Honest question: if they're only beating GPT 3.5 with their latest model (not GPT 4) and OpenAI/Google have infrastructure on tap and a huge distribution advantage via existing products - what chance do they stand?
How do people see things going in the future?
{kind=link}
1. This is an open source model that can run on people's hardware at a fraction of the cost of GPT. No cloud services in the middle.
2. This model is not censored as GPT.
3. This model has a lot less latency than GPT.
4. In their endpoint this model is called mistral-small. Probably they are training something much larger than can compete with GPT4.
5. This model can be fine tuned.
how does this work in their favor as a business? Don't get me wrong I love how all of it's free, but that doesn't seem to be helpful towards a $2b valuation. At least WeWork charged for access
To Europe and France this is a most important strategic area of research, defense, and industry—-on par with aviation and electronics. The EU recognizes its relatively slow pace compared to what is happening in the US and China.
Consider Mistral like a proto-Airbus.
Aren't they mostly funded by private American funds? what is EU involvement in this projet?
Mistral is funded in part by Lightspeed Venture Partners a US VP. But there are a lot of local French and European VPs involved.
The most famous one is Xavier Niel, who started Free/Iliad a French ISP/cloud provider and later cellphone provider that literally decimated the pricing structure of the incumbent some 20 years ago in France and still managed to make money. He’s a bit of a tech folk hero, kind of like Elon Musk was before Twitter. His company Iliad is also involved in providing access to NVIDIA compute clusters to local AI startups, playing the role Microsoft Azure plays for OpenAI.
France and the EU at large has missed the boat on tech, but they have a card to play here since they have for once both the expertise and the money rolled up. My main worry is that the EU legislation that’s in the works will be so dumb that only big US corporations will be able to work it out, and basically the legislation will scare investment away from the EU. But since the French government is involved and the guy who is writing the awful AI law is a French nominee, there’s a bit of hope.
They also have the EU protectionism card which is pretty safe to assume they will play for Mistral and the Germans (Aleph Alpha) - and thus also for Meta (for the most part). Iirc the current legislation basically makes large scale exceptions for open source models.
Nobody is better at innovating in protectionism than the EU. EU MEPs work hard to come up with new ways of picking winners.
Given how much consumer protectionism Americans and others have thanks to the EU's domestic protectionism, it is certainly a mixed bag at worst.
In a strange way it's almost akin to how soviet propaganda in the cold war played a role in spurring on the civil rights movement in the states.
european engineers, french vc money.... etc :/
Exactly. EU's VC situation is dire compared to SV, which maybe isn't that bad if you think about what the VCs are actually after, but in this particular case it's a matter of national security of all EU countries. The capability must be there.
Many VC funded businesses do not have an initial business model involving direct monetization.
The first step is probably gaining mindshare with free, open source models, and then they can extend into model training services, consultation for ML model construction, and paid access to proprietary models, similar to OpenAI.
Even in the public markets this happens all the time, eg. Biotech, new battery chemistries, etc.
In trends people pay for a seat at the table with a good team and worry about the details later. The 2B headline number is a distraction.
They could charge for tuning/support, just like every other Open Source company.
Most business will want their models trained in their own, internal data, instead of risking uploading their Intellectual Property into SaaS solutions. These Open Source models could fill that gap.
Maybe they will charge for accessing the future Mixtral 8x70B ...
Because their larger models are super powerful. This makes sure their models start becoming the norm from the bottom up.
It also solidifies their name as the best, above all others. That's extremely important mindshare. You need mindshare at the foundation to build a billion dollar revenue startup.
They launched an inference API
https://mistral.ai/news/la-plateforme/
* Open source models: give you all the attention (pun intended) you can get, away from OpenAI. At the same time do a great service to the world.
* Maybe in the future, bigger closed models? Make money with the state-of-art of what you can provide.
They are withholding a bigger model which at this point is "Mistral Medium" and that'll be available only behind their API end point. Makes sense for them to make money from it!
Notes poster ID
That seems a fairly authoritative response.
I'm looking forward to seeing how this does. The "unencumbered by a network connection" thing is pretty important.
I agree with what antirez said, but I want to address the fallacy: The fact that he's an authority in C doesn't make him a priori more likely to know a lot about ML.
Not just C. He's obviously damn good at architecture and systems design, as well as long-term planning.
You don't get that from a box of Cracker Jacks.
Right, but the fact remains that none of those things is ML.
Fair 'nuff. Not worth arguing over.
To be clear, I'm not saying antirez is or isn't good at ML, I'm saying C/systems design/etc experience doesn't automatically make someone good at ML. I'm not trying to argue, I'm just discussing.
Oh, it's not a big deal. I just hate talking about the chap in front of him. I like to give compliments specifically, and be vague about less-than-complimentary things.
The thing is, even the ML people are not exactly sure what's going on, under the hood. It's a very new field, with a ton of "Here, there be dragonnes" stuff. I feel that folks with a good grasp of long-term architectural experience, are a good bet; even if their experience is not precisely on topic.
I don't know how to do almost every project I start. I write about that, here: https://littlegreenviper.com/miscellany/thats-not-what-ships...
That's true, but I see my friend who's an ML researcher, and his grasp of LLMs is an order of magnitude better than mine. Granted, when it comes to making a product out of it, I'm in a much better position, but for specific knowledge about how they work, their capabilities, etc, there's no contest.
I agree with you, stavros. There is no transfer between C coding and ML topics. However the original question is a bit more in the business side IMHO. Anyway: I've some experience with machine learning: 20 years ago I wrote (my first neural network)[https://github.com/antirez/nn-2003] and since then I always stayed in the loop. Not for work, as I specialized in system programming, but for personal research I played with NN images compression, NLP tasks and convnets. In more recent times I use pytorch for my stuff, LLM fine-tuning and I'm a "local LLMs" enthusiast. I speculated a lot about AI, and wrote a novel about this topic. So while the question was more in the business side, I have some competence in the general field of ML. More than anything else I believe that all this is so new and fast-moving that there are many unknown unknowns, so indeed what I, you or others are saying are mere speculations. However to speculate is useful in this time, even more than before, because LLMs are a bit of a black box for the most part, so using only "known" things we can't go much far in our reasoning. We can understand embeddings, attention, how this networks are trained and fine tuned, and yet the inner workings are a bit of a magic thing.
I agree, and I want to reiterate that I wasn't talking about you specifically, just that people should be careful of the halo effect.
I also do agree that to speculate is useful when it's so early on. , and I agree with your original answer as well.
This is not a fallacy, we are engaging in informal reasoning, and contra your claim the fact that he is an authority in C does make it more likely he knows a lot about ML than the typical person.
Mistral and its hybrids are a lot better than GPT3.5, and while not as good as GPT4 in general tasks - they’re extremely fast and powerful with specific tasks. In the time it takes GPT4 to apologise that it’s not allowed to do something I can be three iterations deep getting highly targeted responses from mistral - and best yet - I can run it 100% offline, locally and on my laptop.
There is an attempt to quantify subjective evaluation of models here[1] - the "Arena Elo rating". According to popular vote, Mistral chat is nowhere near GPT 3.5
[1] https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboar...
Starling-7B, OpenChat, OpenHermes in that table are Mistral-7B finetunes, and are all above the current GPT-3.5-Turbo (1106). Note how these tiny 7B models are surrounded by much larger ones.
Mixtral 8x7B is not in there yet.
Not my intent to argue about data at any point in time but note that as of today gpt-3.5-turbo-0613 (June 13th 2023) scores 1112, above OpenChat (1075) and OpenHermes(1077).
That's not much relative difference. How much does 1% difference make?
I am tempted to call it equivalent.
nah that is sizeable
I guess one thing people have learned is that these small differences whatever benchmark turn out to be huge differences qualitatively.
ELO takes a while to establish. It does not sound likely that the newer GPT3.5 is that much worse than the old one that has a clear gap to all the non proprietary models. In the immediate test, GPT-3.5 clearly outshines these models.
I disagree - lmsys score for new chatgpt has been relatively constant, and OAI is probably trying to distill the model even further.
> ELO takes a while to establish.
Well, Starling-7B was published two weeks ago; GPT-3.5-turbo-0613 is more than a month old snapshot, which should probably be enough time. OpenChat and OpenHermes are about a month old as well.
>It does not sound likely that the newer GPT3.5 is that much worse than the old one
In fact, this version received complaints almost immediately. https://community.openai.com/t/496732
>In the immediate test, GPT-3.5 clearly outshines these models.
It might be so, but it's not clear to me at all. I tested Starling for a bit and was really surprised that it's a 7B model, not a 70B+ one or GPT-3.5.
Doesn't seem like that's the mixture of experts model in the list? Or am I blind
Indeed, that is a previous Mistral model.
Are they a lot better than 3.5? I see wildly varying opinions.
They could be.
It is an open question whether the driving force will be OSS improving or OAI continuing to try to distill their model.
Mistral-Medium, the one announced here which beats GPT-3.5 on every benchmark, isn't even available yet. Those opinions are referencing Mistral-Tiny (aka Mistral-7B).
However, Mistral-Tiny beats the latest GPT-3.5 in human ratings on the chatbot-arena-leaderboard, in the form of OpenHermes-2.5-Mistral-7B.
Mixtral 8x7B aka (Mistral-Small) was released a couple of days ago and will likely come close to GPT-4, and well above GPT-3.5, on the leaderboards once it has gone through some finetuning.
What laptop are you using to run which model, and what are you using for that?
M2 MacBook Pro, I run man different models but mistral, zephyr, deepseek. I use Ollama and LM Studio.
The easiest way is to use ollama - mistral 7b, zephyr 7b, openhermes 2 are all decent models, I guess in fact openhermes 2 can do function calling.
If you further want a smaller one, stablelm-zephyr 3b is a good attempt with ollama.
I was going to ask about this. So these open models are uncensored and unconstrained?
They are not better than GPT 3.5 except for some of the public benchmarks. Also they are not faster than GPT 3.5. And they are not cheaper if you run finetuned model for specific task.
Bit of a stretch to say they're a lot better when you look at evals
Perhaps they’re hoping some enterprises will be willing to pay extra for a 3.5 grade model that can run on prem?
A niche market but I can imagine some demand there.
Biggest challenge would be Llama models.
Niche market?? You have no idea how big that market is!
Almost no serious user - private or company - wants to slurp their private data to cloud providers. Sometimes it is ethically or contractually impossible.
The success of AWS and Gmail and Google docs and Azure and Github and Cloudflare make me think this... probably not an up-to-date opinion.
By and large, companies actually seem perfectly happy to hand pretty much all their private data over to cloud providers.
yet they don't provide access to their children, there may be something in that.
We can't use LLMs at work at all right now because of IP leakage, copyright, and regulatory concerns. Hosting locally would solve one of those issues for us.
Yeah I would venture to say it’s closer to “the majority of the market” than “niche”
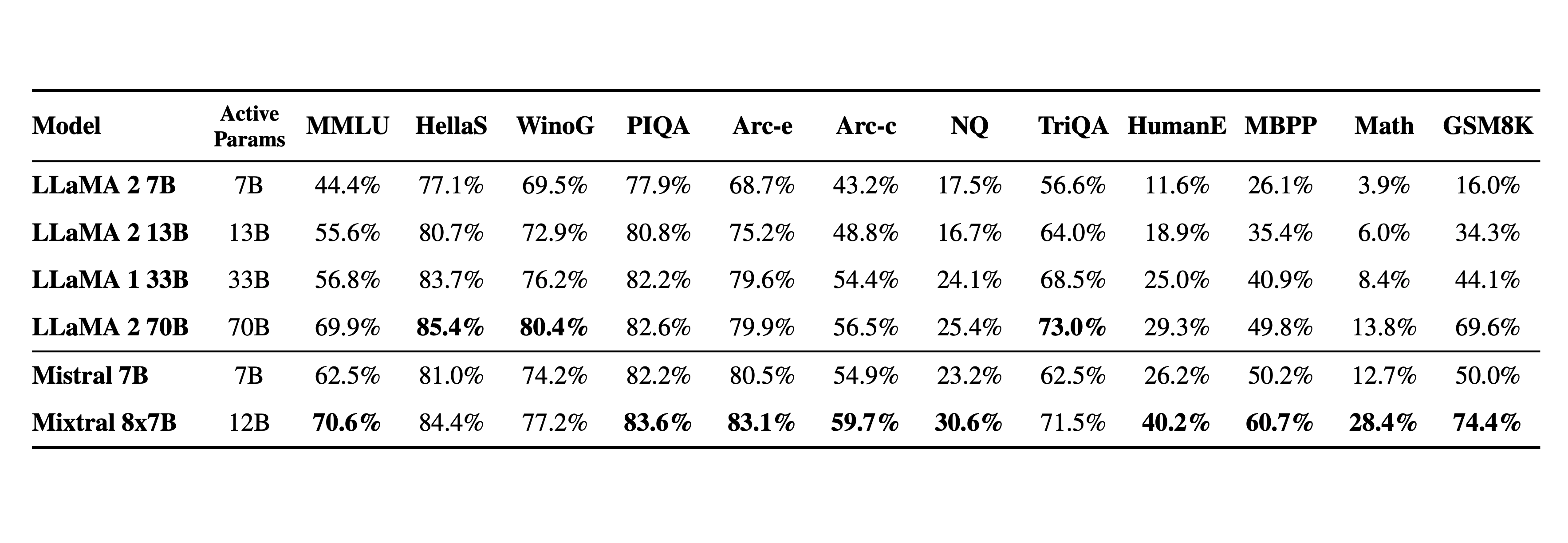
and according to the article this model behaves like a 12B model in terms of speed and cost while matching or outperforming Llama 2 70B in output
In terms of speed per token. What they don't say explicitly is that choosing the mix per token means you may need to reload the active model multiple times in a single sentence. If you don't have memory available for all the experts at the same time, that's a lot of memory swapping time.
If your motivation is to be able to run the model on-prem, with parallelism for API service throughput (rather than on a single device), you don't need large memory GPUs or intensive memory swapping.
You can architect it as cheaper, low-memory GPUs, one expert submodel per GPU, transferring state over the network between the GPUs for each token. They run in parallel by overlapping API calls (and in future by other model architecture changes).
Th MoE model reduces inter-GPU communication requirements for splitting the model, in an addition to reducing GPU processing requirements, compared with a non-MoE model with the same number of weights. There are pros and cons to this splitting, but you can see the general trend.
Tim Dettmers stated that he thinks this one could be compressed down to a 4GB memory footprint, due to the ability of MoE layers to be sparsified with almost no loss of quality.
The EU and other European governments will throw absolute boatloads of money at Mistral, even if that only keeps them at a level on par with the last generation. AI is too big of a technological leap for the bloc to ride America's coattails on.
Mistral doesn't just exist to make competitive AI products, it's an existential issue for Europe that someone on the continent is near the vanguard on this tech, and as such, they'll get enormous support.
You are vastly overestimating both the EU's budget and the willingness of countries to throw money at other countries' companies
I doubt mistral will get any direct EU funding
EU is good at fostering free market, but not at funding strategic efforts. Some people (Piketty, Stiglitz) say that companies like Airbus couldn't emerge today for that reason.
Uuuuuh... you could call the EU a lot of things, but "fostering free market" is a hot take. I'm sorry. When you look at the amount of regulation the EU brings to the table (EU basically is the poster child of market regulation), I would go as far as to say that your claim is objectively not true. We can debate how regulation is a good thing because this and that, but regulation - by definition - limits the free market. And there is an argument to be made, backed up literally thousands of regulations the EU has come up with, that the EU limits the free market a lot. When you factor in the regulations that are imposed on its member countries (I mean directly on the goverments) one could easily claim that it is the most harsh regulator on the planet. I could go into detail about the so called green deal, etc. but all of these things are easy to look up on the net / or official sources from the EU portal.
Not always true.
Consumer labeling laws enable the free market, because a free market requires participates have full knowledge of the goods they are buying, or else fair competition cannot exist.
If two companies are competing to sell wool coats, and one company is actually selling a 50% wool blend but advertising it as 100% wool, that is not a free market, that is fraud. Regulation exists to ensure that companies selling real wool coats are competing with each other, and that companies selling wool blends are competing with each other, and that consumers can choose which product that they want to buy without being tricked.
Without labeling laws, consumers end up assuming a certain % of fraud will always happen, which reduces the price they are willing to pay for goods, which then distorts the market.
The argument that the EU is a more harsh regulator than Iran, Russia, China, North Korea, (or even on par with those regulatory regimes) entirely undermines the rest of your comment.
There's pretty well tested and highly respected indexes which fundamentally disagree. Of the 7 most economically free nations, three are in the EU, and a fourth is automatically party to the majority of the EU's economic regulations.
https://en.wikipedia.org/wiki/List_of_sovereign_states_by_ec...
In the Index of Economic Freedom, more than a dozen EU member nations outperform the United States with regards to Economic Freedoms.
We'll see what comes out of ALTEDIC - https://ec.europa.eu/newsroom/lds/items/797961/en
Pretty much as with OSS in general: Lagging behind the cutting edge in terms of functionality/ux/performance, in areas where and as long as big tech is feeling combative, but eventually, probably, good enough across all axis to be useable.
There could be a close-ish future where OpenAI tech will simply solve most business problems and there is no need for anything dramatically better in terms of AI tech. Think of word/google docs: It's doing what most businesses need well enough. For the most part people are not longing for anything else and happy with it just staying familiar. This is where Open Source can catch up relatively easily.
Are you seriously claiming most oss is irrelevant? Maybe in consumer facing products such as libre office. But oss powers most of commercial products. I wouldn't be surprised if most functionality in all of current software is built from a thin layer over open source software.
No
That's not how I feel about OSS - from Operating Systems, to Databases, to Browsers, to IDEs, to tools like Blender etc.
Of course there are certain areas where Commercial offerings are better, but can't generalize.
Oh well, it's an evaluation, but I feel you may have glossed over the "in areas where and as long as big tech is feeling combative" part.
"Tools like" needs a little more content to not be filled massive amounts of magical OSS thinking. Blender has in recent years gained an interesting amount of pro-adoption, but, in general, as for the industries that I have good insight into, inkscape, gimp, ardour or penpot are not winning. This is mostly debated by people who are not actually mainly and professionally using these tools.
There are exceptions, of course (nextcloud might be used over google workspace when compliance is critical) but businesses will on average use the best tool, because the perceived value is still high enough and the cost is not, specificially when contrasted with labor cost and training someone to use a different tool.
You could broadly segregate the market into three groups - general purpose, specialized-instructions, and local tasks.
For general purpose, look at the uses of GPT4. Gemini might give them competition lately, and I dont think OSS would in the near future. They are trained on open internet and are going to be excellent at various tasks like answering basic questions, coding, generating content for marketing or website. Where they do badly is when you introduce a totally new concept which is likely outside of their training data. Dont think mistral is even trying to compete with them.
local tasks is a mix of automation and machine level tasks. A small mistral like model would work superbly well because it does not require as much expertise. Usecases like locating a file by semantic search, generating answers to reply to email/text within context, summarize a webpage.
Specialized instructions though is key for OSS. From two angles. One is security and compliance. Open AI uses a huge system prompt to get their model to perform in a particular manner, and for different companies, policies and compliance requirements may result in a specific system prompt for guardrails. This is ever changing and better to have an open source model that can be customized than depending on Open AI. From the blog post.
I think moderation is one such issue. Could be many and it is an evolving space as we go forward. (though this is likely to be an exposed functionality in future Open AI models). There is also the data governance bit - which is easier to do with an oss model than just depending on Open AI apis, just architectural reasons.
The second is training a model on domain knowledge of the company. We at Clio AI[1] (sorry, shameless plug) have had seven requests in the last one month about companies wanting their own private models pretrained on their own domain knowledge. These datasets are not on open internet and so no model is good at answering based them. A catalyst was Open AI dev day[2] which asked for proposals for custom models trained on enterprise domain knowledge. and their price start at $2M. Finetuning works, but on small datasets, not the bigger ones.
Large Companies are likely to approach Open AI and all these OSS models to train a custom instruction following model. Cos there are a handful of people who have done it, and that is the way they can get most out of a LLM deployment.
[1]: https://www.clioapp.ai/custom-llm-model Sorry for the shameless plug. Still working on website so it wont be as clear. [2]:https://openai.com/form/custom-models
Are you actually fine tuning or using RAG? So far I am able to get very good results with llamaindex, but fine tuning output just looks like the right format without much of the correct information.
Not using RAG, and using Supervised Finetuning post pre-training. It's taking all of the corporate data and pretraining a foundational model further with that extra tokens. Then SFT. Problem with usual finetuning is that it gets the format right, but struggles when the domain knowledge is not in the model's original training. Think of it as creating a vertical LLM that is unique to an organization.
Are you using a normal training script i.e. "continued pretraining" on ALL parameters with just document fragments rather than input output pairs? And then after that you fine tune on a standard instruct dataset, or do you make a custom dataset that has qa pairs about that particular knowledgebase? When you say SFT I assume you mean SFTTrainer. So full training (continued from base checkpoint) on the document text initially and then LoRA for the fine tune?
I have a client that has had me doing LoRA with raw document text (no prepared dataset) for weeks. I keep telling him that this is not working and everyone says it doesn't work. He seems uninterested in doing the normal continued pretraining (non-PEFT, full training).
I just need to scrape by and make a living though and since I don't have a savings buffer, I just keep trying to do what I am asked. At least I am getting practice with LoRAs.
Yes, this one.
This one. Once you have a checkpoint w knowledge, it makes sense to finetune. You can use either LORA or PEFT. We do it depending on the case. (some orgs have like millions of tokens and i am not that confident that PEFT).
LoRA with raw document text may not work, haven't tried that. Google has a good example of training scripts here: https://github.com/google-research/t5x (under training. and then finetuning). I like this one. Facebook Research also has a few on their repo.
If you are just looking to scrape by, I would suggest just do what they tell you to do. You can offer suggestions, but better let them take the call. A lot of fluff, a lot of chatter online, so everyone is figuring out stuff.
They might be willing to do things like crawl libgen which google possibly isn't, giving them an advantage. They might be more skilled at generating useful synthetic data which is a bit of an art and subject to taste, which other competitors might not be as good at.
Are you implying big companies don't crawl libgen? Or google specifically? I would be very surprised if OpenAI (MS) didn't crawl libgen.
OpenAI probably does. Not sure about google, possibly not
Google has a ton of scanned books and magazines from libraries etc, on top of their own web crawls. If they don't have the equivalent of libgen tucked away something's gone wrong.
The demand for using AI models for whatever is going through the roof. Right now it's mostly people typing things manually in chat gpt, bard, or wherever. But that's not going to stay like that. Models being queried as part of all sorts of services is going to be a thing. The problem with this is that running these models at scale is still really expensive.
So, instead of using the best possible model at any cost for absolutely everything, the game is actually good enough models that can run cheaply at scale that do a particular job. Not everything is going to require models trained on the accumulated volume of human knowledge on the internet. It's overkill for a lot of use cases.
Model runtime cost is a showstopper for a lot of use cases. I saw a nice demo of a big ecommerce company in Berlin that had built a nice integration with openai's APIs to provide a shopping assistent. Great demo. Then somebody asked them when this was launching. And the answer was that token cost was prohibitively expensive. It just doesn't make any sense until that comes down a few orders of magnitudes. Companies this size already have quite sizable budgets that they use on AI model training and inference.
If possible, please share, how was the shopping assistant helping out a consumer in the buying process? What were the features?
Features I saw demoed were about comparing products based on descriptions, images, and pricing. So, it was able to find products based on a question that was about something suitable for X costing less than Y where X can be some kind of situation or event. Or find me things similar to this but more like so. And so on.
I can agree with this, I’m currently building a system that pulls data from a series of pdfs that are semi-structured. Just testing alone is taking up 10s of $ in api costs. We have 60k PDFs to do.
I can’t deliver a system to a client that costs more in api costs than it does in development costs for their expected input size.
Using the most naive approach the ai would be beaten on a cost basis by a mechanical Turk.
Microsoft, Apple, and Google also have more resources at their disposal yet Linux is doing just fine (to put it mildly). As long as Mistral delivers something unique, they'll be fine.
Linux is funded by big tech companies. IBM probably put a billion into Linux and that was 20 years ago now.
This wasn’t status quo. In fact, it can serve as an example. Why wouldn’t google or microsoft follow the same path with mistral? Being open source, it serves their purposes well.
I'd look at Facebook more than Google.
Also, considering mistral is open source, what will prevent their competitor to integrate any innovation they make?
Another thing I don't understand, how a 20 people company can provide a similar system as OpenAI (1000 employees)? what do they do themselves, and what do they re-use?
Companies move slow, especially as they get bigger. Just because a google engineer wants to yoink some open source inferencing innovation for example, doesn't mean they can just jam it into Gemini and have it rolled out immediately.
Their small and tiny models are open source, it seems like a marketing strategy, and bigger models will not be open source. Their medium model is not open source.
They do not provide the scale of OpenAI or a model comparable to GPT-4 (yet).
As I read it they are doing this with 8 * 7Bn parameter models. So, their model should run pretty well as fast as a 7Bn model and at the cost of a 56bn parameter model.
That a lot quicker and cheaper than GPT-4
Also this is kinda a promissory note, they've been able to do this in a few months and create a service on top of it. Does this intimate that they have the capability to create and run SoA models? Possibly. If I were a VC I could see a few ways for this bet to go well.
The big killer is moat - maybe this just demonstrates that there is no LLM moat.
Inference should be closer to llama 13b, since it runs 2/8 experts for each token.
Does it have to run them sequentially? I guess the cost will be 12/13bn level but latency may be faster?
Compete on price (open-source model, cheap hosted inference) probably?
Also, they are probably well-placed to answer some proposals from European governments, who won't want to depend on US-companies too much.
That's true but I wonder how they stack up against Aleph Alpha and Kyutai? Genuinely curious as I haven't found a lot of concrete info on their offerings.
1) as a developer or founder looking to experiment quickly and cheaply with llm ideas, this (and llama etc) are huge gifts
2) for the research community, making this work available helps everyone (even OpenAI and Google, insofar as they've done something not yet tried at those larger orgs)
3) Mistral is well positioned to get money from investors or as consultants for large companies looking to fine tune or build models for super custom use cases
The world is big and there's plenty of room for everyone!! Google and OpenAI haven't tried all permutations of research ideas - most researchers at the cutting edge have dozens of ideas they still want to try, so having smaller orgs trying things at smaller scales is really great for pushing the frontier!
Of course it's always possible that some major tech co playing from behind (ahem, apple) might acquire some LLM expertise too
a lot of wordy answers to this but all you need to do is read the blog post to the end and notice this line:
emphasis on the name of the endpoint
A niche thing that thrives in its own niche. Just like most open source apps without big corperations behind them.
They are focusing hard on small models. Sooner or later, you'll be able to run their product offline, even on mobile devices.
Google was criticized [0] for offloading pretty much all generative AI tasks onto the cloud - instead of running it on the Tensor G3 built into its Pixel Phones specifically for that purpose. The reason being, of course, that the Tensor G3 is much to small for almost all modern generative models.
So Mistral is focusing specifically on an area the big players are failing right now.
[0] https://news.ycombinator.com/item?id=37966569
Another advantage over Google or OpenAI for me would be that it is not from Google or OpenAI
If you're purely looking for capabilities and not especially interested in running an open model, this might not be that interesting. But even so, this positions Mistral as currently the most promising company in the open models camp, having released the first thing that not only competes well with GPT-3.5 but also competes with other open models like Llama-2 on cost/performance and presents the most technological innovation in the open models space so far. Now that they raised $400MM the question to ask is - what happens if they continue innovating and scale their next model sufficiently to compete with GPT-4 / Gemini? The prospects have never seemed better than they do today after this release.
You do understand that you cant run GPT4 on your own right?
Google BARD/AI isn’t available in Canada or the EU, so there’s one big competitive advantage.
OpenAI is of course the big incumbent to beat and is in those markets.
They only started this year, so beating ChatGPT3.5 is I think a great milestone for 6 months of work.
Plus they will get a strategic investment as the EU’s answer to AI, which may become incredibly valuable to control and regulate.
Edit: I fact checked myself and bard is available in the EU, I was working off outdated information.
https://support.google.com/bard/answer/13575153?hl=en
Beyond what others said, I think this is an extremely impressive showing. Consider that their efforts started years behind Google's, and yet their relatively small model (they call is mistral-small, and also offer mistral-medium) is beating or on par with Gemini Pro on many benchmarks (Google's best currently available model).
On top of that Mixtral is truly open source (Apache 2.0), and extremely easy to self host or run on a cloud provider of your choice -- this unlocks many possibilities, and will definitely attract some business customers.
EDIT: The just announced mistral-medium (larger version of the just open sourced mixtral 8x7b) is beating GPT3.5 with significant margin, and also Gemini Pro (on available benchmarks).
AI based on LLMs comes with several sets of inherent trade-offs, as such I don't predict that one winner will take all.
Google started late with any serious LLM effort. It takes time to iterate on something so complex and slow to train. I expect Google will match OpenAI in next iteration or two, or at worst stay one step behind, but it takes time.
OTOH Google seem to be the Xerox Parc of our time (who were famous for state of the art research and failure to productize). Microsoft, and hence Microsoft-OpenAI, seem much better positioned to actually benefit from this type of generative AI.