A lot of transformer explanations fail to mention what makes self attention so powerful.
Unlike traditional neural networks with fixed weights, self-attention layers adaptively weight connections between inputs based on context. This allows transformers to accomplish in a single layer what would take traditional networks multiple layers.
{kind=link}
None of this seems obvious just reading the original Attention is all you need paper. Is there a more in-depth explanation of how this adaptive weighting works?
I found these notes very useful. They also contain a nice summary of how LLMs/transformers work. It doesn't help that people can't seem to help taking a concept that has been around for decades (kernel smoothing) and giving it a fancy new name (attention).
http://bactra.org/notebooks/nn-attention-and-transformers.ht...
It's just as bad a "convolutional neural networks" instead of "images being scaled down"
“Convolution” is a pretty well established word for taking an operation and applying it sliding-window-style across a signal. Convnets are basically just a bunch of Hough transforms with learned convolution kernels.
It’s definitely not obvious no matter how smart you are! The common metaphor used is it’s like a conversation.
Imagine you read one comment in some forum, posted in a long conversation thread. It wouldn’t be obvious what’s going on unless you read more of the thread right?
A single paper is like a single comment, in a thread that goes on for years and years.
For example, why don’t papers explain what tokens/vectors/embedding layers are? Well, they did already, except that comment in the thread came 2013 with the word2vec paper!
You might think wth? To keep up with this some one would have to spend a huge part of their time just reading papers. So yeah that’s kind of what researchers do.
The alternative is to try to find where people have distilled down the important information or summarized it. That’s where books/blogs/youtube etc come in.
Is there a way of finding interesting "chains" of such papers, short of scanning the references / "cited by" page?
(For example, Google Scholar lists 98797 citations for Attention is all you need!)
As a prerequisite to the attention paper? One to check out is:
A Survey on Contextual Embeddings https://arxiv.org/abs/2003.07278
Embeddings are sort of what all this stuff is built on so it should help demystify the newer papers (it’s actually newer than the attention paper but a better overview than starting with the older word2vec paper).
Then after the attention paper an important one is:
Language Models are Few-Shot Learners https://arxiv.org/abs/2005.14165
I’m intentionally trying to not give a big list because they’re so time-consuming. I’m sure you’ll quickly branch out based on your interests.
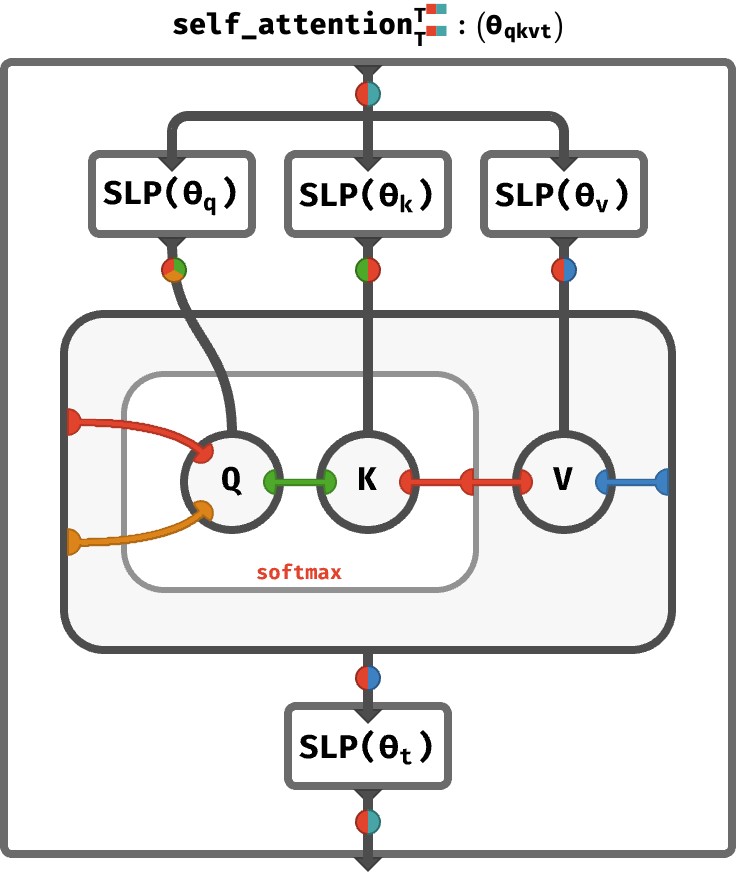
softmax(QK) gives you a probability matrix of shape [seq, seq]. Think of this like an adjacency matrix with edges with flow weights that are probabilities. Hence semantic routing of parts of X reduced with V.
where
- Q = X @ W_Q [query]
- K = X @ W_K [key]
- V = X @ V [value]
- X [input]
hence
attn_head_i = (softmax(Q@K/normalizing term) @ V)
Each head corresponds to a different concurrent routing system
The transformer just adds normalization and mlp feature learning parts around that.
I struggled to get an intuition for this, but on another HN thread earlier this year saw the recommendation for Sebastian Raschka's series. Starting with this video: https://www.youtube.com/watch?v=mDZil99CtSU and maybe the next three or four. It was really helpful to get a sense of the original 2014 concept of attention which is easier to understand but less powerful (https://arxiv.org/abs/1409.0473), and then how it gets powerful with the more modern notion of attention. So if you have a reasonable intuition for "regular" ANNs I think this is a great place to start.
Turns out Attention is all you need isn't all you need!
(I'm sorry)
The audience of this paper are other researchers who already know the concept of attention, which was very well known already in the field. In such research papers, such things are never explained again, as all the researchers already know this or can read other sources, which are cited, but focus on the actual research questions. In this case, the research question was simply: Can we get away by just using attention and not using the LSTM anymore? Before that, everyone was using both together.
I think learning it following it more this historical development can be helpful. E.g. in this case here, learn the concept of attention, specifically cross attention first. And that is this paper: Bahdanau, Cho, Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", 2014, https://arxiv.org/abs/1409.0473
That paper introduces it. But even that is maybe quite dense, and to really grasp it, it helps to reimplement those things.
It's always dense, because those papers already have space constraints given by the conferences, max 9 pages or so. To get a better detailed overview, you can study the authors code, or other resources. There is a lot now about those topics, whole books, etc.
In case it’s confusing for anyone to see “weight” as a verb and a noun so close together, there are indeed two different things going on:
1. There are the model weights, aka the parameters. These are what get adjusted during training to do the learning part. They always exist.
2. There are attention weights. These are part of the transformer architecture and they “weight” the context of the input. They are ephemeral. Used and discarded. Don’t always exist.
They are both typically 32-bit floats in case you’re curious but still different concepts.
I always thought the verb was "weigh" not "weight", but apparently the latter is also in the dictionary as a verb.
Oh well... it seems like it's more confusing than I thought https://www.merriam-webster.com/wordplay/when-to-use-weigh-a...
“To weight” is to assign a weight (e.g., to weight variables differently in a model), whereas “to weigh” is to observe and/or record a weight (as a scale does).
A few other cases of this sort of thing:
affect (n). an emotion or feeling. "She has a positive affect."
effect (n). a result or change due to some event. "The effect of her affect is to make people like her."
affect (v). to change or modify [X], have an effect upon [X]. "The weather affects my affect."
effect (v). to bring about [X] or cause [X] to happen. "Our protests are designed to effect change."
Also:
cost (v). to require a payment or loss of [X]. "That apple will cost $5." Past tense cost: "That apple cost $5."
cost (v). to estimate the price of [X]. "The accounting department will cost the construction project at $5 million." Past tense costed. "The accounting department costed the construction project at $5 million."
I think in most deployments, they're not fp32 by the time you're doing inference no them, they've been quantized, possibly down to 4 bits or even fewer.
On the training side I wouldn't be surprised if they were bf16 rather than fp32.
I think a good way of explaining #2 is “weight” in the sense of a weighted average
Just to add on, a good way to learn these terms is to look at the history of neural networks rather than looking at transformer architecture in a vacuum
This [1] post from 2021 goes over attention mechanisms as applied to RNN / LSTM networks. It's visual and goes into a bit more detail, and I've personally found RNN / LSTM networks easier to understand intuitively.
[1] https://medium.com/swlh/a-simple-overview-of-rnn-lstm-and-at...