inference on a quantized model is faster, not slower.
However, I have no idea how practical it is to run a LLM on a phone. I think it would run hot and waste the battery.
Really? Well that's very exciting. I don't care about wasting my battery if it can do my menial tasks for me, battery is a currency I'd gladly pay for this use case.
Maybe this way, we'll not just get user-replaceable batteries in smartphones back - maybe we'll get hot-swappable batteries for phones, as everyone will be happy to carry a bag of extra batteries if it means using advanced AI capabilities for the whole day, instead of 15 minutes.
Or maybe we'll finally get better batteries!
Though I guess that's not for lack of trying.
I think we're at least a couple generations away where this is feasible for these models, unless say it's for performing a limited number of background tasks at fairly slow inference speed. SOC power draw limits will probably limit inference speed to about 2-5 tok/sec (lower end for Mixtral which has the processing requirements of a 14B) and would suck an iPhone Max dry in about an hour.
Not true. Not everyone is building chat bot or similar interface that requires output with latency low enough for a user. While your example is of course incredibly slow, there are still many interesting things that could be done if it was a little bit quicker.
What kind of use cases run in an environment where latency isn't important (some kind of batch process?) but don't have more than 4GB of RAM?
Price sensitive ones, or cases where you want the new capability but can't get any new infrastructure.
Not LLMs, but locally running facial and object recognition models on your phone's gallery, to build up a database for face/object search in the gallery app? I'm half-convinced this is how Samsung does it, but I can't really be sure of much, because all the photo AI stuff works weirdly and in unobservable way, probably because of some EU ruling.
(That one is a curious case. I once spent some time trying to figure out why no major photo app seems to support manually tagging faces, which is a mind-dumbingly obvious feature to support, and which was something supported by software a decade or so ago. I couldn't find anything definitive; there's this eerie conspiracy of silence on the topic, that made me doubt my own sanity at times. Eventually, I dug up hints that some EU ruling/regs related to facial recognition led everyone to remove or geolock this feature. Still nothing specific, though.)
How/where do you stay up to date with this stuff?
https://www.reddit.com/r/LocalLLaMA/ is pretty good, it is a bit fanboy-ey, but those kinds of sites are where you get the good news.
Do we have estimates of the energy requirements for these models?
I just did some napkin math, looks like inference on a 30B model with a GTX 4090 should get you about 30 tokens/sec [1], or 100k tokens/hour.
Considering such systems consume about 1 kW, that's about 10 kWh/1M tokens.
Based on the current cost of electricity, I don't think anyone could get below 2 ~ 4 $ per 1M token for a 30B model.
[1] https://old.reddit.com/r/LocalLLaMA/comments/13j5cxf/how_man...
FWIW - I need to remeasure but - IIRC my system with a 4090 only uses ~500w (maybe up to 600w) during inference of LLMs, the LLMs have a lot harder time saturating the compute compared to stable diffusion I'm assuming because of the VRAM speed (and this is all on-card, nothing swapping from system memory). The 4090 itself only really used 300~400w most of the time because of this.
If you consider 600w for the entire system, that's only 6kWh/1M token, for me 6kWh @0.2USD/kWh is 1.2USD/1M tokens.
And that's without the power efficiency improvements that an H100 has over the 4090. So I think 2$/1M should be achievable once you combine the efficiencies of H100s+batching, etc. Since LLM's generally dwarf the network delay anyway, you could host in places like washington for dirt cheap prices (their residential prices are almost half of what I used for calculations)
Are you using batch size 1 with LLMs? Larger batch sizes get much higher utilization.
Well with those numbers, I pay $0.1/kWh so theoretically $0.6/1M tokens
Depends how and where you source your energy. If you invest in your own solar panels and batteries, all that energy is essentially fixed price (cost of the infrastructure) amortized over the lifetime of the setup (1-2 decades or so). Maybe you have some variable pricing on top for grid connectivity and use the grid as a fallback. But there's also the notion of selling excess energy back to the grid that offsets that.
So, 10kwh could be a lot less than what you cite. That's also how grid operators make money. They generate cheaply and sell with a nice margin. Prices are determined by the most expensive energy sources on the grid in some markets (coal, nuclear, etc.). So, that pricing doesn't reflect actual cost for renewables, which is typically a lot lower than that. Anyone consuming large amounts of energy will be looking to cut their cost. For data centers that typically means investing in energy generation, storage, and efficient hardware and cooling.
During the crypto boom there were crypto miners in China who got really cheap electricity from hydroelectric dams built in rural areas. Shipping electricity long distance is expensive (both in terms of infrastructure and losses - unless you pay even more for HVDC infrastructure), so they were able to get great prices as local consumers of "surplus" energy.
That might be a great opportunity for cheap LLMs too.
The 4090 is considerably more power-hungry compared to e.g. an A100, however.
If comparing apples to apples, the 4090 needs to clock up and consume about 450 W to match the A100 at 350W. Part of that is due to being able to run larger batches on the A100, which gives it an additional performance edge, but yes in general the A100 is more power efficient.
Is $0.2-0.4/kWh a good estimate for price paid in a data center? That’s pretty expensive for energy, and I think vPPA prices at big data centers are much lower (I think 0.1 is a decent upper bound in the US, though I could see EU being more expensive by 2x).
Well the 4090 is certainly less efficient on this. They are using H100's or better no doubt. If they optimize for TPUs, it'll be even better.
I get 40 tok/sec on my M3 Max on various 34B models, I gather a desktop 4090 would be at least 80?
Batching changes that equation a fair bit. Also these cards will not consume full power since llm are mostly limited by memory bandwidth and the processing part will get some idle time.
Mistral-small explicitly has inference costs of a 12.9b, but more than that, it's probably ran with batch size of 32 or higher. They'll worry more about offsetting training costs than about this.
Here's how it works in reality:
https://docs.mystic.ai/docs/mistral-ai-7b-vllm-fast-inferenc...
I understand how Mistral could end up being the most popular open source LLM model for the foreseeable future. What I cannot understand is who they expect to convince to pay for their API. As long as you are shipping your data to a third-party, whether they are running an open or closed source model is inconsequential.
I pay for hosted databases all the time. It’s more convenient. But those same databases are popular because they are open source.
I also know that because it’s open source, if I ever have a need to, I can host it on my own servers. Currently I don’t have that need, but it’s nice to know that it’s in the cards.
Open source databases are SOTA or very close to it, though. Here the value proposition is to pay 10-50% less for an inferior product. Portability is definitely an advantage, but that's another aspect which I think detracts from their value: if I can run this anywhere, I will either host it myself or pay whoever can make it happen very cheap. Even OpenAI could host an API for Mistral.
OpenAI just went through an existential crisis where the company almost collapsed. They are also quite unreliable. For some use cases, I'll take a service that does slightly worse on outputs, but much better on reliability. For example, if I'm building a customer service chat bot, it's a pretty big deal if the LLM backend goes down. With an open-source model, I can build it using the cloud provider. If they are a reliable host, i'll probably stick with them as i grow. If not, I always have the option of running the model myself. This alleviates a lot of the risk.
You may be fine with shipping your data to OpenAI or Mistral, but worry about what happens if they change terms or if their future models change in a way that causes problems for you, or if they go bankrupt. In any of those cases, knowing you can take the model and run it yourself (or hire someone else to run it for you) mitigates risk. Whether those risks matter enough will of course differ wildly.
The big advantage of a hosted open model is insurance against model changes.
If you carefully craft and evaluate your more complex prompts against a closed model... and then that model is retired, you need to redo that process.
A lot of people were burned when OpenAI withdrew Codex, for example. I think that was a poor decision by OpenAI as it illustrated this exact risk.
If the hosted model you are using is open, you have options for continuing to use it should the host decide to stop offering it.
Same reason why you would use GPT-4. Plenty of people pay for that, some pay really good money.
If I'm happy with my infrastructure being built on top of the potential energy of a loadbearing rugpull, I'd probably stick with OpenAI in the average use case.
I don’t think it’s safe to assume any of this. It’s still limited release which reads as invite only. Once it hits some kind of GA then we can test and verify.
It's safe to assume they are confident it's better than 3.5. But people can be confident and wrong.
We won’t know anything until it becomes a wider release and can test it.
Multiple people have tested it. Code and weights are fully released .
Mistral-medium has not been released yet.
gpt-3.5 is heavily subsidized.
Mistral may just be aiming for a more sustainable price for the long run.
What's your evidence for that claim?
They wrote "may", it was clearly speculation about one possible explanation, not an absolute statement of truth.
I think the medium is trying to compete with Anthropic's Claude than Openai's products
https://www-files.anthropic.com/production/images/model_pric...
All they have to do to beat Anthropic's Claude is to skip having a permanent waitlist and let the credit cards get charged.
Do they all use the same tokenizer? (I mean, Mistral vs GPT)
No. Mistral uses sentencepiece and the GPT use tiktoken.
How did you reach the conclusion? Maybe they are counting on people paying extra just to prevent vendor lockdown.
The only vendor lock-in to GPT3.5 is the absence (perceived or real) of competitors at the same quality and availability.